Oracle数据库
- Oracle概述
- 数据库结构
- PL/SQL
- 数据库管理
- 执行计划
- Oracle 优化器
- 数据库优化
- 常见问题
- 备份与恢复
- 数据库集群技术
- 商业智能与数据仓库
- Oracle事务隔离级别
- 索引
- 锁
- 主从同步
Oracle概述
Oracle数据库自发布至今,也经历了一个从不稳定到稳定,从功能简单至强大的过程。从第二版开始,Oracle的每一次版本变迁,都具有里程碑意义。
1979年的夏季,RSI(Oracle公司的前身,Relational Software,Inc)发布了Oracle第二版。
1983年3月,RSI发布了Oracle第三版。从现在起Oracle产品有了一个关键的特性–可移植性。
1984年10月,Oracle(RSI更名为Oracle)发布了第4版产品。这一版增加了读一致性这个重要特性。
1985年,Oracle发布了5.0版。这个版本是Oracle数据库较为稳定的版本。并实现了C/S模式工作。
1986年,Oracle发布了5.1版。该版本开始支持分布式查询。
1988年,Oracle发布了第6版。该版本中引入了行级锁特性,同时还引入了联机热备份功能。
1992年6月,Oracle发布了第7版。该版本增加了包括分布式事务处理功能、用于应用程序开发的新工具及安全性方法等功能。
1997年6月,Oracle第8版发布。Oracle8支持面向对象的开发及新的多媒体应用。
1998年9月,Oracle公司正式发布Oracle 8i。正是因为该版本对Internet的支持,所以,在版本号之后,添加了标识i。
2001年6月,Oracle发布了Oracle 9i。
2003年9月,Oracle发布了Oracle 10g。这一版的最大特性就是加入了网格计算的功能,因此版本号之后的标识使用了字母g,代表Grid–网格。
2007年7月11日,Oracle发布了Oracle 11g。Oracle 11g实现了信息生命周期管(Information Lifecycle Management)等多项创新。Oracle的最新版本为Oracle 11g
2009年9月, Oracle发布了11g R2, 可在 0 到“n”秒内配置备用查询 SLA, 自动块修复, 针对带宽有限的 WAN 传输redo压缩内容, 不仅仅用于在传播中断之后resolving redo gaps。
2013年6月, Oracle 6年磨一剑, 开始提供Oracle 12c的下载. 甲骨文官方宣称Oracle Database 12c包含了500多项功能改进。其中最受关注且讨论最多的一项功能就是可插拔数据库(Pluggable Database),毫无疑问它将重新定义数据库虚拟化技术,宣称为云时代的数据库。
Oracle 9i比8i多了哪些新特性?
简要说:9i更易于管理。
详细说:并发集群,8i OPS升级为9i RAC,8i结点间用硬盘交换信息,9i结点间采用高速网线的缓存熔合(Cache Fusion)技术交换信息,交换速度提高100倍以上, 9i可以在线修改内核参数和内存分配,8i不行。
数据文件和表空间管理,8i手工管理,9i自动管理。
9i比8i增强了对ANSI SQL99的支持。
9i比8i增强了故障后的快速恢复(Fast-start)。
8i只支持物理备份(physical backup)数据库,9i还增加了支持逻辑备份(logical backup)数据库,使备份数据库除了作为主数据库的镜像外,还可以提供其他数据服务。
Oracle 10g比9i多了哪些新特性?
简要说: 10g支持网格(Grid),支持自动管理(Automatic Management)。
详细说: 10g的g是”Grid”缩写,支持网格计算,即,多台结点服务器利用高速网络组成一个虚拟的高性能服务器,负载在整个网格中均衡(Load Balance),按需增删结点,避免单点故障(Single Point of Faliure)。
安装容易,安装工作量比9i减少了一半。
新增基于浏览器的企业管理器(Enterprise Manager)。
自动存储管理(ASM),增删硬盘不再需要操作系统管理员设置的镜像、负载均衡、物理卷、逻辑卷、分区、文件系统,只要打一条Oracle命令,ASM会自动管理增加或删除的硬盘。 内存自动化,根据需要自动分配和释放系统内存。
SQL性能调整自动化。 免费提供基于浏览器的小应用开发工具Oracle Application Express(原名HTML DB),支持10g和9i R2。
快速纠正人为错误的闪回(Flashback)查询和恢复,可以恢复数据库、表甚至记录。数据泵(Data Pump)高速导入、导出数据,比传统方法导出速度快两倍以上,导入速度快15–45倍。 精细审计(Fine-Grained Auditing),记录一切对敏感数据的操作。
存储数据的表空间(Tablespace)跨平台复制,极大的提高数据仓库加载速度。
流(Streams)复制,实现低系统消耗、双向(double-direction)、断点续传(resume from break point)、跨平台(cross platform)、跨数据源的复杂复制。
容灾的数据卫士(Data Guard)增加了逻辑备份功能,备份数据库日常可以运行于只读状态,充分利用备份数据库。
支持许多新EE选件,加强数据库内部管理的“Database Vault”,数据库活动的审计的(Audit Vault),数据仓库构建高级功能(Warehouse Builder Enterprise ETL, Warehouse Builder Data Quality).
Oracle 11g比10g多了哪些新特性?
11 g 扩展了 Oracle 独家具有的提供网格计算优势的功能,您可以利用它来提高用户服务水平、减少停机时间以及更加有效地利用 IT资源,同时还可以增强全天候业务应用程序的性能、可伸缩性和安全性。
利用真正应用测试(RAT)尽量降低更改的风险 11 g降低了数据库升级以及其他硬件和操作系统更改的成本,显著简化了更改前后的系统测试以便您可以识别和解决问题。
例如: 利用 Database Replay,您可以在数据库级别轻松捕获实际的生产负载并在您的测试系统上重新播放,这样您可以全面测试系统更改(包括关键的并发特性)的影响。
SQL Performance Analyzer识别结构化查询语言 ) SQL(执行计划更改和性能回退。
然后,可以使用 SQL Tuning Advisor解决识别的问题,方法是还原到原始的执行计划或进一步优化。
利用管理自动化提高 DBA 效率 Oracle 数据库 11 g继续致力于(从 Oracle9i数据库开始一直到 Oracle 数据库10 g)显著简化和完全自动化 DBA 任务。
Oracle数据库11 g中的新功能包括: 利用自学功能自动进行 SQL 优化系统全局区(SGA)和程序全局区( PGA)的内存缓存区的自动、统一调整新的 advisor用于分区、数据恢复、流性能和空间管理针对自动数据库诊断监视器 (ADDM)的增强,能够提供 Oracle 真正应用集群 (Oracle RAC)环境中的更好的性能全局视图以及改进的性能比较分析功能。
利用故障诊断快速解决问题 Oracle 数据库 11 g中新增的故障诊断功能使客户在发生错误后捕获 OracleSupport所需的数据变得极为简单。
这可以加速问题的解决,减少客户重现问题的需要。尽量降低停机成本通过 Oracle Data Guard快速恢复数据 Oracle Data Guard在本地和远程服务器之间协调数据库的维护和同步以便从灾难或站点故障快速恢复。
Oracle数据库11 g提供了大量显著的 Oracle Data Guard增强,包括 可以在物理备用系统上运行实时查询用于报表和其他目的 可以通过将物理备用系统暂时转换为逻辑备用系统执行联机的、滚动的数据库升级 ..支持测试环境的快照备用系统此外,物理和逻辑备用的性能都有提高。
逻辑备用现在支持可扩展标记语言(XML)类型字符大型对象 (CLOB)数据类型和透明的数据加密。
现在支持自动的、快速启动的故障切换以支持异步传输。Oracle 数据库 11 g提供了几个针对自动存储管理的重要的高可用性增强,包括: ..支持滚动升级 ..自动坏块检测和修复 ..快速镜像重新同步,该功能可以有效地重新同步存储网络连接性暂时丢失时自动存储管理镜像的存储阵列自动存储管理的性能增强使得大型数据库可以更快地打开并减少 SGA 内存消耗。这些增强还允许 DBA增加存储分配单元大小以加快大型序列输入/输出 (I/O)显著增加正常运行时间 Oracle数据库11 g使您可以应用很多一次性数据库补丁(包括诊断补丁),而没有停机时间。
新的数据恢复 advisor通过快速识别故障根本原因、为 DBA提供可用的恢复选项,极大地减少了停机时间,在某些情况下,还通过“自我恢复”机制自动纠正问题。
Oracle 数据库 11 g还有其他高性能提高,包括 ..自动编译数据库中的 PL/SQL 和 Java ..更快的触发器,包括更加有效地调用每行触发器 ..更快的简单 SQL 操作 ..更快的 Oracle Data Guard 和 Oracle Streams 复制 ..与网络文件系统( NFS) 存储设备更快、更可靠的直接连接 ..更快的升级 ..大型文件更快的备份/还原 ..更快的备份压缩Oracle 数据库 11 g包括大量新的 ILM特性,例如 ..新的分区功能,包括 .按父/子引用分区 .按虚拟列分区 Oracle数据库11 g还具有带 Oracle闪回数据归档的 Total Recall,使您可以在选定的表中查询以前的数据,从而提供了一种简单实用的向数据中添加时间维度的方法以便于更改跟踪、 ILM、审计和合规。
其他高可用性增强 Oracle 数据库 11g还有其他高可用性增强,包括: Oracle闪回事务查询,提供带其他相关事务更改的流氓事务的按钮更改 具有更多可传输选项的增强的平台移植和数据移动,包括可传输分区、模式和跨平台数据库 Oracle恢复管理器 (RMAN)支持 Windows Volume Shadow Copy Service ( VSS )快照,从而实现与 Windows备份更紧密的集成优化性能和可靠性合规、法律取证以及整合数据仓库的趋势导致数据库的大小每两年就会增加两倍,这极大地影响了大型数据库的存储成本和性能、可靠性以及可管理性。
Oracle 数据库 11 g使组织可以使用低成本的服务器和模块化的存储器轻松伸缩大型的事务和数据仓库系统并提供快速的全天候数据访问。 Oracle 数据库11 g提供新的创新特性以进一步提高要求极严格的环境的性能和可伸缩性。
利用 SecureFiles安全地存储您的所有数据 SecureFiles 是 Oracle用于在数据库中存储大型对象) LOB ((例如图像、大型文本对象或包括 XML、医学成像以及地理空间栅格对象在内的高级数据类型)的下一代产品。 SecureFiles提供能够完全与文件系统相媲美的卓越性能。
此外,它还提供高级功能,例如智能压缩、透明加密以及透明的重复删除。通过联机事务处理压缩提高性能并尽量降低存储成本 Oracle 数据库 11 g支持联机事务处理 (OLAP)应用程序中常用的更新、插入和删除操作的数据压缩。以前的 Oracle数据库版本支持数据仓库应用程序常用的批量数据加载操作的压缩。
Oracle 数据库 11 g OLTP表压缩通过更加高效地使用内存来缓存数据以及减少表扫描的 I/O提高了数据库性能。利用 OLTP表压缩,您可以利用最小的处理开销达到 2 到 3倍的压缩比。
Oracle 12c的一些重要特性和优势。
一、多租户架构(Multitenant Architecture)
多租户架构是Oracle 12c的一个重要特性,它允许在一个数据库实例中容纳多个的租户。
每个租户都有自己的数据和应用程序,但共享数据库实例的资源。
这种架构能够大大减少硬件和软件资源的需求,提高整体系统的可伸缩性和性能。
二、数据库内存管理
Oracle 12c引入了内存优化功能,包括自动内存管理和内存优化器。
自动内存管理功能可以动态调整数据库实例中各个组件的内存分配,以限度地提高性能。
内存优化器则可以自动识别并优化数据库中的内存使用,提高查询性能和响应时间。
三、数据压缩
Oracle 12c引入了一种新的数据压缩算法,称为Advanced Compression。
这种算法可以在保持数据完整性的同时,大幅度减少存储空间的使用。
它适用于各种类型的数据,包括表、索引、分区和备份数据。
使用数据压缩功能,企业可以显著降低存储成本,提高系统的性能和可扩展性。
四、高可用性和容错性
Oracle 12c提供了一系列的高可用性和容错性功能,确保数据库的持续运行和数据的安全性。
其中包括数据保护功能,如数据镜像、数据备份和恢复、故障转移和数据冗余。
此外,Oracle 12c还提供了自动化的故障检测和修复功能,可以快速恢复系统正常运行。
五、安全性
Oracle 12c提供了强大的安全性功能,保护企业的数据免受未经授权的访问和恶意攻击。
它包括访问控制、加密、审计和身份验证等功能。
此外,Oracle 12c还支持细粒度的安全策略,可以根据用户和角色设置不同的权限和访问控制规则。
六、云计算支持
Oracle 12c是一款云原生的数据库管理系统,提供了丰富的云计算支持。
它可以轻松部署在公有云、私有云或混合云环境中,并与其他云服务集成,如存储、计算和网络。
此外,Oracle 12c还提供了自动化的云管理功能,可以快速创建、配置和管理云资源。
结论:
Oracle 12c是一款功能强大、性能优越的数据库管理系统。
它提供了许多创新的功能和性能优化,包括多租户架构、数据库内存管理、数据压缩、高可用性和容错性、安全性和云计算支持等。
这些功能使得Oracle 12c成为企业级应用程序的数据库,并为企业提供了强大的数据管理和分析能力。
- Oracle 8i
1999年发布的Oracle 8i是一次重大的数据库技术革新,主要目的是提高了数据库的可用性、可扩展性和可管理性。在其引入了诸多新技术,如Java Stored Procedures、Oracle Java Virtual Machine、XML支持、事务处理等,为用户提供了更强大的业务处理和数据管理能力。
- Oracle 9i
2001年推出的Oracle 9i是以Internet为主题的版本,为企业用户提供了更好的全网应用支持。该版本增加了一些新的简化性能和提高可管理性的功能,同时增加了一些新的工具,如OEM(Oracle Enterprise Manager)等,为企业用户提供更强大的数据管理平台。
- Oracle 10g
2004年推出的Oracle 10g以Grid Computing为主题,引入了Oracle High Availability Architecture(HA),提供了更高的可靠性、可用性和可扩展性,方便企业进行数据管理和备份,保障了企业信息系统的安全和稳定。
- Oracle 11g
2007年推出的Oracle 11g是一个具有SQL、PL/SQL和Java语言混合编程的关系数据库。该版本引入了诸多的新技术,如AEP(Automated Enterprise Performance)自动监控功能,SQL Access Advisor集成等,具有更好的分析和优化数据库的性能的能力,为企业管理者提供了更好的决策支持。
- Oracle 12c
2013年推出的Oracle 12c是Oracle公司未来几年的未来展望的核心思路,引入了很多新技术,如CDB(Container Databases)容器数据库、Multitenant Architecture多租户体系结构等,更加强调云端计算以及大数据方面的支持。
- Oracle 18c
2018年发布的Oracle 18c是业界领先的自动化数据库,利用自主数据库技术为企业用户提供了更高的可用性和可扩展性。该版本具有一些新功能,如自主数据管理、自动升级和自动扩展等,提升了Oracle的资源利用率和性能效率,为用户带来更好的运维体验。
- Oracle 19c
2019年推出的Oracle 19c是当前最新的Oracle数据库版本,采用了Autonomous Database技术,强调数据库的自动化管理和自主运维。该版本具有很多新的功能,如自动索引创建、Flashback Pluggable Database、Database Replay等,便于企业用户提高数据处理效率和节约运维成本。
Docker
docker search Oracle
列表中不显示但是似乎能用,比较大有好几个G,因此下载比较慢:
docker pull truevoly/oracle-12c
查看下镜像下载成功了没:
docker images
挂载目录:
mkdir -p /data/oracle/data_temp && chmod 777 /data/oracle/data_temp
运行容器:
docker run –restart always -d -p 8080:8080 -p 1521:1521 -v /data/oracle/data_temp:/home/oracle/data_temp -v /etc/localtime:/etc/localtime:ro –name orcl truevoly/oracle-12c 会得到一个容器ID例如 3294ec3b81734afcb263c1b4577cf78f7df58cb5e4b8d4678eb0b6461c6da1e9
可以查看安装进程
doker logs -f 3294ec3b81734afcb263c1b4577cf78f7df58cb5e4b8d4678eb0b6461c6da1e9
docker ps 查看容器id 例如我查到的是:
3294ec3b8173
进入docker内部
docker exec -it 3294ec3b8173 sh (此处的bd就是上面ps查询出来的 CONTAINER:bd40cca054ad,这ID每个人查出来的都不一样,复制到前面即可。)
安装完成后就可以进如
可以用sqlplus测试:
sqlplus system/oracle@//localhost:1521/xe
链接 sqlplus /nolog
以dba登录 密码默认为oracle:
connect sys as sysdba
数据库结构
体系结构
实例一般情况下Oracle数据库都是一个数据库包含一个实例
数据库
数据文件
表空间:SYSTEM表空间,SYSAUX表空间,撤销表空间,USERS表空间
数据文件:系统数据,用户数据,控制文件,日志文件(重做日志文件,归档日志文件)
说明:表空间是一个数据库的逻辑区域,每个表空间由一个或多个数据文件组成,一个数据文件只能属于一个表空间
服务器结构
系统全局区
数据高速缓冲区
重做日志缓冲区
共享池
Large Pool
后台进程
DBWn
LGWR
SMON
PMON
ARCH
程序全局区
数据字典
存放整个数据库实例重要信息的一组表,多数表归sys用户所有
数据字典构成
USER_
记录用户对象信息
ALL_
记录用户的对象信息及被授权访问的对象信息
DBA_
包含数据库实例的所有对象信息
V$_
当前实例的动态视图
GV_
分布式环境下所有实例的动态视图
常用数据字典
DBA_TABLES(=TABS)
DBA_TAB_COLUMNS(=COLS)
DBA_VIEWS
DBA_SYNONYMS(=SYN)
DBA_SEQUENCES(=SEQ)
DBA_CONSTRAINTS
DBA_INDEXES(=IND)
DBA_IND_COLUMNS
DBA_TRIGGERS
DBA_SOUCE
DBA_SEGMENTS
DBA_EXTENTS
DBA_OBJECTS
TCL
commit
rollback
savepoint
PL/SQL
概述
PL/SQL编程
基本语言块
字符集
注释
数据类型
变量和常量
表达式和运算符
流程控制
if-then-elsif-then-else
case-when-else
loop-exit
for-loop
while-loop
过程和函数
过程
函数
错误处理
预定义异常
DUP_VAL_ON_INDEX
LOGIN_DENIED
NO_DATA_FOUND
TOO_MANY_ROWS
ZERO_DIVIDE
VALUE_ERROR
CASE_NOT_FOUND
自定义异常
RAISE
异常函数
SQLCODE
QLERRM
包
包头
包体
重载
集合
三种类型
index-by表
嵌套表
可变数组
属性和方法
COUNT
DELETE
EXISTS
EXTEND
FIRST/LAST
NEXT/PRIOR
游标
显示游标
隐式游标
游标for循环
游标变量
数据库管理
管理控制文件
管理日志文件
管理表空间和数据文件
模式对象管理
表分区和索引分区
用户管理与安全
数据完整性和数据约束
执行计划
一:什么是Oracle执行计划?
执行计划是一条查询语句在Oracle中的执行过程或访问路径的描述,注意,是查询语句。
二:怎样查看Oracle执行计划?
以PLSQL为例:
执行计划的常用列字段解释:
基数(Rows):Oracle估计的当前操作的返回结果集行数
字节(Bytes):执行该步骤后返回的字节数
耗费(COST)、CPU耗费:Oracle估计的该步骤的执行成本,用于说明SQL执行的代价,理论上越小越好(该值可能与实际有出入)
时间(Time):Oracle估计的当前操作所需的时间
1):打开执行计划:
在SQL窗口选中一条 SELECT 语句后,或者选中Tools > Explain Plan,或者按 F5 即可查看刚刚执行的这条查询语句的执行计划
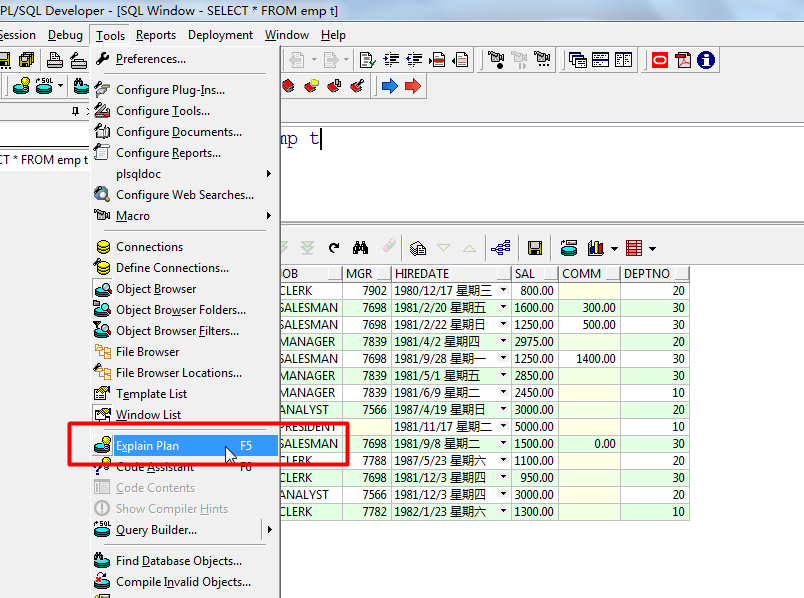
打开执行计划后,可以点击配置按钮进行显示配置。如图
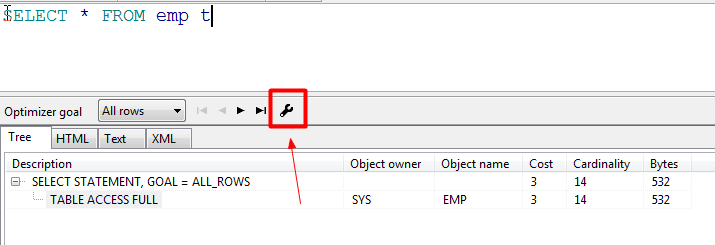
进入如下界面
中文版图解。

三:看懂Oracle执行计划
①:执行顺序:

根据上图中description列的缩进来判断,缩进最多的最先执行,缩进相同时,最上面的最先执行,可以通过点击图中箭头,查看执行顺序。
对图中动作的一些说明:
- 上图中 TABLE ACCESS BY … 即描述的是该动作执行时表访问(或者说Oracle访问数据)的方式;
表访问的几种方式:(非全部)
-
TABLE ACCESS FULL(全表扫描)
-
TABLE ACCESS BY INDEX ROWID(通过ROWID的表存取)
-
INDEX FULL SCAN(索引扫描)
(1) TABLE ACCESS FULL(全表扫描):
Oracle会读取表中所有的行,并检查每一行是否满足SQL语句中的 Where 限制条件;
全表扫描时可以使用多块读(即一次I/O读取多块数据块)操作,提升吞吐量;
使用建议:数据量太大的表不建议使用全表扫描,除非本身需要取出的数据较多,占到表数据总量的 5% ~ 10% 或以上
(2) TABLE ACCESS BY ROWID(通过ROWID的表存取) :
先说一下什么是ROWID?

ROWID是由Oracle自动加在表中每行最后的一列伪列,既然是伪列,就说明表中并不会物理存储ROWID的值;
你可以像使用其它列一样使用它,只是不能对该列的值进行增、删、改操作;
一旦一行数据插入后,则其对应的ROWID在该行的生命周期内是唯一的,即使发生行迁移,该行的ROWID值也不变。
让我们再回到 TABLE ACCESS BY INDEX ROWID 来,INDEX指索引列,也就是说,这里走的是索引的表的ROWID。
行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID可以快速定位到目标数据上,这也是Oracle中存取单行数据最快的方法;
(3) INDEX FULL SCAN(索引扫描):
在索引块中,既存储每个索引的键值,也存储具有该键值的行的ROWID。
一个数字列上建索引后该索引可能的概念结构如下图:
所以索引扫描其实分为两步:
Ⅰ:扫描索引得到对应的ROWID
Ⅱ:通过ROWID定位到具体的行读取数据
-————————————————————————–索引扫描延伸———————华丽丽的分割线——————————————————————————————–
索引扫描分五种:
-
INDEX UNIQUE SCAN(索引唯一扫描)
-
INDEX RANGE SCAN(索引范围扫描)
-
INDEX FULL SCAN(索引全扫描)
-
INDEX FAST FULL SCAN(索引快速扫描)
-
INDEX SKIP SCAN(索引跳跃扫描)
a) INDEX UNIQUE SCAN(索引唯一扫描):
针对唯一性索引(UNIQUE INDEX)的扫描,每次至多只返回一条记录;
表中某字段存在 UNIQUE、PRIMARY KEY 约束时,Oracle常实现唯一性扫描;
b) INDEX RANGE SCAN(索引范围扫描):
使用一个索引存取多行数据;
发生索引范围扫描的三种情况:
-
在唯一索引列上使用了范围操作符(如:> < <> >= <= between)
-
在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
-
对非唯一索引列上进行的任何查询
c) INDEX FULL SCAN(索引全扫描):
进行全索引扫描时,查询出的数据都必须从索引中可以直接得到(注意全索引扫描只有在CBO模式下才有效)
Oracle中的优化器是SQL分析和执行的优化工具,它负责生成、制定SQL的执行计划。
Oracle的优化器有两种:
-
RBO(Rule-Based Optimization) 基于规则的优化器
-
CBO(Cost-Based Optimization) 基于代价的优化器
RBO:
RBO有严格的使用规则,只要按照这套规则去写SQL语句,无论数据表中的内容怎样,也不会影响到你的执行计划;
换句话说,RBO对数据“不敏感”,它要求SQL编写人员必须要了解各项细则;
RBO一直沿用至ORACLE 9i,从ORACLE 10g开始,RBO已经彻底被抛弃。
CBO:
CBO是一种比RBO更加合理、可靠的优化器,在ORACLE 10g中完全取代RBO;
CBO通过计算各种可能的执行计划的“代价”,即COST,从中选用COST最低的执行方案作为实际运行方案;
它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择,也就是对数据“敏感”。
d) INDEX FAST FULL SCAN(索引快速扫描):
扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它不对查询出的数据进行排序(即数据不是以排序顺序被返回)
e) INDEX SKIP SCAN(索引跳跃扫描):
Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,这时候就使用的INDEX SKIP SCAN;
什么时候会触发 INDEX SKIP SCAN 呢?
前提条件:表有一个复合索引,且在查询时有除了前导列(索引中第一列)外的其他列作为条件,并且优化器模式为CBO时
当Oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询;
例如:
假设表emp有ename(雇员名称)、job(职位名)、sex(性别)三个字段,并且建立了如 create index idx_emp on emp (sex, ename, job) 的复合索引;
因为性别只有 ‘男’ 和 ‘女’ 两个值,所以为了提高索引的利用率,Oracle可将这个复合索引拆成 (‘男’, ename, job),(‘女’, ename, job) 这两个复合索引;
当查询 select * from emp where job = ‘Programmer’ 时,该查询发出后:
Oracle先进入sex为’男’的入口,这时候使用到了 (‘男’, ename, job) 这条复合索引,查找 job = ‘Programmer’ 的条目;
再进入sex为’女’的入口,这时候使用到了 (‘女’, ename, job) 这条复合索引,查找 job = ‘Programmer’ 的条目;
最后合并查询到的来自两个入口的结果集。
-———————————————
- 上图中的 NESTED LOOPS … 描述的是表连接方式;
JOIN 关键字用于将两张表作连接,一次只能连接两张表,JOIN 操作的各步骤一般是串行的(在读取做连接的两张表的数据时可以并行读取);
表(row source)之间的连接顺序对于查询效率有很大的影响,对首先存取的表(驱动表)先应用某些限制条件(Where过滤条件)以得到一个较小的row source,可以使得连接效率提高。
-————————延伸阅读:驱动表(Driving Table)与匹配表(Probed Table)————————-
驱动表(Driving Table):
表连接时首先存取的表,又称外层表(Outer Table),这个概念用于 NESTED LOOPS(嵌套循环) 与 HASH JOIN(哈希连接)中;
如果驱动表返回较多的行数据,则对所有的后续操作有负面影响,故一般选择小表(应用Where限制条件后返回较少行数的表)作为驱动表。
匹配表(Probed Table):
又称为内层表(Inner Table),从驱动表获取一行具体数据后,会到该表中寻找符合连接条件的行。故该表一般为大表(应用Where限制条件后返回较多行数的表)。
-——————————————————————————————————–
表连接的几种方式:
-
SORT MERGE JOIN(排序-合并连接)
-
NESTED LOOPS(嵌套循环)
-
HASH JOIN(哈希连接)
-
CARTESIAN PRODUCT(笛卡尔积)
注:这里将首先存取的表称作 row source 1,将之后参与连接的表称作 row source 2;
(1) SORT MERGE JOIN(排序-合并连接):
假设有查询:select a.name, b.name from table_A a join table_B b on (a.id = b.id)
内部连接过程:
a) 生成 row source 1 需要的数据,按照连接操作关联列(如示例中的a.id)对这些数据进行排序
b) 生成 row source 2 需要的数据,按照与 a) 中对应的连接操作关联列(b.id)对数据进行排序
c) 两边已排序的行放在一起执行合并操作(对两边的数据集进行扫描并判断是否连接)
延伸:
如果示例中的连接操作关联列 a.id,b.id 之前就已经被排过序了的话,连接速度便可大大提高,因为排序是很费时间和资源的操作,尤其对于有大量数据的表。
故可以考虑在 a.id,b.id 上建立索引让其能预先排好序。不过遗憾的是,由于返回的结果集中包括所有字段,所以通常的执行计划中,即使连接列存在索引,也不会进入到执行计划中,除非进行一些特定列处理(如仅仅只查询有索引的列等)。
排序-合并连接的表无驱动顺序,谁在前面都可以;
排序-合并连接适用的连接条件有: < <= = > >= ,不适用的连接条件有: <> like
(2) NESTED LOOPS(嵌套循环):
内部连接过程:
a) 取出 row source 1 的 row 1(第一行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中
b) 取出 row source 1 的 row 2(第二行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中
c) ……
若 row source 1 (即驱动表)中返回了 N 行数据,则 row source 2 也相应的会被全表遍历 N 次。
因为 row source 1 的每一行都会去匹配 row source 2 的所有行,所以当 row source 1 返回的行数尽可能少并且能高效访问 row source 2(如建立适当的索引)时,效率较高。
延伸:
嵌套循环的表有驱动顺序,注意选择合适的驱动表。
嵌套循环连接有一个其他连接方式没有的好处是:可以先返回已经连接的行,而不必等所有的连接操作处理完才返回数据,这样可以实现快速响应。
应尽可能使用限制条件(Where过滤条件)使驱动表(row source 1)返回的行数尽可能少,同时在匹配表(row source 2)的连接操作关联列上建立唯一索引(UNIQUE INDEX)或是选择性较好的非唯一索引,此时嵌套循环连接的执行效率会变得很高。若驱动表返回的行数较多,即使匹配表连接操作关联列上存在索引,连接效率也不会很高。
(3)HASH JOIN(哈希连接) :
哈希连接只适用于等值连接(即连接条件为 = )
HASH JOIN对两个表做连接时并不一定是都进行全表扫描,其并不限制表访问方式;
内部连接过程简述:
a) 取出 row source 1(驱动表,在HASH JOIN中又称为Build Table) 的数据集,然后将其构建成内存中的一个 Hash Table(Hash函数的Hash KEY就是连接操作关联列),创建Hash位图(bitmap)
b) 取出 row source 2(匹配表)的数据集,对其中的每一条数据的连接操作关联列使用相同的Hash函数并找到对应的 a) 里的数据在 Hash Table 中的位置,在该位置上检查能否找到匹配的数据
-—————延伸阅读:Hash Table相关—————-
来自Wiki的解释:
In computing, a hash table (hash map) is a data structure used to implement an associative array, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
散列(hash)技术:在记录的存储位置和记录具有的关键字key之间建立一个对应关系 f ,使得输入key后,可以得到对应的存储位置 f(key),这个对应关系 f 就是散列(哈希)函数;
采用散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间就是散列表(哈希表);
不同的key经同一散列函数散列后得到的散列值理论上应该不同,但是实际中有可能相同,相同时即是发生了散列(哈希)冲突,解决散列冲突的办法有很多,比如HashMap中就是用链地址法来解决哈希冲突;
哈希表是一种面向查找的数据结构,在输入给定值后查找给定值对应的记录在表中的位置以获取特定记录这个过程的速度很快。
-——————————————————-
HASH JOIN的三种模式:
-
OPTIMAL HASH JOIN
-
ONEPASS HASH JOIN
-
MULTIPASS HASH JOIN
(1) OPTIMAL HASH JOIN:
OPTIMAL 模式是从驱动表(也称Build Table)上获取的结果集比较小,可以把根据结果集构建的整个Hash Table都建立在用户可以使用的内存区域里。

连接过程简述:
Ⅰ:首先对Build Table内各行数据的连接操作关联列使用Hash函数,把Build Table的结果集构建成内存中的Hash Table。如图所示,可以把Hash Table看作内存中的一块大的方形区域,里面有很多的小格子,Build Table里的数据就分散分布在这些小格子中,而这些小格子就是Hash Bucket(见上面Wiki的定义)。
Ⅱ:开始读取匹配表(Probed Table)的数据,对其中每行数据的连接操作关联列都使用同上的Hash函数,定位Build Table里使用Hash函数后具有相同值数据所在的Hash Bucket。
Ⅲ:定位到具体的Hash Bucket后,先检查Bucket里是否有数据,没有的话就马上丢掉匹配表(Probed Table)的这一行。如果里面有数据,则继续检查里面的数据(驱动表的数据)是否和匹配表的数据相匹配。
(2): ONEPASS HASH JOIN :
从驱动表(也称Build Table)上获取的结果集较大,无法将根据结果集构建的Hash Table全部放入内存中时,会使用 ONEPASS 模式。

连接过程简述:
Ⅰ:对Build Table内各行数据的连接操作关联列使用Hash函数,根据Build Table的结果集构建Hash Table后,由于内存无法放下所有的Hash Table内容,将导致有的Hash Bucket放在内存里,有的Hash Bucket放在磁盘上,无论放在内存里还是磁盘里,Oracle都使用一个Bitmap结构来反映这些Hash Bucket的状态(包括其位置和是否有数据)。
Ⅱ:读取匹配表数据并对每行的连接操作关联列使用同上的Hash函数,定位Bitmap上Build Table里使用Hash函数后具有相同值数据所在的Bucket。如果该Bucket为空,则丢弃匹配表的这条数据。如果不为空,则需要看该Bucket是在内存里还是在磁盘上。
如果在内存中,就直接访问这个Bucket并检查其中的数据是否匹配,有匹配的话就返回这条查询结果。
如果在磁盘上,就先把这条待匹配数据放到一边,将其先暂存在内存里,等以后积累了一定量的这样的待匹配数据后,再批量的把这些数据写入到磁盘上(上图中的 Dump probe partitions to disk)。
Ⅲ:当把匹配表完整的扫描了一遍后,可能已经返回了一部分匹配的数据了。接下来还有Hash Table中一部分在磁盘上的Hash Bucket数据以及匹配表中部分被写入到磁盘上的待匹配数据未处理,现在Oracle会把磁盘上的这两部分数据重新匹配一次,然后返回最终的查询结果。
(3): MULTIPASS HASH JOIN:
当内存特别小或者相对而言Hash Table的数据特别大时,会使用 MULTIPASS 模式。MULTIPASS会多次读取磁盘数据,应尽量避免使用该模式。
Hint
oracle中hint 详解 Hint概述
基于代价的优化器是很聪明的,在绝大多数情况下它会选择正确的优化器,减轻了DBA的负担。但有时它也聪明反被聪明误,选择了很差的执行计划,使某个语句的执行变得奇慢无比。
此时就需要DBA进行人为的干预,告诉优化器使用我们指定的存取路径或连接类型生成执行计划,从 而使语句高效的运行。例如,如果我们认为对于一个特定的语句,执行全表扫描要比执行索引扫描更有效,则我们就可以指示优化器使用全表扫描。在Oracle 中,是通过为语句添加 Hints(提示)来实现干预优化器优化的目的。 不建议在代码中使用hint,在代码使用hint使得CBO无法根据实际的数据状态选择正确的执行计划。毕竟 数据是不断变化的, 10g以后的CBO也越来越完善,大多数情况下我们该让Oracle自行决定采用什么执行计划。
Oracle Hints是一种机制,用来告诉优化器按照我们的告诉它的方式生成执行计划。我们可以用Oracle Hints来实现: 1) 使用的优化器的类型 2) 基于代价的优化器的优化目标,是all_rows还是first_rows。 3) 表的访问路径,是全表扫描,还是索引扫描,还是直接利用rowid。 4) 表之间的连接类型 5) 表之间的连接顺序 6) 语句的并行程度
除了”RULE”提示外,一旦使用的别的提示,语句就会自动的改为使用CBO优化器,此时如果你的数据字典中没有统计数据,就会使用缺省的统计数据。所以建议大家如果使用CBO或Hints提示,则最好对表和索引进行定期的分析。
如何使用Hints:
Hints只应用在它们所在sql语句块(statement block,由select、update、delete关键字标识)上,对其它SQL语句或语句的其它部分没有影响。如:对于使用union操作的2个sql语句,如果只在一个sql语句上有Hints,则该Hints不会影响另一个sql语句。
我们可以使用注释(comment)来为一个语句添加Hints,一个语句块只能有一个注释,而且注释只能放在SELECT, UPDATE, or DELETE关键字的后面
使用Oracle Hints的语法:
| {DELETE | INSERT | SELECT | UPDATE} /*+ hint [text] [hint[text]]… */ |
or
| {DELETE | INSERT | SELECT | UPDATE} –+ hint [text] [hint[text]]… |
注解: 1) DELETE、INSERT、SELECT和UPDATE是标识一个语句块开始的关键字,包含提示的注释只能出现在这些关键字的后面,否则提示无效。 2) “+”号表示该注释是一个Hints,该加号必须立即跟在”/*”的后面,中间不能有空格。 3) hint是下面介绍的具体提示之一,如果包含多个提示,则每个提示之间需要用一个或多个空格隔开。 4) text 是其它说明hint的注释性文本
5)使用表别名。如果在查询中指定了表别名,那么提示必须也使用表别名。例如:select /+ index(e,dept_idx) */ * from emp e; 6)不要在提示中使用模式名称:如果在提示中指定了模式的所有者,那么提示将被忽略。例如: select /+ index(scott.emp,dept_idx) */ * from emp
注意:如果你没有正确的指定Hints,Oracle将忽略该Hints,并且不会给出任何错误。
hint被忽略
如果CBO认为使用hint会导致错误的结果时,hint将被忽略,详见下例
1 2 3 4 5 6 7 8 9 10 11 SQL> select /+ index(t t_ind) */ count() from t; Execution Plan ———————————————————- Plan hash value: 2966233522 ——————————————————————- | Id | Operation | Name | Rows | Cost (%CPU)| Time | ——————————————————————- | 0 | SELECT STATEMENT | | 1 | 57 (2)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | | | | 2 | TABLE ACCESS FULL| T | 50366 | 57 (2)| 00:00:01 | ——————————————————————- 因为我们是对记录求总数,且我们并没有在建立索引时指定不能为空,如果CBO选择在索引上进行count时,但索引字段上的值为空时,结果将不准确,故CBO没有选择索引。
1 2 3 4 5 6 7 8 9 10 11 SQL> select /*+ index(t t_ind) */ count(id) from t; Execution Plan ———————————————————- Plan hash value: 646498162 ————————————————————————– | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ————————————————————————– | 0 | SELECT STATEMENT | | 1 | 5 | 285 (1)| 00:00:04 | | 1 | SORT AGGREGATE | | 1 | 5 | | | | 2 | INDEX FULL SCAN| T_IND | 50366 | 245K| 285 (1)| 00:00:04 | ————————————————————————– 因为我们只对id进行count,这个动作相当于count索引上的所有id值,这个操作和对表上的id字段进行count是一样的(组函数会忽略null值),故使用了索引。
和优化器相关的hint
1、/*+ ALL_ROWS */ 表明对语句块选择基于开销的优化方法,并获得最佳吞吐量,使资源消耗最小化.
SELECT /+ ALL+_ROWS/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO=’SCOTT’;
2、/*+ FIRST_ROWS(n) */ 表明对语句块选择基于开销的优化方法,并获得最佳响应时间,使资源消耗最小化.
SELECT /*+FIRST_ROWS(20) */ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO=’SCOTT’;
3、/+ RULE/ 表明对语句块选择基于规则的优化方法.
SELECT /*+ RULE */ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO=’SCOTT’;
和访问路径相关的hint
1、/+ FULL(TABLE)/ 表明对表选择全局扫描的方法.
SELECT /+FULL(A)/ EMP_NO,EMP_NAM FROM BSEMPMS A WHERE EMP_NO=’SCOTT’;
2、/*+ INDEX(TABLE INDEX_NAME) */ 表明对表选择索引的扫描方法.
SELECT /*+INDEX(BSEMPMS SEX_INDEX) */ * FROM BSEMPMS WHERE SEX=’M’;
3、/+ INDEX_ASC(TABLE INDEX_NAME)/ 表明对表选择索引升序的扫描方法.
SELECT /*+INDEX_ASC(BSEMPMS PK_BSEMPMS) */ * FROM BSEMPMS WHERE DPT_NO=’SCOTT’;
4、/+ INDEX_COMBINE/ 为指定表选择位图访问路经,如果INDEX_COMBINE中没有提供作为参数的索引,将选择出位图索引的布尔组合方式.
SELECT /*+INDEX_COMBINE(BSEMPMS SAL_BMI HIREDATE_BMI) */ * FROM BSEMPMS WHERE SAL<5000000 AND HIREDATE
5、/*+ INDEX_JOIN(TABLE INDEX_NAME1 INDEX_NAME2) */ 当谓词中引用的列都有索引的时候,可以通过指定采用索引关联的方式,来访问数据
select /*+ index_join(t t_ind t_bm) */ id from t where id=100 and object_name=’EMPLOYEES’
6、/+ INDEX_DESC(TABLE INDEX_NAME)/ 表明对表选择索引降序的扫描方法.
SELECT /*+INDEX_DESC(BSEMPMS PK_BSEMPMS) */ * FROM BSEMPMS WHERE DPT_NO=’SCOTT’;
7、/*+ INDEX_FFS(TABLE INDEX_NAME) */ 对指定的表执行快速全索引扫描,而不是全表扫描的办法.
SELECT /* + INDEX_FFS(BSEMPMS IN_EMPNAM)*/ * FROM BSEMPMS WHERE DPT_NO=’TEC305’;
8、/*+ INDEX_SS(T T_IND) */ 从9i开始,oracle引入了这种索引访问方式。当在一个联合索引中,某些谓词条件并不在联合索引的第一列时,可以通过Index Skip Scan来访问索引获得数据。当联合索引第一列的唯一值个数很少时,使用这种方式比全表扫描效率高。
1
SQL> create table t as select 1 id,object_name from dba_objects;
Table created.
SQL> insert into t select 2,object_name from dba_objects;
50366 rows created.
SQL> insert into t select 3,object_name from dba_objects;
50366 rows created.
SQL> insert into t select 4,object_name from dba_objects;
50366 rows created.
SQL> commit;
Commit complete.
SQL> create index t_ind on t(id,object_name);
Index created.
SQL> exec dbms_stats.gather_table_stats(‘HR’,’T’,cascade=>true);
PL/SQL procedure successfully completed.
执行全表扫描
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 SQL> select /+ full(t) */ * from t where object_name=’EMPLOYEES’; 6 rows selected. Execution Plan ———————————————————- Plan hash value: 1601196873 ————————————————————————– | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ————————————————————————– | 0 | SELECT STATEMENT | | 5 | 135 | 215 (3)| 00:00:03 | | 1 | TABLE ACCESS FULL| T | 5 | 135 | 215 (3)| 00:00:03 | ————————————————————————– Predicate Information (identified by operation id): ————————————————— 1 - filter(“OBJECT_NAME”=’EMPLOYEES’) Statistics ———————————————————- 0 recursive calls 0 db block gets 942 consistent gets 0 physical reads 0 redo size 538 bytes sent via SQLNet to client 385 bytes received via SQLNet from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 6 rows processed
不采用hint
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 SQL> select * from t where object_name=’EMPLOYEES’; 6 rows selected. Execution Plan ———————————————————- Plan hash value: 2869677071 ————————————————————————– | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ————————————————————————– | 0 | SELECT STATEMENT | | 5 | 135 | 5 (0)| 00:00:01 | |* 1 | INDEX SKIP SCAN | T_IND | 5 | 135 | 5 (0)| 00:00:01 | ————————————————————————– Predicate Information (identified by operation id): ————————————————— 1 - access(“OBJECT_NAME”=’EMPLOYEES’) filter(“OBJECT_NAME”=’EMPLOYEES’) Statistics ———————————————————- 1 recursive calls 0 db block gets 17 consistent gets 1 physical reads 0 redo size 538 bytes sent via SQLNet to client 385 bytes received via SQLNet from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 6 rows processed 当全表扫描扫描了942个块,联合索引只扫描了17个数据块。可以看到联合索引的第一个字段的值重复率很高时,即使谓词中没有联合索引的第一个字段,依然会使用index_ss方式,效率远远高于全表扫描效率。但当 第一个字段的值重复率很低时,使用 index_ss的效率要低于 全表扫描,读者可以自行实验
和表的关联相关的hint
/*+ leading(table_1,table_2) */
在多表关联查询中,指定哪个表作为驱动表,即告诉优化器首先要访问哪个表上的数据。
select /+ leading(t,t1) */ t. from t,t1 where t.id=t1.id; /*+ order */
让Oracle根据from后面表的顺序来选择驱动表,oracle建议使用leading,他更为灵活
select /+ order */ t. from t,t1 where t.id=t1.id;
/*+ use_nl(table_1,table_2) */ 在多表关联查询中,指定使用nest loops方式进行多表关联。
select /+ use_nl(t,t1) */ t. from t,t1 where t.id=t1.id;
/*+ use_hash(table_1,table_2) */ 在多表关联查询中,指定使用hash join方式进行多表关联。
select /+ use_hash(t,t1) */ t. from t,t1 where t.id=t1.id;
在多表关联查询中,指定使用hash join方式进行多表关联,并指定表t为驱动表。
select /+ use_hash(t,t1) leading(t,t1) */ t. from t,t1 where t.id=t1.id;
/*+ use_merge(table_1,table_2) */ 在多表关联查询中,指定使用merge join方式进行多表关联。
select /+ use_merge(t,t1) */ t. from t,t1 where t.id=t1.id;
/*+ no_use_nl(table_1,table_2) */ 在多表关联查询中,指定不使用nest loops方式进行多表关联。
select /+ no_use_nl(t,t1) */ t. from t,t1 where t.id=t1.id;
/*+ no_use_hash(table_1,table_2) */ 在多表关联查询中,指定不使用hash join方式进行多表关联。
select /+ no_use_hash(t,t1) */ t. from t,t1 where t.id=t1.id;
/*+ no_use_merge(table_1,table_2) */ 在多表关联查询中,指定不使用merge join方式进行多表关联。
select /+ no_use_merge(t,t1) */ t. from t,t1 where t.id=t1.id;
其他常用的hint
/*+ parallel(table_name n) */
在sql中指定执行的并行度,这个值将会覆盖自身的并行度
select /+ parallel(t 4) */ count() from t;
/*+ no_parallel(table_name) */
在sql中指定执行的不使用并行
select /+ no_parallel(t) */ count() from t;
/*+ append */以直接加载的方式将数据加载入库
insert into t /*+ append */ select * from t;
/*+ dynamic_sampling(table_name n) */
设置sql执行时动态采用的级别,这个级别为0~10 select /*+ dynamic_sampling(t 4) */ * from t where id > 1234
/*+ cache(table_name) */ 进行全表扫描时将table置于LRU列表的最活跃端,类似于table的cache属性
select /*+ full(employees) cache(employees) */ last_name from employees
附录hint表格
Hints for Optimization Approaches and Goals
ALL_ROWS The ALL_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best throughput (that is, minimum total resource consumption). FIRST_ROWS The FIRST_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best response time (minimum resource usage to return first row). In newer Oracle version you should give a parameter with this hint: FIRST_ROWS(n) means that the optimizer will determine an executionplan to give a fast response for returning the first n rows. CHOOSE The CHOOSE hint causes the optimizer to choose between the rule-based approach and the cost-based approach for a SQL statement based on the presence of statistics for the tables accessed by the statement RULE The RULE hint explicitly chooses rule-based optimization for a statement block. This hint also causes the optimizer to ignore any other hints specified for the statement block. The RULE hint does not work any more in Oracle 10g. Hints for Access Paths
FULL The FULL hint explicitly chooses a full table scan for the specified table. The syntax of the FULL hint is FULL(table) where table specifies the alias of the table (or table name if alias does not exist) on which the full table scan is to be performed.
ROWID The ROWID hint explicitly chooses a table scan by ROWID for the specified table. The syntax of the ROWID hint is ROWID(table) where table specifies the name or alias of the table on which the table access by ROWID is to be performed. (This hint depricated in Oracle 10g)
CLUSTER The CLUSTER hint explicitly chooses a cluster scan to access the specified table. The syntax of the CLUSTER hint is CLUSTER(table) where table specifies the name or alias of the table to be accessed by a cluster scan.
HASH The HASH hint explicitly chooses a hash scan to access the specified table. The syntax of the HASH hint is HASH(table) where table specifies the name or alias of the table to be accessed by a hash scan.
HASH_AJ The HASH_AJ hint transforms a NOT IN subquery into a hash anti-join to access the specified table. The syntax of the HASH_AJ hint is HASH_AJ(table) where table specifies the name or alias of the table to be accessed.(depricated in Oracle 10g)
INDEX The INDEX hint explicitly chooses an index scan for the specified table. The syntax of the INDEX hint is INDEX(table index) where:table specifies the name or alias of the table associated with the index to be scanned and index specifies an index on which an index scan is to be performed. This hint may optionally specify one or more indexes:
NO_INDEX The NO_INDEX hint explicitly disallows a set of indexes for the specified table. The syntax of the NO_INDEX hint is NO_INDEX(table index)
INDEX_ASC The INDEX_ASC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in ascending order of their indexed values.
INDEX_COMBINE If no indexes are given as arguments for the INDEX_COMBINE hint, the optimizer will use on the table whatever boolean combination of bitmap indexes has the best cost estimate. If certain indexes are given as arguments, the optimizer will try to use some boolean combination of those particular bitmap indexes. The syntax of INDEX_COMBINE is INDEX_COMBINE(table index).
INDEX_JOIN Explicitly instructs the optimizer to use an index join as an access path. For the hint to have a positive effect, a sufficiently small number of indexes must exist that contain all the columns required to resolve the query.
INDEX_DESC The INDEX_DESC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in descending order of their indexed values.
INDEX_FFS This hint causes a fast full index scan to be performed rather than a full table.
NO_INDEX_FFS Do not use fast full index scan (from Oracle 10g)
INDEX_SS Exclude range scan from query plan (from Oracle 10g)
INDEX_SS_ASC Exclude range scan from query plan (from Oracle 10g)
INDEX_SS_DESC Exclude range scan from query plan (from Oracle 10g)
NO_INDEX_SS The NO_INDEX_SS hint causes the optimizer to exclude a skip scan of the specified indexes on the specified table. (from Oracle 10g)
Hints for Query Transformations
NO_QUERY_TRANSFORMATION Prevents the optimizer performing query transformations. (from Oracle 10g) USE_CONCAT The USE_CONCAT hint forces combined OR conditions in the WHERE clause of a query to be transformed into a compound query using the UNION ALL set operator. Normally, this transformation occurs only if the cost of the query using the concatenations is cheaper than the cost without them. NO_EXPAND The NO_EXPAND hint prevents the optimizer from considering OR-expansion for queries having OR conditions or IN-lists in the WHERE clause. Usually, the optimizer considers using OR expansion and uses this method if it decides that the cost is lower than not using it. REWRITE The REWRITE hint forces the optimizer to rewrite a query in terms of materialized views, when possible, without cost consideration. Use the REWRITE hint with or without a view list. If you use REWRITE with a view list and the list contains an eligible materialized view, then Oracle uses that view regardless of its cost. NOREWRITE / NO_REWRITE In Oracle 10g renamed to NO_REWRITE. The NOREWRITE/NO_REWRITE hint disables query rewrite for the query block, overriding the setting of the parameter QUERY_REWRITE_ENABLED. MERGE The MERGE hint lets you merge views in a query. NO_MERGE The NO_MERGE hint causes Oracle not to merge mergeable views. This hint is most often used to reduce the number of possible permutations for a query and make optimization faster. FACT The FACT hint indicated that the table should be considered as a fact table. This is used in the context of the star transformation. NO_FACT The NO_FACT hint is used in the context of the star transformation to indicate to the transformation that the hinted table should not be considered as a fact table. STAR_TRANSFORMATION The STAR_TRANSFORMATION hint makes the optimizer use the best plan in which the transformation has been used. Without the hint, the optimizer could make a query optimization decision to use the best plan generated without the transformation, instead of the best plan for the transformed query. NO_STAR_TRANSFORMATION Do not use star transformation (from Oracle 10g) UNNEST The UNNEST hint specifies subquery unnesting. NO_UNNEST Use of the NO_UNNEST hint turns off unnesting for specific subquery blocks.
Hints for Join Orders
LEADING Give this hint to indicate the leading table in a join. This will indicate only 1 table. If you want to specify the whole order of tables, you can use the ORDERED hint. Syntax: LEADING(table) ORDERED The ORDERED hint causes Oracle to join tables in the order in which they appear in the FROM clause. If you omit the ORDERED hint from a SQL statement performing a join , the optimizer chooses the order in which to join the tables. You may want to use the ORDERED hint to specify a join order if you know something about the number of rows selected from each table that the optimizer does not. Such information would allow you to choose an inner and outer table better than the optimizer could.
Hints for Join Operations
USE_NL The USE_NL hint causes Oracle to join each specified table to another row source with a nested loops join using the specified table as the inner table. The syntax of the USE_NL hint is USE_NL(table table) where table is the name or alias of a table to be used as the inner table of a nested loops join. NO_USE_NL Do not use nested loop (from Oracle 10g) USE_NL_WITH_INDEX Specifies a nested loops join. (from Oracle 10g) USE_MERGE The USE_MERGE hint causes Oracle to join each specified table with another row source with a sort-merge join. The syntax of the USE_MERGE hint is USE_MERGE(table table) where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a sort-merge join. NO_USE_MERGE Do not use merge (from Oracle 10g) USE_HASH The USE_HASH hint causes Oracle to join each specified table with another row source with a hash join. The syntax of the USE_HASH hint is USE_HASH(table table) where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a hash join. NO_USE_HASH Do not use hash (from Oracle 10g) Hints for Parallel Execution PARALLEL The PARALLEL hint allows you to specify the desired number of concurrent query servers that can be used for the query. The syntax is PARALLEL(table number number). The PARALLEL hint must use the table alias if an alias is specified in the query. The PARALLEL hint can then take two values separated by commas after the table name. The first value specifies the degree of parallelism for the given table, the second value specifies how the table is to be split among the instances of a parallel server. Specifying DEFAULT or no value signifies the query coordinator should examine the settings of the initialization parameters (described in a later section) to determine the default degree of parallelism. NOPARALLEL / NO_PARALLEL The NOPARALLEL hint allows you to disable parallel scanning of a table, even if the table was created with a PARALLEL clause. In Oracle 10g this hint was renamed to NO_PARALLEL. PQ_DISTRIBUTE The PQ_DISTRIBUTE hint improves the performance of parallel join operations. Do this by specifying how rows of joined tables should be distributed among producer and consumer query servers. Using this hint overrides decisions the optimizer would normally make. NO_PARALLEL_INDEX The NO_PARALLEL_INDEX hint overrides a PARALLEL attribute setting on an index to avoid a parallel index scan operation. Additional Hints APPEND When the APPEND hint is used with the INSERT statement, data is appended to the table. Existing free space in the block is not used. If a table or an index is specified with nologging, this hint applied with an insert statement produces a direct path insert which reduces generation of redo. NOAPPEND Overrides the append mode. CACHE The CACHE hint specifies that the blocks retrieved for the table in the hint are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables. In the following example, the CACHE hint overrides the table default caching specification. NOCACHE The NOCACHE hint specifies that the blocks retrieved for this table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. This is the normal behavior of blocks in the buffer cache. PUSH_PRED The PUSH_PRED hint forces pushing of a join predicate into the view. NO_PUSH_PRED The NO_PUSH_PRED hint prevents pushing of a join predicate into the view. PUSH_SUBQ The PUSH_SUBQ hint causes nonmerged subqueries to be evaluated at the earliest possible place in the execution plan. NO_PUSH_SUBQ The NO_PUSH_SUBQ hint causes non-merged subqueries to be evaluated as the last step in the execution plan. QB_NAME Specifies a name for a query block. (from Oracle 10g) CURSOR_SHARING_EXACT Oracle can replace literals in SQL statements with bind variables, if it is safe to do so. This is controlled with the CURSOR_SHARING startup parameter. The CURSOR_SHARING_EXACT hint causes this behavior to be switched off. In other words, Oracle executes the SQL statement without any attempt to replace literals by bind variables. DRIVING_SITE The DRIVING_SITE hint forces query execution to be done for the table at a different site than that selected by Oracle DYNAMIC_SAMPLING The DYNAMIC_SAMPLING hint lets you control dynamic sampling to improve server performance by determining more accurate predicate selectivity and statistics for tables and indexes. You can set the value of DYNAMIC_SAMPLING to a value from 0 to 10. The higher the level, the more effort the compiler puts into dynamic sampling and the more broadly it is applied. Sampling defaults to cursor level unless you specify a table. SPREAD_MIN_ANALYSIS This hint omits some of the compile time optimizations of the rules, mainly detailed dependency graph analysis, on spreadsheets. Some optimizations such as creating filters to selectively populate spreadsheet access structures and limited rule pruning are still used. (from Oracle 10g) Hints with unknown status
MERGE_AJ The MERGE_AJ hint transforms a NOT IN subquery into a merge anti-join to access the specified table. The syntax of the MERGE_AJ hint is MERGE_AJ(table) where table specifies the name or alias of the table to be accessed.(depricated in Oracle 10g) AND_EQUAL The AND_EQUAL hint explicitly chooses an execution plan that uses an access path that merges the scans on several single-column indexes. The syntax of the AND_EQUAL hint is AND_EQUAL(table index index) where table specifies the name or alias of the table associated with the indexes to be merged. and index specifies an index on which an index scan is to be performed. You must specify at least two indexes. You cannot specify more than five. (depricated in Oracle 10g) STAR The STAR hint forces the large table to be joined last using a nested loops join on the index. The optimizer will consider different permutations of the small tables. (depricated in Oracle 10g) BITMAP Usage: BITMAP(table_name index_name) Uses a bitmap index to access the table. (depricated ?) HASH_SJ Use a Hash Anti-Join to evaluate a NOT IN sub-query. Use this hint in the sub-query, not in the main query. Use this when your high volume NOT IN sub-query is using a FILTER or NESTED LOOPS join. Try MERGE_AJ if HASH_AJ refuses to work.(depricated in Oracle 10g) NL_SJ Use a Nested Loop in a sub-query. (depricated in Oracle 10g) NL_AJ Use an anti-join in a sub-query. (depricated in Oracle 10g) ORDERED_PREDICATES (depricated in Oracle 10g) EXPAND_GSET_TO_UNION (depricated in Oracle 10g)
Oracle 优化器
优化器(optimizer)是oracle数据库内置的一个核心子系统。优化器的目的是按照一定的判断原则来得到它认为的目标SQL在当前的情形下的最高效的执行路径,也就是为了得到目标SQL的最佳执行计划。依据所选择执行计划时所用的判断原则,oracle数据库里的优化器又分为RBO(基于原则的优化器)和CBO(基于成本的优化器,SQL的成本根据统计信息算出)两种。
一、RBO Oracle会在代码里事先为各种类型的执行路径定一个等级,一共15个等级,从等级1到等级15,oracle认为等级1的执行路径是效率最高的,等级15是执行效率最差的。对于等级相同的执行计划,oracle根据目标对象的在数据字典中缓存的顺序判断选择哪一种执行计划。RBO是一种适合于OLTP类型SQL语句的优化器。相对于CBO而言,RBO有着先天的缺陷,一旦SQL语句的执行计划出现问题,将很难调整。那么RBO执行计划出现问题,怎么调整目标SQL的执行计划呢?一般有如下方法:等价改写目标SQL,比如在where条件对number和date类型的列添加0(deptno+0>100),varchar2或char类型的列可以添加一个“空字符”,例如“||”。对于多表连接的SQL,可以改变from表的连接顺序(RBO会按照从右往左的顺序决定谁是驱动表,谁是被驱动表。)来达到改变目标SQL执行计划的目的。我们也可以改变相关对象在数据字典中缓存的顺序(创建顺序),来改变执行计划。RBO最大的缺点是以oracle内置代码的规则作为判断标准,而并没有考虑到实际目标表的数据量以及数据分布情况。
二、CBO CBO选择执行计划时,以目标SQL成本为判断原则,CBO会选择一条执行成本最小的执行计划作为SQL的执行计划,各条执行路径的成本通过目标SQL语句所涉及的表、索引、列等的统计信息算出。这里的成本是oracle通过相关对象的统计信息计算出来的一个值,它实际上代表目标SQL对应执行步骤所消耗的IO、CPU、网络资源(针对于dblink下的分布式数据库系统而言)的消耗量,oracle会把网络资源的消耗量计算在IO成本内,实际上你看到的成本为IO、CPU资源,另外需要注意的是,oracle在未引入系统统计信息之前,CBO所计算的成本值实际全是基于IO计算的。
1、集的势(cardinality)
Cardinality是CBO特有的概念,指集合所包含的记录数,即结果集行数。Cardinality实际上表示对目标SQL某个具体执行步骤的执行结果所包含的记录数的估算,当然,如果针对整个目标SQL,那么此时的cardinality就表示对该SQL最终执行结果所包含的记录数的估算。Cardinality和成本值得估算息息相关,因为oracle得到的制定结果集所需要消耗的IO资源可以近似的看成随着结果集所包含的记录数递增而递增。所以,SQL编写的一个原则就是“尽早的过滤更多的数据”。
2、可选择率(Selectivity)
Selectivity也是CBO特有的概念,它是指“施加指定谓语条件后返回的结果集的记录数占未施加任何谓语条件的原始结果集的记录数的比率”,取值范围为0~1,其值越小,代表可选择性越好。Selectivity也可成本值得估算息息相关,可选择率越大,意味着所返回的结果集的cardinality越大,所以估算的成本就越大。实际上CBO就是利用selectivity来计算对应结果集的cardinality的,即:
Computed cardinality=original*selectivity
Cardinility和selectivity的值会直接影响CBO对于相关执行步骤成本的估算,进而影响CBO对于目标SQL的执行计划的选择。
3、可传递性
可传递性也是CBO的特有属性,它是查询转换中所做的第一件事情,其含义是CBO会对目标SQL做等价改写,进而提供更多的执行路径给目标CBO,增加得到最佳执行计划的可能性。RBO不会对目标SQL做等价改写。Oracle里可传递性分为以下3种情况:
1)简单谓语传递:比如原目标SQL中的谓语条件是“t1.c1=t2.c1 and t1.c1=10”,则CBO可能会给谓语条件额外加上“t2.c1=10”。
2)连接谓语传递:比如原目标SQL中的谓语条件是“t1.c1=t2.c1 and t2.c1=t3.c1”,则CBO可能会给谓语条件额外加上“t1.c1=t3.c1”。
3)外链接谓语传递:比如原目标SQL中的谓语条件是“t1.c1=t2.c1(+) and t1.c1=10”,则CBO可能会给谓语条件额外加上“t2.c1(+)=10”。
4、CBO的局限性
1)CBO会默认目标SQL语句where条件中出现的各个列之间出现是独立的,没有任何关联。并且CBO会根据这个前提条件来计算selectivity和cardinality,进而估算成本并选择执行计划。但是这种假设并不全是正确的,生产中列与列之间存在关联的现象并不罕见。目前可以用来缓解上述负面影响的方法是使用动态采样和多列统计信息。但动态采样的准确性取决于采样数据的质量以及数量,而多列统计信息并不适合用于多表之间有关联的情形,所以这两种方法只能算是缓解,并不算是完美的解决方案。
2)CBO会假设所有的目标SQL都是独立运行的,并且互不干扰,但实际情况却不完全是这样。
3)CBO对直方图统计信息有多方限制。主要体现在如下2个方面:
(1)在oracle 12c之前,frequency类型的直方图所对应的bucket的数量不能超过254,这样如果列的distinct数量超过254,oracle就会使用height balanced类型的直方图。对于height balanced类型的直方图而言,oracle不会记录所有的nonpopular value的值,所以此种情况下CBO选错执行计划的概率会比frequency类型的情形要高。
(2)在oracle数据库里,如果针对文本类型的字段手机直方图统计信息,则oracle只会将文本的前32个字符(实际只取前15个)取出来并将其转换为浮点数,然后将浮点数作为上述文本字段的直方图统计信息记录在数据字典里。
4)CBO在解析多表关联的目标SQL时,可能会漏选正确的执行计划。在oracle 11gR2中,CBO在解析这种多表关联的目标SQL时,所考虑的各个表的连接顺序的总和受隐含参数_OPTIMIZER_MAX_PERMUTATIONS的限制。这意味着目标SQL不管有多少种连接顺序,CBO最多只考虑其中根据_OPTIMIZER_MAX_PERMUTATIONS计算出来的有限种可能性。
三、优化器基础知识 1、优化器的模式 优化器模式用于决定oracle在解析目标SQL时所选择的优化器类型,以及选择使用CBO时计算成本的侧重点。在oracle数据库中,优化器模式由参数OPTIMIZER_MODE的值决定,通常OPTIMIZER_MODE的值为RULE,CHOOSE,FIRST_ROWS_n(N=1、10、100、1000),FIRST_ROWS或ALL_ROWS。OPTIMIZER_MODE的值得各个含义如下:
1)RULE
RULE表示优化器使用RBO来解析目标SQL,此时目标SQL所涉及的各个对象的统计信息对于RBO来说将毫无意义。
2)CHOOSE
CHOOSE是oracle 9i中OPTIMIZER_MODE的默认值,他表示oracle在解析目标SQL时到底使用CBO还是RBO取决于目标SQL所涉及对象是否有统计信息。具体来说:只要目标SQL对象含有统计信息,即使用CBO,反之,使用RBO来解析目标SQL。
3)FIRST_ROWS_n(N=1、10、100、1000)
FIRST_ROWS_n(N=1、10、100、1000)可以是FIRST_ROWS_1、FIRST_ROWS_10、FIRST_ROWS_100、FIRST_ROWS_1000中的任意一个值,他表示oracle在解析目标SQL时,oracle会使用CBO来解析目标SQL,且此时CBO在计算各条执行路径的成本时的侧重点在于以最快相应速度返回前n条数据。
4)FIRST_ROWS
FIRST_ROWS是一个在oracle 9i中就过时的一个参数,他表示oracle在解析目标SQL时会联合使用CBO和RBO。在大部分情况下,oracle还是会选用CBO作为解析目标SQL,此时oracle的侧重点是以最快的相应速度返回前n行。在一些特俗情况下,oracle会选用RBO来解析目标SQL而不考虑成本。比如当OPTIMIZER_MODE为FIRST_ROWS时有一个内置的规则,就是oracle如果发现能用相关索引来避免排序,则oracle就会选择该索引所对应的路径而不考虑成本值。
5)ALL_ROWS
ALL_ROWS是oracle 10g及以后oracle的版本中OPTIMIZER_MODE的默认值,它表示oracle会使用CBO来解析目标SQL,此时CBO计算目标SQL的各个执行路径的成本的侧重点是最佳吞吐量。当OPTIMIZER_MODE为FIRST_ROWS时,CBO计算成本侧重于最快响应时间;当OPTIMIZER_MODE为ALL_ROWS时,CBO计算成本侧重于最佳吞吐量。
2、结果集(row source) 结果集是指包含指定执行结果的集合。对于优化器而言,结果集对应SQL执行计划的执行步骤。执行计划的各个步骤的输出结果集和输入结果集可以通过执行计划分析出。
3、访问数据的方法 优化器访问数据的方法有3种,一种是直接访问表;一种是访问索引,直接从索引中取值;另一种是先访问索引,再回表。
1)访问表的方法
访问表的方法2种:全表扫描;rowid扫描。
(1)全表扫描
全表扫面会从表所占用的第一个extent的第一个块开始扫描,一直到该表的最高水位线为止,这个范围的所有的数据块,oracle都会读到。
(2)rowid访问
Rowid访问是指oracle在访问目标表的数据时,直接通过数据所在的rowid去定位并访问这些数据。Oracle中rowid访问有两层含义:一是根据用户SQL输入的rowid值直接去读取数据记录;另一种是先去访问相关索引,然后根据访问索引所返回的rowid回表去读取具体的记录数。
对于oracle数据库中的堆表,可以通过oracle内置的rowid伪列得到对应的rowid值,然后我们可以通过dbms_rowid包中的相关方法(dbms_rowid.rowid_relative_fno:文件号;dbms_rowid.rowid_block_number:数据块号;dbms_rowid.rowid_row_number:数据块中行号)通过上述取得的rowid值取得数据行的实际物理位置。例:
SQL> select empno,ename,rowid, dbms_rowid.rowid_relative_fno(rowid)
| ‘_’ | dbms_rowid.rowid_block_number(rowid) | ‘_’ | dbms_rowid.rowid_row_number(rowid) localtion |
from emp;
EMPNO ENAME ROWID LOCALTION
######### SMITH AAAMfMAAEAAAAAgAAA 4_32_0
…………..
######### MILLER AAAMfMAAEAAAAAgAAN 4_32_13
14 rows selected.
2)访问索引的方法
使用B-TREE索引的优势有以下几点:
a、所有的叶子快都在同一层,即所有的叶子块距离根节点的距离是相同的。
b、Oracle保证所有的B-tree索引都是自平衡的,即不可能出现不同的索引叶子块不处于同一层的情况。
c、通过B-tree索引访问数据不会因为表数据量的增加效率明显降低,这也是走索引与全表扫描最大的区别。
(1)索引唯一性扫描:
索引唯一性扫描(index unique scan)是针对唯一性索引(unique index)的扫描。它仅仅适用于where条件是等值查询的目标SQL。
(2)索引范围扫描:
索引范围扫描(index range scan)适用于所有的B-tree索引,当扫描的对象是唯一性索引时,此时目标SQL的where条件一定是范围条件,当扫描的对象是非唯一性索引时,此时目标SQL的where条件没有限制。
(3)索引全扫描:
索引全扫描(index full scan)适用于所有类型的B-tree索引(唯一性索引和非唯一性索引),所谓索引全扫描是指要扫描索引的所有叶子块的所有行。这里需要注意的是索引全扫描要扫描索引的所有叶子块,但不是意味着要扫描索引的所有分支块。即默认情况下,索引全扫描从左到右访问索引的所有叶子块。因为索引是有序的,所以索引全扫描的结果也是有序的。索引全扫描既能达到排序的效果又能避免对目标索引的索引键值列的真正排序操作。默认情况下,索引全扫描的有序性决定了索引全扫描是不能够并行访问的,并且通常情况下索引全扫描使用的是单块读。通常情况下,索引全扫描是不需要回表的,所以索引全扫描适用于目标SQL的查询列全部是索引的键值列的情况。正常情况下,当索引的全部键值均为null时不入索引,这意味着oracle中能做索引全扫描的前提条件是目标索引至少有一列是not null的。
(4)索引快速扫描
索引快速扫描(index fast full scan)适用于所有类型的B-tree索引(唯一性索引和非唯一性索引),索引快速扫描要扫描索引的所有叶子块的所有行。索引快速扫描与索引全扫描有以下区别:
#索引快速扫描仅仅适用于CBO。
#索引快速扫描可以使用多块读,同时也可以并行执行。
#索引快速扫描的结果不一定是有序的。
(5)索引跳跃式扫描
索引跳跃式扫描(index skip scan)适用于所有复合类型的B-tree索引(包括唯一性索引与非唯一性索引),它使那些在where条件中没有对目标索引的前导列指定查询条件但同时又对该索引的非前导列指定了查询条件的目标SQL依然可以使用上述索引,这就像是扫描索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样。
索引跳跃式扫描对目标索引的所有前导列做了distinct遍历,其含义相当于对目标SQL做改写。Oracle中的索引跳跃式扫描仅仅适用于那些目标前导列的distinct值较少,后续非前导列的可选择性较好的目标SQL,因为索引跳跃式扫描的执行效率会随着目标索引的前导列的distinct值得增加而递减。
3)表连接
当优化器解析含有表连接的目标SQL时,它会根据目标SQL的SQL文本的写法来决定表连接的类型外,还必须决定如下的3个部分才能最终决定执行计划。
a、表连接顺序
不管目标SQL中有多少个表做链接,oracle在执行该SQL时只能两两做链接直到目标SQL中的所有表连接完毕。这里有两层含义:一是指俩个表做连接时,优化器要决定这两个表谁是驱动表,谁是被驱动表。二是优化器要决定哪两张表要先做连接,哪个表要随后最连接,哪个表最后做连接。
b、表连接的方法
Oracle数据库中表连接的方法有:排序合并连接、嵌套循环连接、哈希连接和笛卡尔连接。所以优化器要选择两张表要以哪种方式做连接。
c、访问单表的方法
优化器在决定最终执行计划时,除了考虑表连接顺序以及表连接方法外还要决定以索引方式访问具体表数据还是以全表扫描方式访问表数据,即优化器还要决定访问单表的方法。
(1)表连接类型
Oracle数据库中表连接分为内连接和外链接两种类型。
(a)内连接(inner join)
内连接是指表连接的连接结果只包含那些完全满足连接条件的记录。对于SQL而言,只要其where条件中没有定义那些外连接关键字(如left outer join、right outer join、full outer join)外的所有连接类型定义为内连接。
(b)外连接(outer join)
外连接是对内连接的一种扩展,它是指表连接的结果除了包括那些满足条件的连接结果外还包含驱动表中不满足连接条件的结果。标准SQL的外连接分为左连接(left outer join)、右连接(righr outer join)、全连接(full outer join)三种。全连接可以近似看成是先做左连接union再做右连接,这里所说的近似是因为oracle实际的处理并不是这样做的,因为union要对结果集进行排序,而全连接并不需要排序。
对于外连接而言,除了表连接的条件之外的额外条件在目标SQL的SQL文本中所处的位置可能会影响该SQL的执行结果,而内连接没有限制。
(2)表连接方法
优化器在解析含有表连接的目标SQL时,当根据目标SQL的SQL文本决定了表的连接类型后,接下来还要决定表的连接方法。Oracle中两表的连接方法有“排序合并”,“嵌套循环”,“哈希连接”,“笛卡尔连接”四种。
(a)排序合并连接(sort merge join)
排序合并连接是一种两表做表连接时用排序操作(sort)和合并操作(merge)来得到表连接结果的方法。排序合并的执行顺序如下(假设连接表为t1和t2):
(a.1)首先以目标SQL中的谓语条件去访问表t1,然后对结果按连接列进行排序,排好序的结果记为结果集1.
(a.2)然后以目标SQL中的谓语条件去访问表t2,然后对结果按连接列进行排序,排好序的结果记为结果集2.
(a.3)然后对结果集1和结果集2进行合并操作,从中取匹配记录作为排序合并的最终结果。
排序合并连接的适用场景总结入下:
b.1)通常情况下,排序合并连接的执行效率不如哈希连接,但是前者使用范围广,因为hash连接只适用于等值连接,而排序合并还适用于其他连接(比如<、>、<=、>=)。
b.2)通常情况下,排序合并不适合OLTP类型连接,本质是排序对于OLTP类型来说成本是昂贵的。但是,如果能避免排序,也是可以适合于OLTP系统的。
(b)嵌套循环连接(nested loops join)
嵌套循环连接是两个表在做连接时采用两层嵌套循环(外层循环和内层循环)的方式来得到表连接结果的方法。嵌套循环的执行顺序如下(假设连接表为t1和t2):
(a.1)首先,优化器会根据一定的规则来决定t1和t2谁是驱动表、谁是被驱动表,驱动表做外层循环,被驱动表做内层循环,这里假设t1是驱动表,t2是被驱动表。
(a.2)接着以目标SQL中的谓语条件去访问驱动表t1,所得到的结果集记为结果集1.
(a.3)然后遍历驱动结果集1及遍历被驱动表2,即取出结果集1中的第一条记录,然后按照连接条件去遍历t2,查看是否有匹配记录;接着取出结果集1的第二条记录,按照同样的方法去遍历表t2,查看匹配记录,直到结果集1中所有的记录全部遍历完成为止。
嵌套循环连接的适用场景总结入下:
b.1)如果驱动表所对应的驱动结果集的记录较少,同时被驱动表的连接列上又存在唯一性索引(或者被驱动表的连接列上存在选择性较好的非唯一性索引),那么此时使用嵌套循环的执行效率会非常高。如果驱动表所对应的驱动结果集数量较多,那么即使被驱动表的连接列上存在唯一性索引,那么执行效率也不会很高。
b.2)只要驱动结果集的记录较少,那么就具备了做嵌套循环的前提条件,而驱动表所对应的驱动结果集是在对驱动表应用了目标SQL之后所得到的结果集,所以大表也会可以作为驱动表的。
b.3)嵌套循环可以实现快速响应。
嵌套循环在访问被驱动表时,如果被驱动表有索引,将会采用单块读的方式访问索引,同时,如果返回结果集列不在索引中取得,嵌套循环连接也要采用单块读的方式回表。Oracle 11g中,oracle引入了向量I/O(vector i/o),oracle就可以将原来一批单块读所消耗的I/O组合起来,然后用一个向量I/O去批量处理它们,使用这种方法达到单块读的数量不下降的情况下减少这些单块读所需要耗费的物理I/O数量,也就提高了嵌套循环的效率。体现在执行计划上,你会发现在oracle 11g中本来一次嵌套循环可以处理完毕的SQL,但在执行计划中嵌套循环连接的数量由原来的1个变为现在的2个。
(c)hash连接(hash join)
Hash连接是指两表在做连接时主要依靠哈希算法来取得结果集的方法。Oracle 7.3中引入了hash连接,在oracle 10g版本中,优化器是否启用哈希连接取决于隐藏_HASH_JOIN_ENABLED,而在oracle 10g前,优化器是否引用hash连接取决于参数HASH_JOIN_ENABLED。Hash连接的执行顺序如下(假设连接表为t1和t2):
a.1)首先,oracle会根据参数hash_area_size、db_block_size、_hash_multiblock_io_count的值来决定hash partition的数量(hash partition是一种逻辑上的概念,它实际上是一组hash bucket的集合,所有的hash partition的集合就成为hash table。)。
a.2)表t1和t2施加了目标SQL的谓语条件后,得到的结果中数量较少的那个结果集会被oracle选为哈希连接的驱动结果集,这里假设t1结果集为驱动结果集,记为s,t2结果集较多,记为b。
a.3)接着oracle会遍历s,读取s中的每一条记录,并对每一条记录按照t1中的连接列做哈希运算,这个哈希运算会使用2个hash内置函数,这两个hash内置函数同时对连接列计算哈希值,我们把2个函数分别记为hash_func_1和hash_func_2,他们所计算的值分别为hash_value_1和hash_value_2。
a.4)然后oracle会按照hash_value_1的值把相应的s中对应的记录存储在不同的hash partition的不同hash bucket里,同时跟该记录记录在一起的还有该hash_func_2计算出来的hash_value_2。注意,存储在hash bucket里的并不是完整的行记录,只需要存储于目标SQL相关的查询列和连接列足够,我们把s对应的hash partition记为si。
a.5)在构建si的同时,oracle会构建一个bit map索引,这个索引用来记录每个hash bucket是否有记录。
a.6)如果s的结果集很大,就有可能出现pga被填满的情况,此时oracle会将工作区中记录最多的hash partition写到磁盘上,接着oracle会继续构建hash table,在继续构建的过程中,如果工作区内存满了,oracle会重复上述工作。如果构建的hash partition已经被写会磁盘,则此时oracle回去更新磁盘上的hash partition,即把hash_value_2直接加到这个已经位于磁盘上的hash partition对应的hash bucket中。极端请况可能出现某个hash partition的部分记录还在内存中,该hash partition的剩余部分已经被写道磁盘上。
a.7)上述构建s所对应的hash table的过程会一直持续下去,知道遍历完s中的所有记录为止。
a.8)oralce会对所有si按照他们所包含的记录数排序,然后依次将排序好的数据尽可能存放到内存中,如果内存实在放不下,那些数据量交大的hash partition还是会被写到磁盘上。
a.9)oracle至此已经处理好s,接着开始处理b。
a.10)oracle会遍历b,读取b中的每一条记录,并按照t2的连接列做哈希运算,这个过程和步骤3一模一样。
a.11)上述过程会一直持续下去,直到遍历完所有数据为止。
a.12)至此oracle处理完所有内存中数据,接着处理硬盘上的数据。
a.13)因为构建si和bj时用了同样的hash函数,所以oracle处理磁盘上的数据时可以放心的匹配。即只有对应的hash partition number值相同的si和bj才可能会产生满足条件的记录。
a.14)对于每一个sn和bn,他们中结果集较少的会被当做驱动结果集。继续匹配。
a.15)步骤14中存在匹配记录,则该匹配记录也会作为满足目标SQL的连接条件的记录返回。
a.16)上述过程会一直持续下去,直到遍历完所有sn和bn为止。
hash连接的适用场景总结入下:
b.1)哈希连接不一定需要排序,大部分情况下。
b.2)哈希连接的驱动表所对应的选择列可选择性应尽可能好,因为这个可选择性会影响到hash bucket的记录数,而hash bucket的记录数又会直接影响从该hash backet中查找匹配记录数的效率。不好的体现在于哈希连接执行了很长时间都没有结束,数据库所在的数据库服务器cpu占用率很高,但是目标SQL所消耗的逻辑读很低,因为此时大部分时间都浪费在了遍历上述hash bucket的记录上,而遍历hash bucket的记录发生在pga,所以不消耗逻辑读。
b.3)哈希连接只适用于CBO,同时哈希连接也只适用于等值连接。
b.4)哈希连接适合于小表和大表做表连接且连接结果集记录数较多的情形,特别是在小表的连接列可选择性特别好的情况下,这时hash连接的执行时间近似于对大表的执行时间。
b.5)当两表做hash连接时,如果在施加了目标SQL指定的谓语条件后所得到的数量较小的那个结果集所对应的hash table能够完全被容纳在内存中(pga),此时hash连接执行效率会非常高。
(d)笛卡尔连接(cross join)
笛卡尔连接又称笛卡尔积(cartesian product),它是一种两表在做连接时没有任何连接条件的表连接方法。笛卡尔积是一种特殊的合并连接,这里的合并连接和排序合并类似,只不过笛卡尔连接不需要排序,并且执行合并时并没有连接条件。的执行顺序如下(假设连接表为t1和t2):
a.1)首先以目标SQL中制定的谓语条件访问表t1,此时所得到的结果集记为结果集1,结果集1的记录数为m。
a.2)其次以目标SQL中制定的谓语条件访问表t2,此时所得到的结果集记为结果集2,结果集1的记录数为n。
a.3)最后结果集1和结果集2执行合并操作。笛卡尔积连接结果记录数为m*n。
笛卡尔连接总结如下:
b.1)笛卡尔连接出现一般都是目标SQL中漏写了连接条件,所以笛卡尔连接一般都是不好的,除非刻意这样做(比如有时利用笛卡尔积来减少对目标SQL中大表的全表扫描次数)。
b.2)有时候笛卡尔连接的出现时因为目标SQL中使用了ordered hint,同时该SQL中文本委会相邻的两个表又没有直接的连接条件。
b.3)有时候笛卡尔连接出现时因为统计信息不准。
(4)反连接(anti join)
oracle中没有专门的关键词定义反连接,形如“t1.x anti= t2.y”来表示反连接,其中t1为驱动表,t2是被驱动表,反连接条件为t1.x = t2.y。这里“t1.x anti= t2.y”的含义是只要表t2中由满足条件的“t1.x = t2.y”的记录存在,则t1表中满足条件的“t1.x = t2.y”的记录就会被丢弃,最后返回的记录就是t1表中那些不满足条件“t1.x = t2.y”的记录。目标SQL中那些外部where条件为not exists、not in或<>all的子查询在做子查询展开时常常会被转换为对应的反连接。(即返回在t2中满足条件但是不在t1中满足条件的记录。)
例:t1和t2在在各自的连接列col2上没有null值情况下:
select * from t1 where col2 not in (select col2 from t2);
或
select * from t1 where col2<>all(select col2 from t2);
或
select * from t1 where not exists (select 1 from t2 where col2=t1.col2);
对于连接表有null值得情况说明如下:
(a)t1和t2表在各自的连接列col2上一但有null值,以上例子的执行结果将不完全等价。
(b)not in和<>all对null值敏感,这意味着not in和<>all后面的子查询或常量一但出现null值,则整个sql的执行结果就是null。
(c)not exsts对null值不敏感,这意味着not exsts后面值出现null对结果不会有什么影响。
oracle的处理办法:为了解决not in和<>all对null值敏感的问题,oracle推出了改良的反连接,这种反连接能够处理null值,oracle称其为null-aware anti jion,对应执行计划“….. anti na”,其中na就是null aware的缩写。在oracle 11gR2中,oralce是否启用null-aware anti join受隐藏_optimizer_null_aware_antijoin控制,其默认值为true。
(5)半连接(semi join)
oracle中没有专门的关键词定义半连接,形如“t1.x semi= t2.y”来表示半连接,其中t1为驱动表,t2是被驱动表,反连接条件为t1.x = t2.y。这里“t1.x anti= t2.y”的含义是只要表t2中找到一条满足的“t1.x = t2.y”的记录存在,则马上停止搜索t2,并直接返回t1表中满足条件的“t1.x = t2.y”的记录,最后返回的记录就是t1表中那些满足条件“t1.x = t2.y”的记录。也就是说,t2中满足条件t1.x = t2.y的记录有多条,t1表也只会返回一条记录。所以半连接和普通的内连接不同,半连接会去重。目标SQL中那些外部where条件为exists、in或<>any的子查询在做子查询展开时常常会被转换为对应的半连接。(即返回在t2中满足条件并且在t1中满足条件的记录。)
例:
select * from t1 where col2 in (select col2 from t2);
或
select * from t1 where col2<>any(select col2 from t2);
或
select * from t1 where exists (select 1 from t2 where col2=t1.col2);
(6)星型连接(star join)
星型连接通常应用于数据仓库类型应用,他是一个单个事实表外键和多个维度表主键之间的连接,维度表通过连接条件和事实表连接,维度表之间一般没有直接连接关系。一般事实表的外键上还会存在bit map索引。
数据库优化
系统调整
SQL语句优化
不要用*代替列名
尽量减少表查询的次数
用not exists代替in/not in
用not exists代替distinct
有效利用共享游标
以合理的方式使用函数
表的连接方法
选择from表的顺序
小表放在最右
选择驱动表
where子句的连接顺序
能够过滤掉最多记录的的条件放在最右
## 索引
简介 1.说明 1)索引是数据库对象之一,用于加快数据的检索,类似于书籍的索引。在数据库中索引可以减少数据库程序查询结果时需要读取的数据量,类似于在书籍中我们利用索引可以不用翻阅整本书即可找到想要的信息。 2)索引是建立在表上的可选对象;索引的关键在于通过一组排序后的索引键来取代默认的全表扫描检索方式,从而提高检索效率 3)索引在逻辑上和物理上都与相关的表和数据无关,当创建或者删除一个索引时,不会影响基本的表; 4)索引一旦建立,在表上进行DML操作时(例如在执行插入、修改或者删除相关操作时),oracle会自动管理索引,索引删除,不会对表产生影响 5)索引对用户是透明的,无论表上是否有索引,sql语句的用法不变 6)oracle创建主键时会自动在该列上创建索引
索引原理
- 若没有索引,搜索某个记录时(例如查找name=’wish’)需要搜索所有的记录,因为不能保证只有一个wish,必须全部搜索一遍
- 若在name上建立索引,oracle会对全表进行一次搜索,将每条记录的name值哪找升序排列,然后构建索引条目(name和rowid),存储到索引段中,查询name为wish时即可直接查找对应地方 3.创建了索引并不一定就会使用,oracle自动统计表的信息后,决定是否使用索引,表中数据很少时使用全表扫描速度已经很快,没有必要使用索引
索引使用(创建、修改、删除、查看) 1.创建索引语法
CREATE [UNIQUE] | [BITMAP] INDEX index_name –unique表示唯一索引 ON table_name([column1 [ASC|DESC],column2 –bitmap,创建位图索引 [ASC|DESC],…] | [express]) [TABLESPACE tablespace_name] [PCTFREE n1] –指定索引在数据块中空闲空间 [STORAGE (INITIAL n2)] [NOLOGGING] –表示创建和重建索引时允许对表做DML操作,默认情况下不应该使用 [NOLINE] [NOSORT]; –表示创建索引时不进行排序,默认不适用,如果数据已经是按照该索引顺序排列的可以使用
2.修改索引 1)重命名索引 alter index index_sno rename to bitmap_index; 2) 合并索引(表使用一段时间后在索引中会产生碎片,此时索引效率会降低,可以选择重建索引或者合并索引,合并索引方式更好些,无需额外存储空间,代价较低) alter index index_sno coalesce; 3)重建索引 方式一:删除原来的索引,重新建立索引 方式二: alter index index_sno rebuild; 3.删除索引 drop index index_sno; 4.查看索引
select index_name,index-type, tablespace_name, uniqueness from all_indexes where table_name =’tablename’;
– eg:
create index index_sno on student(‘name’);
select * from all_indexes where table_name=’student’;
索引分类
- B树索引(默认索引,保存讲过排序过的索引列和对应的rowid值) 1)说明: 1.oracle中最常用的索引;B树索引就是一颗二叉树;叶子节点(双向链表)包含索引列和指向表中每个匹配行的ROWID值 2.所有叶子节点具有相同的深度,因而不管查询条件怎样,查询速度基本相同 3.能够适应精确查询、模糊查询和比较查询 2)分类: UNIQUE,NON-UNIQUE(默认),REVERSE KEY(数据列中的数据是反向存储的) 3)创建例子 craete index index_sno on student(‘sno’);
4)适合使用场景: 列基数(列不重复值的个数)大时适合使用B数索引
- 位图索引 1)说明: 1.创建位图索引时,oracle会扫描整张表,并为索引列的每个取值建立一个位图(位图中,对表中每一行使用一位(bit,0或者1)来标识该行是否包含该位图的索引列的取值,如果为1,表示对应的rowid所在的记录包含该位图索引列值),最后通过位图索引中的映射函数完成位到行的ROWID的转换 2)创建例子 create bitmap index index_sno on student(sno); 3) 适合场景: 对于基数小的列适合简历位图索引(例如性别等)
3.单列索引和复合索引(基于多个列创建) 1) 注意: 即如果索引建立在多个列上,只有它的第一个列被where子句引用时,优化器才会使用该索引,即至少要包含组合索引的第一列
- 函数索引 1)说明: 1. 当经常要访问一些函数或者表达式时,可以将其存储在索引中,这样下次访问时,该值已经计算出来了,可以加快查询速度 2. 函数索引既可以使用B数索引,也可以使用位图索引;当函数结果不确定时采用B树索引,结果是固定的某几个值时使用位图索引 3. 函数索引中可以水泥用len、trim、substr、upper(每行返回独立结果),不能使用如sum、max、min、avg等
2)例子: create index fbi on student (upper(name)); select * from student where upper(name) =’WISH’;
索引建立原则总结 1. 如果有两个或者以上的索引,其中有一个唯一性索引,而其他是非唯一,这种情况下oracle将使用唯一性索引而完全忽略非唯一性索引 2. 至少要包含组合索引的第一列(即如果索引建立在多个列上,只有它的第一个列被where子句引用时,优化器才会使用该索引) 3. 小表不要简历索引 4. 对于基数大的列适合建立B树索引,对于基数小的列适合简历位图索引 5. 列中有很多空值,但经常查询该列上非空记录时应该建立索引 6. 经常进行连接查询的列应该创建索引 7. 使用create index时要将最常查询的列放在最前面 8. LONG(可变长字符串数据,最长2G)和LONG RAW(可变长二进制数据,最长2G)列不能创建索引 9.限制表中索引的数量(创建索引耗费时间,并且随数据量的增大而增大;索引会占用物理空间;当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度) 注意事项
- 通配符在搜索词首出现时,oracle不能使用索引,eg:
–我们在name上创建索引;
create index index_name on student(‘name’);
–下面的方式oracle不适用name索引
select * from student where name like ‘%wish%’;
–如果通配符出现在字符串的其他位置时,优化器能够利用索引;如下:
select * from student where name like ‘wish%’;
- 不要在索引列上使用not,可以采用其他方式代替如下:(oracle碰到not会停止使用索引,而采用全表扫描)
select * from student where not (score=100);
select * from student where score <> 100;
–替换为
select * from student where score>100 or score <100
- 索引上使用空值比较将停止使用索引, eg: select * from student where score is not null; 各种Oracle索引类型介绍 逻辑上: Single column 单行索引 Concatenated 多行索引 Unique 唯一索引 NonUnique 非唯一索引 Function-based函数索引 Domain 域索引
物理上: Partitioned 分区索引 NonPartitioned 非分区索引 B-tree: Normal 正常型B树 Rever Key 反转型B树 Bitmap 位图索引
索引结构: B-tree: 适合与大量的增、删、改(OLTP); 不能用包含OR操作符的查询; 适合高基数的列(唯一值多) 典型的树状结构; 每个结点都是数据块; 大多都是物理上一层、两层或三层不定,逻辑上三层; 叶子块数据是排序的,从左向右递增; 在分支块和根块中放的是索引的范围; Bitmap: 适合与决策支持系统; 做UPDATE代价非常高; 非常适合OR操作符的查询; 基数比较少的时候才能建位图索引;
树型结构: 索引头 开始ROWID,结束ROWID(先列出索引的最大范围) BITMAP 每一个BIT对应着一个ROWID,它的值是1还是0,如果是1,表示着BIT对应的ROWID有值
- b-tree索引 Oracle数据库中最常见的索引类型是b-tree索引,也就是B-树索引,以其同名的计算科学结构命名。CREATE INDEX语句时,默认就是在创建b-tree索引。没有特别规定可用于任何情况。
- 位图索引(bitmap index) 位图索引特定于该列只有几个枚举值的情况,比如性别字段,标示字段比如只有0和1的情况。
- 基于函数的索引 比如经常对某个字段做查询的时候是带函数操作的,那么此时建一个函数索引就有价值了。
- 分区索引和全局索引 这2个是用于分区表的时候。前者是分区内索引,后者是全表索引
- 反向索引(REVERSE) 这个索引不常见,但是特定情况特别有效,比如一个varchar(5)位字段(员工编号)含值 (10001,10002,10033,10005,10016..) 这种情况默认索引分布过于密集,不能利用好服务器的并行 但是反向之后10001,20001,33001,50001,61001就有了一个很好的分布,能高效的利用好并行运算。 6.HASH索引 HASH索引可能是访问数据库中数据的最快方法,但它也有自身的缺点。集群键上不同值的数目必须在创建HASH集群之前就要知道。需要在创建HASH集群的时候指定这个值。使用HASH索引必须要使用HASH集群。
1.逻辑结构: 所谓逻辑结构就是数据与数据之间的关联关系,准确的说是数据元素之间的关联关系。 注:所有的数据都是由数据元素构成,数据元素是数据的基本构成单位。而数据元素由多个数据项构成。 逻辑结构有四种基本类型:集合结构、线性结构、树状结构和网络结构。也可以统一的分为线性结构和非线性结构。 2.物理结构: 数据的物理结构就是数据存储在磁盘中的方式。官方语言为:数据结构在计算机中的表示(又称映像)称为数据的物理结构,或称存储结构。它所研究的是数据结构在计算机中的实现方法,包括数据结构中元素的表示及元素间关系的表示。 而物理结构一般有四种:顺序存储,链式存储,散列,索引 3.逻辑结构的物理表示: 线性表的顺序存储则可以分为静态和非静态:静态存储空间不可扩展,初始时就定义了存储空间的大小,故而容易造成内存问题。 线性表的链式存储:通过传递地址的方式存储数据。 单链表:节点存储下一个节点的地址————–>单循环链表:尾节点存储头结点的地址 双链表:节点存储前一个和后一个节点的地址,存储两个地址。—————->双循环链表:尾节点存储头结点的地址。 4.高级语言应用: 数组是顺序存储 指针则是链式存储
理解oracle索引扫描类型的特点以及具体触发的条件,对于通过合理地使用索引,进行sql优化至关重要(例如组合索引的引导列的选择问题)。 在总结索引扫描类型前,需要再次强调关于索引特点的几个关键点:
- 对于单一列建立的索引,既单一列索引,b-tree中不保存索引列的null值信息
- 对于多个列建立的索引,既组合列索引,b-tree中会连同其他非null值列,保留该列null值记录;对于一条记录中,组合索引全部列都是null值,组合索引中不会记录(从之前的实验看,此时的执行计划是全表扫描)
- 创建主键约束以及唯一键约束,或自动创建唯一索引
- create index创建的索引属于普通索引(非唯一索引)
- create unique index创建的索引属于唯一索引 其他的一些特点,可参阅前面的几篇总结。 此外,为避免概念的混淆,再次说明一下:“索引类型”主要探讨的是索引的几种类别的问题,而“索引扫描类型”主要探讨的是索引扫描的几种具体实现方法的问题。
1、索引扫描类型概述 Oracle提供了五种索引扫描类型,根据具体索引类型、数据分布、约束条件以及where限制的不同进行选择:
- 索引唯一扫描(index unique scan)
- 索引范围扫描(index range scan)
- 索引跳跃扫描(index skip scan)
- 索引全扫描(index full scan)
- 索引快速扫描(index fast full scan)
2、索引唯一扫描(index unique scan) 索引唯一扫描,仅仅针对唯一索引的扫描,且仅适用于等值(=)条件的查询。从结果集看,至多返回一条记录。
具体情况分析:
- 对于单一列建立的索引(单一索引),当索引属于唯一索引,在检索条件中,使用该索引进行检索,且检索值不是null时,会使用“索引唯一扫描”
- 对于单一列建立的索引(单一索引),当索引属于唯一索引,在检索条件中,使用该索引进行检索,且检索值等于null时,会使用“全表扫描”
- 对于多个列建立的索引(组合索引),当索引属于唯一索引,且检索条件中,使用该组合索引进行检索,且检索列使用组合索引涉及的所有列时,会使用“索引唯一扫描”
需要注意:
- 对于组合索引,若其中涉及的部分列或则所有列,在同一条记录上存在null值。当使用完整的组合索引列作为检索条件,且使用该null值进行该条记录的检索时,不会使用“索引唯一扫描”
示例:
–创建唯一索引 Yumiko@Sunny >create unique index ind_test_normal on test_normal(empno,ENAME,SAL); Index created.
Yumiko@Sunny >select INDEX_NAME,INDEX_TYPE,TABLE_NAME,UNIQUENESS from user_indexes where TABLE_NAME=’TEST_NORMAL’;
INDEX_NAME INDEX_TYPE TABLE_NAME UNIQUENES ————————- ————————— ————— ——— IND_TEST_NORMAL NORMAL TEST_NORMAL UNIQUE
–查询记录并查看执行计划 Yumiko@Sunny >select * from TEST_NORMAL where empno=7369 and ENAME=’SMITH’ and sal=800;
EMPNO ENAME JOB SAL ---------- ---------- --------- ----------
7369 SMITH CLERK 800
Execution Plan
Plan hash value: 1399315988 —————————————————————————————— | Id | Operation | Name | Rows | Bytes|Cost (%CPU)| Time | —————————————————————————————— | 0 | SELECT STATEMENT | | 1| 39| 1 (0)| 00:00:01| | 1 | TABLE ACCESS BY INDEX ROWID| TEST_NORMAL | 1| 39| 1 (0)| 00:00:01| |* 2 | INDEX UNIQUE SCAN | IND_TEST_NORMAL| 1| | 0 (0)| 00:00:01| —————————————————————————————— Predicate Information (identified by operation id): ————————————————— 2 - access(“EMPNO”=7369 AND “ENAME”=’SMITH’ AND “SAL”=800)
Statistics
0 recursive calls
0 db block gets
2 consistent gets
16 physical reads
0 redo size
581 bytes sent via SQL*Net to client
458 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
3、索引范围扫描(index range scan) 索引范围扫描,不仅可以针对唯一索引,也可以针对非唯一索引。从结果集看,可以是一条记录,也可以是多条记录。
具体情况分析:
- 对于单一列建立的索引(单一索引),当索引属于唯一索引,在检索条件中,使用该索引进行检索,且使用范围的操作符(>,<,>=,<=,between),会使用“索引范围扫描”。
- 对于单一列建立的索引(单一索引),当索引属于非唯一索引,在检索条件中,使用该索引进行检索,且检索值不是null值,会使用“索引范围扫描”。
- 对于多个列建立的索引(组合索引),当索引属于唯一索引,在检索条件中,使用该索引进行检索,且检索列使用组合索引涉及的部分列,但必须存在组合索引的引导列(创建组合索引时指定的第一列)时,会使用“索引范围扫描”。
- 对于多个列建立的索引(组合索引),当索引属于非唯一索引,在检索条件中,使用该索引进行检索,检索列涉及组合索引的部分列或者全部列,但必须存在组合索引的引导列(创建组合索引时指定的第一列)时,会使用“索引范围扫描”。
需要注意:
- 对于组合索引,当一条记录的引导列存在null值,当检索条件中,针对该条记录,仅使用该引导列进行检索时,不会使用“索引范围扫描”。
- 对于组合索引,当一条记录的引导列存在null值,当检索条件中,针对该条记录,在使用该引导列进行检索的同时,使用组合索引的其他列且这些列针对该条记录的列值不是null值,一并进行检索,会使用“索引范围扫描”。
示例:
–创建普通索引 Yumiko@Sunny >create index ind_test_normal on test_normal(empno,ENAME,SAL); Index created.
–验证普通索引创建情况,确认为非唯一索引 Yumiko@Sunny >select INDEX_NAME,INDEX_TYPE,TABLE_NAME,UNIQUENESS from user_indexes where TABLE_NAME=’TEST_NORMAL’;
INDEX_NAME INDEX_TYPE TABLE_NAME UNIQUENES ————————- ————————— ————— ——— IND_TEST_NORMAL NORMAL TEST_NORMAL NONUNIQUE
–查询记录并观察执行计划,此时扫描类型为index range scan Yumiko@Sunny >select * from TEST_NORMAL where empno=7369 and ENAME=’SMITH’ and sal=800;
EMPNO ENAME JOB SAL ---------- ---------- --------- ----------
7369 SMITH CLERK 800
Execution Plan
Plan hash value: 67814702 ——————————————————————————————— | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ——————————————————————————————— | 0 | SELECT STATEMENT | | 1 | 18 | 2 (0)| 00:00:01| | 1 | TABLE ACCESS BY INDEX ROWID| TEST_NORMAL | 1 | 18 | 2 (0)| 00:00:01| |* 2 | INDEX RANGE SCAN | IND_TEST_NORMAL| 1 | | 1 (0)| 00:00:01| ——————————————————————————————— Predicate Information (identified by operation id): ————————————————— 2 - access(“EMPNO”=7369 AND “ENAME”=’SMITH’ AND “SAL”=800)
Statistics
0 recursive calls
0 db block gets
3 consistent gets
16 physical reads
0 redo size
717 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
4、索引跳跃扫描(index skip scan) 该索引扫描方式主要发生在组合索引上,且组合索引的引导列未被指定在检索条件中的情况下发生。 在组合索引中,无论该索引是否为唯一索引。当引导列未被指定在检索条件的情况下,可能会发生“索引跳跃扫描”
以下黄色字体内容摘引自http://book.51cto.com/art/201312/422441.htm 对于组合索引,在无前导列的情况下还能使用索引,是因为Oracle帮我们对该索引的前导列的所有distinct值做了遍历。 所谓的对目标索引的所有distinct值做遍历,其实际含义相当于对原目标SQL做等价改写(即把要用的目标索引的所有前导列的distinct值都加进来)。 例如:create index idx_employee on employee(gender,employee_id),表数据量10000行,其中gender列只有“M”跟“F”值。 当执行select * from employee where employee_id = 100时,相当于执行了等价改写,改写为: select * from employee where gender = ‘F’ and employee_id = 100 union all select * from employee where gender = ‘M’ and employee_id = 100; 因此,Oracle中的索引跳跃式扫描仅仅适用于那些目标索引前导列的distinct值数量较少、后续非前导列的可选择性又非常好的情形,因为索引跳跃式扫描的执行效率一定会随着目标索引前导列的distinct值数量的递增而递减。否则将执行全表扫描。
示例:
–查询测试表的总数据量 –该表总数据为22928行 Yumiko@Sunny >select count(*) from test;
COUNT(*)
22928
–查询测试表中owner列的列值数据分布情况 –从查询结果看,对于owner列,在22928行的数据中,只分布了3个不同的列值,数据数值的分布情况较为集中 Yumiko@Sunny >select count(distinct owner) from test;
COUNT(DISTINCTOWNER)
3
–查询测试表中object_id列的数值分布情况 –从查询结果看,对于object_id列,在22928行的数据中,分布了22912个不同的数值,该列整体的数值分布情况较为零散 Yumiko@Sunny >select count(distinct object_id) from test;
COUNT(DISTINCTOBJECT_ID)
22912
Yumiko@Sunny >desc test Name Null? Type ———————————————————————- OWNER VARCHAR2(30) OBJECT_NAME VARCHAR2(128) SUBOBJECT_NAME VARCHAR2(30) OBJECT_ID NUMBER DATA_OBJECT_ID NUMBER OBJECT_TYPE VARCHAR2(19) CREATED DATE LAST_DDL_TIME DATE TIMESTAMP VARCHAR2(19) STATUS VARCHAR2(7) TEMPORARY VARCHAR2(1) GENERATED VARCHAR2(1) SECONDARY VARCHAR2(1)
–以数值较为集中的owner作为组合索引的引导列,创建普通索引 Yumiko@Sunny >create index test on test(owner,OBJECT_ID); Index created.
Yumiko@Sunny >select INDEX_NAME,INDEX_TYPE,TABLE_NAME,UNIQUENESS from user_indexes where TABLE_NAME=’TEST’;
INDEX_NAME INDEX_TYPE TABLE_NAME UNIQUENES ————————- ——————- ————— ——— TEST NORMAL TEST NONUNIQUE
–收集测试表最新的统计信息 Yumiko@Sunny >analyze table test compute statistics for table for all columns for all indexes; Table analyzed.
–清空buffer cache缓冲池,保证无测试表的数据块存在在内存中,防止影响到测试结果 Yumiko@Sunny >alter system flush buffer_cache; System altered.
–使用之前创建的组合索引,以组合索引非引导作为条件查询列进行条件查询 –从执行计划看,oracle用到了索引扫描,而且采用index skip scan的方式进行扫描 Yumiko@Sunny >select * from test where object_id=3;
Execution Plan
Plan hash value: 2389257771 ———————————————————————————- | Id | Operation | Name | Rows | Bytes| Cost (%CPU)| Time | ———————————————————————————- | 0 | SELECT STATEMENT | | 1 | 86| 5 (0)| 00:00:01| | 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 86| 5 (0)| 00:00:01| |* 2 | INDEX SKIP SCAN | TEST | 1 | | 4 (0)| 00:00:01| ———————————————————————————- Predicate Information (identified by operation id): ————————————————— 2 - access(“OBJECT_ID”=3) filter(“OBJECT_ID”=3)
Statistics
0 recursive calls
0 db block gets
6 consistent gets
24 physical reads
0 redo size
1402 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
–删除之前的索引 Yumiko@Sunny >drop index test; Index dropped.
–以数值分布较为零散的object_id列作为引导列,再次创建普通索引 Yumiko@Sunny >create index test on test(OBJECT_ID,owner); Index created.
–收集测试表最新的统计信息 Yumiko@Sunny >analyze table test compute statistics for table for all columns for all indexes; Table analyzed.
–清空buffer cache缓冲池,避免影响数据测试 Yumiko@Sunny >alter system flush buffer_cache; System altered.
–使用上面刚刚创建的组合索引的非引导列owner作为条件查询列进行查询操作 –从执行计划看,此次oracle未选择走索引扫描,而是采用了全表扫描的方式 –到此,印证了之前对于index skip scan方式选择的说法 Yumiko@Sunny >select * from test where owner=’BI’; 8 rows selected.
Execution Plan
Plan hash value: 1357081020 ———————————————————————— | Id | Operation | Name | Rows | Bytes| Cost (%CPU)| Time | ———————————————————————— | 0 | SELECT STATEMENT | | 8 | 688| 74 (2)| 00:00:01| |* 1 | TABLE ACCESS FULL| TEST | 8 | 688| 74 (2)| 00:00:01| ———————————————————————— Predicate Information (identified by operation id): ————————————————— 1 - filter(“OWNER”=’BI’)
Statistics
1 recursive calls
0 db block gets
318 consistent gets
315 physical reads
0 redo size
1583 bytes sent via SQL*Net to client
469 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
8 rows processed
5、索引全扫描(index full scan) 对于索引全扫描,就是使用目标索引进行索引扫描时,会扫描所有索引叶块的所有索引行。 对于索引全扫描,只适用于CBO。 对于索引全扫描,使用单块读取的方式,有序读取索引块。 对于索引全扫描,从结果集看,结果全部源于索引块,而且由于已经按照索引键值顺序排序,因此不需要单独排序 对于索引全扫描,会话会产生db file sequential reads事件。
具体情况分析:
- 对于单一列建立的索引(单一索引),当该索引列有非空约束时,在具体检索中只检索该列全部数据,会使用“索引全扫描”。
- 对于单一列建立的索引(单一索引),当该索引列无非空约束时,在具体检索中只检索该列全部数据,且是对该列的统计(count)或者非空条件查询(is not null),会使用“索引全扫描”。
- 对于单一列建立的索引(单一索引),当该索引列无非空约束时,在具体检索中只检索该列全部数据,且是对该列的常规查询,不会使用“索引全扫描”。(这是因为对于oracle索引,对于列中存在的null值不记录在b-tree索引中)
- 对于多个列建立的索引(组合索引),当该索引列有非空约束时,在具体检索中只检索组合索引中涉及的全部列或者部分列的全部数据,会使用“索引全扫描”。
- 对于多个列建立的索引(组合索引),当该索引列无非空约束时,在具体检索中只检索组合索引中涉及的全部列或者部分列的全部数据,且是对这些相关列的统计(count)或者非空条件查询(is not null),会使用“索引全扫描”。
- 对于多个列建立的索引(组合索引),当该索引列无非空约束时,在具体检索中只检索组合索引中涉及的全部列或者部分列的全部数据,且是对该列的常规查询,不会使用“索引全扫描”。
示例:
–为测试表TEST_NORMAL的empno列添加非空约束 Yumiko@Sunny >alter table TEST_NORMAL modify(empno not null); Table altered.
–以empno列以及ename列作为组合,创建普通索引 Yumiko@Sunny >create index TEST_NORMAL_ind on TEST_NORMAL(empno,ename); Index created.
–查询上面组合索引涉及的ename列,该列不存在非空约束 –从执行计划看,oracle选择了index full scan的索引扫描方式,且结果集仅仅来源于索引块(没有根据rowid返回数据集的记录,说明无访问数据块) Yumiko@Sunny >select ename from TEST_NORMAL; 14 rows selected.
Execution Plan
Plan hash value: 2425626010 ———————————————————————————— | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ———————————————————————————— | 0 | SELECT STATEMENT | | 14 | 70 | 1 (0)| 00:00:01 | | 1 | INDEX FULL SCAN | TEST_NORMAL_IND | 14 | 70 | 1 (0)| 00:00:01 | ———————————————————————————— Statistics ———————————————————- 0 recursive calls 0 db block gets 2 consistent gets 8 physical reads 0 redo size 705 bytes sent via SQLNet to client 469 bytes received via SQLNet from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 14 rows processed
6、索引快速扫描(index fast full scan) 对于索引快速扫描,就是使用目标索引进行索引扫描时,会扫描所有索引叶块的所有索引行。 对于索引快速扫描,只适用于CBO。 对于索引快速扫描,使用多块读取的方式,读取索引块。(这种方式相较于索引全扫描,获取数据的效率更高) 对于索引快速扫描,从结果集看,结果全部源于索引块,但数据结果不一定有序。 对于索引快速扫描,会话会产生db file scattered reads事件。
具体情况分析: 参阅上面的索引全扫描,两者所谓的同宗,只是不同的需求(对于结果的响应速度或是数据序列,当然CBO优化器也会进行内部的计算评估选取最优执行路径),产生的不同的执行结果,下面的示例会展示
示例:
–查询测试表的数据量,显示此表有22928行数据 Yumiko@Sunny >select count(*) from test;
COUNT(*)
22928
–确认数据列中不含非空约束 Yumiko@Sunny >desc test Name Null? Type ——————————————————————————– OWNER VARCHAR2(30) OBJECT_NAME VARCHAR2(128) SUBOBJECT_NAME VARCHAR2(30) OBJECT_ID NUMBER DATA_OBJECT_ID NUMBER OBJECT_TYPE VARCHAR2(19) CREATED DATE LAST_DDL_TIME DATE TIMESTAMP VARCHAR2(19) STATUS VARCHAR2(7) TEMPORARY VARCHAR2(1) GENERATED VARCHAR2(1) SECONDARY VARCHAR2(1)
–针对object_id列,创建普通索引 Yumiko@Sunny >create index test on test(object_id); Index created.
–确认上面创建的索引为非唯一索引 Yumiko@Sunny >select INDEX_NAME,INDEX_TYPE,TABLE_NAME,UNIQUENESS from user_indexes where TABLE_NAME=’TEST’;
INDEX_NAME INDEX_TYPE TABLE_NAME UNIQUENES
TEST NORMAL TEST NONUNIQUE
–清空buffer_cache缓冲池数据,防止造成测试的影响 Yumiko@Sunny >alter system flush buffer_cache; System altered.
–清空shared pool缓冲池数据,防止对测试造成影响 Yumiko@Sunny >alter system flush shared_pool; System altered.
–收集测试表最新的统计信息 Yumiko@Sunny >analyze table test compute statistics for table for all columns for all indexes; Table analyzed.
–打开会话追踪,仅查看执行计划 Yumiko@Sunny >set autotrace trace
–查询索引列object,同时使用is not null作为查询条件。 –由于b-tree索引中不记录null值信息,而且该列不存在非空约束,通过not null条件指定,让oracle不必考虑null值。 –从执行计划看,由于读取的数据量很大且不用排序,oracle选择了更快的多块读方式的index fast full scan,尽快获取数据。 –同样的,此时未出现access by index rowid的情况,说明未查询数据块,仅仅查询了索引块。 Yumiko@Sunny >select object_id from test where object_id is not null; 22928 rows selected.
Execution Plan
Plan hash value: 1645531115 —————————————————————————– | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | —————————————————————————– | 0 | SELECT STATEMENT | | 23290 | 295K| 14 (0)| 00:00:01 | |* 1 | INDEX FAST FULL SCAN| TEST | 23290 | 295K| 14 (0)| 00:00:01 | —————————————————————————–
Predicate Information (identified by operation id):
1 - filter(“OBJECT_ID” IS NOT NULL)
Statistics
0 recursive calls
0 db block gets
1582 consistent gets
53 physical reads
0 redo size
502642 bytes sent via SQL*Net to client
17277 bytes received via SQL*Net from client
1530 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
22928 rows processed
–修改上面的查询,增加排序操作。 –从执行计划看,由于此次增加了排序操作,oracle选择了偏向有序读取的index full scan的方式进行扫描。 –同样的,此次未查询数据块(不存在access by index rowid)。 Yumiko@Sunny >select object_id from test where object_id is not null order by object_id; 22928 rows selected.
Execution Plan
Plan hash value: 3883652822 ————————————————————————- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ————————————————————————- | 0 | SELECT STATEMENT | | 23290 | 295K| 60 (2)| 00:00:01 | |* 1 | INDEX FULL SCAN | TEST | 23290 | 295K| 60 (2)| 00:00:01 | ————————————————————————- Predicate Information (identified by operation id): ————————————————— 1 - filter(“OBJECT_ID” IS NOT NULL)
Statistics
0 recursive calls
0 db block gets
1578 consistent gets
64 physical reads
0 redo size
502642 bytes sent via SQL*Net to client
17277 bytes received via SQL*Net from client
1530 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
22928 rows processed
–再次修改查询,取消not null条件查询以及排序操作。 –此时,对于没有非空约束的object_id列,增加了null值的可能性,而b-tree索引不保存null信息。 –此次,oracle选择了全表扫描的方式。 Yumiko@Sunny >select object_id from test; 22928 rows selected.
Execution Plan
Plan hash value: 1357081020 ————————————————————————– | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ————————————————————————– | 0 | SELECT STATEMENT | | 22928 | 91712 | 74 (2)| 00:00:01 | | 1 | TABLE ACCESS FULL| TEST | 22928 | 91712 | 74 (2)| 00:00:01 | ————————————————————————– Statistics ———————————————————- 1 recursive calls 0 db block gets 1830 consistent gets 315 physical reads 0 redo size 415626 bytes sent via SQLNet to client 17277 bytes received via SQLNet from client 1530 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 22928 rows processed
有效使用索引
索引列的选择
where从句频繁使用的列
频繁用于表连接的列
不要将频繁修改的列用作索引
用于函数中的列应当考虑建立函数索引
复合索引有时比单列索引有更好的性能
避免对大表的全表扫描
导致全表扫描的情况
查询的表没有索引
需要返回所有的行
条件中有LIKE且使用了%
对索引列使用了函数
条件中有IS NULL或IS NOT NULL
监视索引是否被使用
alter index idx_name monitoring usage;
(1) 选择最有效率的表名顺序(只在基于规则的优化器中有效):
ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表.
(2) WHERE子句中的连接顺序.:
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.
(3) SELECT子句中避免使用 ‘ * ‘:
ORACLE在解析的过程中, 会将’*‘ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间
(4) 减少访问数据库的次数:
ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等;
(5) 在SQL*Plus , SQL*Forms和Pro*C中重新设置ARRAYSIZE参数, 可以增加每次数据库访问的检索数据量 ,建议值为200
(6) 使用DECODE函数来减少处理时间:
使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表.
(7) 整合简单,无关联的数据库访问:
如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)
(9) 用TRUNCATE替代DELETE:
当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息. 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执行删除命令之前的状况) 而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的信息.当命令运行后,数据不能被恢复.因此很少的资源被调用,执行时间也会很短. (译者按: TRUNCATE只在删除全表适用,TRUNCATE是DDL不是DML)
(10) 尽量多使用COMMIT:
只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少:
COMMIT所释放的资源:
a. 回滚段上用于恢复数据的信息.
b. 被程序语句获得的锁
c. redo log buffer 中的空间
d. ORACLE为管理上述3种资源中的内部花费
(11) 用Where子句替换HAVING子句:
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作. 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销. (非oracle中)on、where、having这三个都可以加条件的子句中,on是最先执行,where次之,having最后,因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,where也应该比having快点的,因为它过滤数据后才进行sum,在两个表联接时才用on的,所以在一个表的时候,就剩下where跟having比较了。在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的,根据上篇写的工作流程,where的作用时间是在计算之前就完成的,而having就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里
(12) 减少对表的查询:
在含有子查询的SQL语句中,要特别注意减少对表的查询.例子:
SELECT TAB_NAME FROM TABLES WHERE (TAB_NAME,DB_VER) = ( SELECT
TAB_NAME,DB_VER FROM TAB_COLUMNS WHERE VERSION = 604)
(13) 通过内部函数提高SQL效率.:
复杂的SQL往往牺牲了执行效率. 能够掌握上面的运用函数解决问题的方法在实际工作中是非常有意义的
(14) 使用表的别名(Alias):
当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误.
(15) 用EXISTS替代IN、用NOT EXISTS替代NOT IN:
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接.在这种情况下, 使用EXISTS(或NOT EXISTS)通常将提高查询的效率. 在子查询中,NOT IN子句将执行一个内部的排序和合并. 无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历). 为了避免使用NOT IN ,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS.
例子:
(高效)SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND EXISTS (SELECT ‘X’ FROM DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO AND LOC = ‘MELB’)
(低效)SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND DEPTNO IN(SELECT DEPTNO FROM DEPT WHERE LOC = ‘MELB’)
(16) 识别’低效执行’的SQL语句:
虽然目前各种关于SQL优化的图形化工具层出不穷,但是写出自己的SQL工具来解决问题始终是一个最好的方法:
SELECT EXECUTIONS , DISK_READS, BUFFER_GETS,
ROUND((BUFFER_GETS-DISK_READS)/BUFFER_GETS,2) Hit_radio,
ROUND(DISK_READS/EXECUTIONS,2) Reads_per_run,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS>0
AND BUFFER_GETS > 0
AND (BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.8
ORDER BY 4 DESC;
(17) 用索引提高效率:
索引是表的一个概念部分,用来提高检索数据的效率,ORACLE使用了一个复杂的自平衡B-tree结构. 通常,通过索引查询数据比全表扫描要快. 当ORACLE找出执行查询和Update语句的最佳路径时, ORACLE优化器将使用索引. 同样在联结多个表时使用索引也可以提高效率. 另一个使用索引的好处是,它提供了主键(primary key)的唯一性验证.。那些LONG或LONG RAW数据类型, 你可以索引几乎所有的列. 通常, 在大型表中使用索引特别有效. 当然,你也会发现, 在扫描小表时,使用索引同样能提高效率. 虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价. 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时, 索引本身也会被修改. 这意味着每条记录的INSERT , DELETE , UPDATE将为此多付出4 , 5 次的磁盘I/O . 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢.。定期的重构索引是有必要的.:
ALTER INDEX REBUILD
(18) 用EXISTS替换DISTINCT:
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT. 一般可以考虑用EXIST替换, EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果. 例子:
(低效):
SELECT DISTINCT DEPT_NO,DEPT_NAME FROM DEPT D , EMP E
WHERE D.DEPT_NO = E.DEPT_NO
(高效):
SELECT DEPT_NO,DEPT_NAME FROM DEPT D WHERE EXISTS ( SELECT ‘X’
FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO);
(19) sql语句用大写的;因为oracle总是先解析sql语句,把小写的字母转换成大写的再执行
(20) 在java代码中尽量少用连接符“+”连接字符串!
(21) 避免在索引列上使用NOT 通常,
我们要避免在索引列上使用NOT, NOT会产生在和在索引列上使用函数相同的影响. 当ORACLE”遇到”NOT,他就会停止使用索引转而执行全表扫描.
(22) 避免在索引列上使用计算.
WHERE子句中,如果索引列是函数的一部分.优化器将不使用索引而使用全表扫描.
举例:
低效:
SELECT … FROM DEPT WHERE SAL * 12 > 25000;
高效:
SELECT … FROM DEPT WHERE SAL > 25000/12;
(23) 用>=替代>
高效:
SELECT * FROM EMP WHERE DEPTNO >=4
低效:
SELECT * FROM EMP WHERE DEPTNO >3
两者的区别在于, 前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录.
(24) 用UNION替换OR (适用于索引列)
通常情况下, 用UNION替换WHERE子句中的OR将会起到较好的效果. 对索引列使用OR将造成全表扫描. 注意, 以上规则只针对多个索引列有效. 如果有column没有被索引, 查询效率可能会因为你没有选择OR而降低. 在下面的例子中, LOC_ID 和REGION上都建有索引.
高效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10
UNION
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE REGION = “MELBOURNE”
低效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10 OR REGION = “MELBOURNE”
如果你坚持要用OR, 那就需要返回记录最少的索引列写在最前面.
(25) 用IN来替换OR
这是一条简单易记的规则,但是实际的执行效果还须检验,在ORACLE8i下,两者的执行路径似乎是相同的.
低效:
SELECT…. FROM LOCATION WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30
高效
SELECT… FROM LOCATION WHERE LOC_IN IN (10,20,30);
(26) 避免在索引列上使用IS NULL和IS NOT NULL
避免在索引中使用任何可以为空的列,ORACLE将无法使用该索引.对于单列索引,如果列包含空值,索引中将不存在此记录. 对于复合索引,如果每个列都为空,索引中同样不存在此记录. 如果至少有一个列不为空,则记录存在于索引中.举例: 如果唯一性索引建立在表的A列和B列上, 并且表中存在一条记录的A,B值为(123,null) , ORACLE将不接受下一条具有相同A,B值(123,null)的记录(插入). 然而如果所有的索引列都为空,ORACLE将认为整个键值为空而空不等于空. 因此你可以插入1000 条具有相同键值的记录,当然它们都是空! 因为空值不存在于索引列中,所以WHERE子句中对索引列进行空值比较将使ORACLE停用该索引.
低效: (索引失效)
SELECT … FROM DEPARTMENT WHERE DEPT_CODE IS NOT NULL;
高效: (索引有效)
SELECT … FROM DEPARTMENT WHERE DEPT_CODE >=0;
(27) 总是使用索引的第一个列:
如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 这也是一条简单而重要的规则,当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引
(28) 用UNION-ALL 替换UNION ( 如果有可能的话):
当SQL语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并, 然后在输出最终结果前进行排序. 如果用UNION ALL替代UNION, 这样排序就不是必要了. 效率就会因此得到提高. 需要注意的是,UNION ALL 将重复输出两个结果集合中相同记录. 因此各位还是要从业务需求分析使用UNION ALL的可行性. UNION 将对结果集合排序,这个操作会使用到SORT_AREA_SIZE这块内存. 对于这块内存的优化也是相当重要的. 下面的SQL可以用来查询排序的消耗量
(29) 用WHERE替代ORDER BY:
ORDER BY 子句只在两种严格的条件下使用索引.
ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序.
ORDER BY中所有的列必须定义为非空.
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列.
(30) 避免改变索引列的类型.:
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换.
假设 EMPNO是一个数值类型的索引列.
SELECT … FROM EMP WHERE EMPNO = ‘123’
实际上,经过ORACLE类型转换, 语句转化为:
SELECT … FROM EMP WHERE EMPNO = TO_NUMBER(‘123’)
幸运的是,类型转换没有发生在索引列上,索引的用途没有被改变.
现在,假设EMP_TYPE是一个字符类型的索引列.
SELECT … FROM EMP WHERE EMP_TYPE = 123
这个语句被ORACLE转换为:
SELECT … FROM EMP WHERETO_NUMBER(EMP_TYPE)=123
因为内部发生的类型转换, 这个索引将不会被用到! 为了避免ORACLE对你的SQL进行隐式的类型转换, 最好把类型转换用显式表现出来. 注意当字符和数值比较时, ORACLE会优先转换数值类型到字符类型
(31) 需要当心的WHERE子句:
某些SELECT 语句中的WHERE子句不使用索引. 这里有一些例子.
| 在下面的例子里, (1)‘!=’ 将不使用索引. 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中. (2) ‘ | ‘是字符连接函数. 就象其他函数那样, 停用了索引. (3) ‘+’是数学函数. 就象其他数学函数那样, 停用了索引. (4)相同的索引列不能互相比较,这将会启用全表扫描. |
(32) a. 如果检索数据量超过30%的表中记录数.使用索引将没有显著的效率提高.
b. 在特定情况下, 使用索引也许会比全表扫描慢, 但这是同一个数量级上的区别. 而通常情况下,使用索引比全表扫描要块几倍乃至几千倍!
(33) 避免使用耗费资源的操作:
带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎
执行耗费资源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序. 通常, 带有UNION, MINUS , INTERSECT的SQL语句都可以用其他方式重写. 如果你的数据库的SORT_AREA_SIZE调配得好, 使用UNION , MINUS, INTERSECT也是可以考虑的, 毕竟它们的可读性很强
(34) 优化GROUP BY:
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.下面两个查询返回相同结果但第二个明显就快了许多.
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
6.like 也将导致全表扫描,可以考虑全文检索。
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=’abc’ // oracle总有的是substr函数。
select id from t where datediff(day,createdate,’2005-11-30’)=0 //查过了确实没有datediff函数。
应改为:
select id from t where name like ’abc%’
select id from t where createdate>=’2005-11-30’ and createdate<’2005-12-1’ //
oracle 中时间应该把char 转换成 date 如: createdate >= to_date(‘2005-11-30’,’yyyy-mm-dd’)
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。(采用函数处理的字段不能利用索引)
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)
13.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21.避免频繁创建和删除临时表,以减少系统表资源的消耗。
22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29.尽量避免大事务操作,提高系统并发能力。
30.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
31. union操作符
union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,
删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史
表union。
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,
如果表数据量大的话可能会导致用磁盘进行排序。
推荐方案:采用union ALL操作符替代union,因为union ALL操作只是简单的将两个结果合并后就返回。
32. 尽量避免隐士类型转换
容易引起oracle索引失效的原因很多:
1)、在索引列上使用函数。如SUBSTR,DECODE,INSTR等,对索引列进行运算.需要建立函数索引就可以解决了。
2)新建的表还没来得及生成统计信息,分析一下就好了
3)、基于cost的成本分析,访问的表过小,使用全表扫描的消耗小于使用索引。
4)、使用<>、not in 、not exist,对于这三种情况大多数情况下认为结果集很大,一般大于5%-15%就不走索引而走FTS(全表扫描)。
5)、单独的>、<。
6)、like ”%_“ 百分号在前。
7)、单独引用复合索引里非第一位置的索引列。也就是说查询谓词并未使用组合索引的第一列,此处有一个INDEX SKIP SCAN概念
8)、字符型字段为数字时在where条件里不添加引号。
9)、当变量采用的是times变量,而表的字段采用的是date变量时.或相反情况。
10)、索引失效,可以考虑重建索引,rebuild online。
11)、B-tree索引 is null不会走,is not null会走,位图索引 is null,is not null 都会走、联合索引 is not null 只要在建立的索引列(不分先后)都会走
12) 、在包含有null值的table列上建立索引,当时使用select count(*) from table时不会使用索引。
13)、加上hint 还不走索引,那可能是因为你要走索引的这列是nullable,虽然这列没有空值。(将字段改为not null,就会走)
- Oracle跟SQL Server 2005的区别?
宏观上:
-
最大的区别在于平台,oracle可以运行在不同的平台上,sql server只能运行在windows平台上,由于windows平台的稳定性和安全性影响了sql server的稳定性和安全性
-
oracle使用的脚本语言为PL-SQL,而sql server使用的脚本为T-SQL
微观上: 从数据类型,数据库的结构等等回答
- 如何使用Oracle的游标?
1. oracle中的游标分为显示游标和隐式游标
2. 显示游标是用cursor…is命令定义的游标,它可以对查询语句(select)返回的多条记录进行处理;隐式游标是在执行插入 (insert)、删除(delete)、修改(update)和返回单条记录的查询(select)语句时由PL/SQL自动定义的。
-
显式游标的操作:打开游标、操作游标、关闭游标;PL/SQL隐式地打开SQL游标,并在它内部处理SQL语句,然后关闭它
-
Oracle中有哪几种文件?
数据文件(一般后缀为.dbf或者.ora),日志文件(后缀名.log),控制文件(后缀名为.ctl)
- 怎样优化Oracle数据库,有几种方式?
个人理解,数据库性能最关键的因素在于IO,因为操作内存是快速的,但是读写磁盘是速度很慢的,优化数据库最关键的问题在于减少磁盘的IO,就个人理解应该分为物理的和逻辑的优化, 物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化
物理优化的一些原则:
-
Oracle的运行环境(网络,硬件等)
-
使用合适的优化器
-
合理配置oracle实例参数
-
建立合适的索引(减少IO)
-
将索引数据和表数据分开在不同的表空间上(降低IO冲突)
-
建立表分区,将数据分别存储在不同的分区上(以空间换取时间,减少IO)
逻辑上优化:
-
可以对表进行逻辑分割,如中国移动用户表,可以根据手机尾数分成10个表,这样对性能会有一定的作用
-
Sql语句使用占位符语句,并且开发时候必须按照规定编写sql语句(如全部大写,全部小写等)oracle解析语句后会放置到共享池中
如: select * from Emp where name=? 这个语句只会在共享池中有一条,而如果是字符串的话,那就根据不同名字存在不同的语句,所以占位符效率较好
-
数据库不仅仅是一个存储数据的地方,同样是一个编程的地方,一些耗时的操作,可以通过存储过程等在用户较少的情况下执行,从而错开系统使用的高峰时间,提高数据库性能
-
尽量不使用*号,如select * from Emp,因为要转化为具体的列名是要查数据字典,比较耗时
-
选择有效的表名
对于多表连接查询,可能oracle的优化器并不会优化到这个程度, oracle 中多表查询是根据FROM字句从右到左的数据进行的,那么最好右边的表(也就是基础表)选择数据较少的表,这样排序更快速,如果有link表(多对多中间表),那么将link表放最右边作为基础表,在默认情况下oracle会自动优化,但是如果配置了优化器的情况下,可能不会自动优化,所以平时最好能按照这个方式编写sql
- Where字句 规则
Oracle 中Where字句时从右往左处理的,表之间的连接写在其他条件之前,能过滤掉非常多的数据的条件,放在where的末尾, 另外!=符号比较的列将不使用索引,列经过了计算(如变大写等)不会使用索引(需要建立起函数), is null、is not null等优化器不会使用索引
-
使用Exits Not Exits 替代 In Not in
-
合理使用事务,合理设置事务隔离性
数据库的数据操作比较消耗数据库资源的,尽量使用批量处理,以降低事务操作次数
- Oracle分区是怎样优化数据库的?
Oracle的分区可以分为:列表分区、范围分区、散列分区、复合分区。
1. 增强可用性:如果表的一个分区由于系统故障而不能使用,表的其余好的分区仍可以使用;
2. 减少关闭时间:如果系统故障只影响表的一部份分区,那么只有这部份分区需要修复,可能比整个大表修复花的时间更少;
3. 维护轻松:如果需要得建表,独产管理每个公区比管理单个大表要轻松得多;
4. 均衡I/O:可以把表的不同分区分配到不同的磁盘来平衡I/O改善性能;
5. 改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快
6. 分区对用户透明,最终用户感觉不到分区的存在。
- Oracle是怎样分页的?
Oracle中使用rownum来进行分页, 这个是效率最好的分页方法,hibernate也是使用rownum来进行oralce分页的
select * from
( select rownum r,a from tabName where rownum <= 20 )
where r > 10
- Oracle中使用了索引的列,对该列进行where条件查询、分组、排序、使用聚集函数,哪些用到了索引?
均会使用索引, 值得注意的是复合索引(如在列A和列B上建立的索引)可能会有不同情况
- Oracle中where条件查询和排序的性能比较?
Order by使用索引的条件极为严格,只有满足如下情况才可以使用索引,
-
order by中的列必须包含相同的索引并且索引顺序和排序顺序一致
-
不能有null值的列
所以排序的性能往往并不高,所以建议尽量避免order by
常见问题
- oracle 导入导出定时备份
expdp\impdp及exp\imp
系统定时任务
- Oralce怎样存储文件,能够存储哪些文件?
Oracle 能存储 clob、nclob、blob、bfile
Clob 可变长度的字符型数据,也就是其他数据库中提到的文本型数据类型
Nclob 可变字符类型的数据,不过其存储的是Unicode字符集的字符数据
Blob 可变长度的二进制数据
Bfile 数据库外面存储的可变二进制数据
- 比较truncate和delete
-
Truncate 和delete都可以将数据实体删掉,truncate 的操作并不记录到 rollback日志,所以操作速度较快,但同时这个数据不能恢复
-
Delete操作不腾出表空间的空间
-
Truncate 不能对视图等进行删除
-
Truncate是数据定义语言(DDL),而delete是数据操纵语言(DML)
1.delete支持按条件删除,TRUNCATE不支持。
2.delete 删除后自增列不会重置,而TRUNCATE会被重置。
3.delete是逐条删除(速度较慢),truncate是整体删除(速度较快)。
4.delete删除是一条一条删除,并不会改变表结构,属于DML,而truncate删除表数据是将表删掉,重新新建一张表,属于DDL。
5.delete不会释放空间,而TRUNCATE会释放空间。
6.delete 支持回滚,TRUNCATE不支持。
- 主键有几种;
字符型,整数型、复合型
- 删除重复记录:
最高效的删除重复记录方法 ( 因为使用了ROWID)例子:
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID)
FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
- rowid, rownum的定义
-
rowid和rownum都是虚列
-
rowid是物理地址,用于定位oracle中具体数据的物理存储位置
-
rownum则是sql的输出结果排序,从下面的例子可以看出其中的区别。
- oracle中存储过程,游标和函数的区别
游标类似指针,游标可以执行多个不相关的操作.如果希望当产生了结果集后,对结果集中的数据进行多 种不相关的数据操作
函数可以理解函数是存储过程的一种; 函数可以没有参数,但是一定需要一个返回值,存储过程可以没有参数,不需要返回值;两者都可以通过out参数返回值, 如果需要返回多个参数则建议使用存储过程;在sql数据操纵语句中只能调用函数而不能调用存储过程
- 使用oracle 伪列删除表中重复记录:
Delete table t where t.rowid!=(select max(t1.rowid) from table1 t1 where t1.name=t.name)
备份与恢复
RMAN(Recovery Manager)工具
1.什么是RMAN?
RMAN可以用来备份和还原数据库文件、归档日志和控制文件。它也可以用来执行完全或不完全的数据库恢复。
注意:RMAN不能用于备份初始化参数文件和口令文件。
RMAN启动数据库上的Oracle服务器进程来进行备份或还原。备份、还原、恢复是由这些进程驱动的。
RMAN可以由OEM的Backup Manager GUI来控制,但在本文章里不作重点讨论。
- Terminology 专业词汇解释
2.1. Backup sets 备份集合
备份集合有下面的特性:
包括一个或多个数据文件或归档日志
以oracle专有的格式保存
有一个完全的所有的备份片集合构成
构成一个完全备份或增量备份
2.2. Backup pieces 备份片
一个备份集由若干个备份片组成。每个备份片是一个单独的输出文件。一个备份片的大小是有限制的;如果没有大小的限制, 备份集就只由一个备份片构成。备份片的大小不能大于使用的文件系统所支持的文件长度的最大值。
2.3. Image copies 镜像备份
镜像备份是独立文件(数据文件、归档日志、控制文件)的备份。它很类似操作系统级的文件备份。它不是备份集或 备份片,也没有被压缩。
2.4. Full backup sets 全备份集合
全备份是一个或多个数据文件中使用过的数据块的的备份。没有使用过的数据块是不被备份的,也就是说,oracle 进行备份集合的压缩。
2.5. Incremental backup sets 增量备份集合
增量备份是指备份一个或多个数据文件的自从上一次同一级别的或更低级别的备份以来被修改过的数据块。 与完全备份相同,增量备份也进行压缩。
2.6. File multiplexing
不同的多个数据文件的数据块可以混合备份在一个备份集中。
2.7. Recovery catalog resyncing 恢复目录同步
使用恢复管理器执行backup、copy、restore或者switch命令时,恢复目录自动进行更新,但是有关日志与归档日志信息没有自动记入恢复目录。需要进行目录同步。使用resync catalog命令进行同步。
RMAN>resync catalog;
RMAN-03022:正在编译命令:resync
RMAN-03023:正在执行命令:resync
RMAN-08002:正在启动全部恢复目录的 resync
RMAN-08004:完成全部 resync
- 恢复目录
3.1.恢复目录的概念
恢复目录是由RMAN使用、维护的用来放置备份信息的仓库。RMAN利用恢复目录记载的信息去判断如何执行需要的备份恢复操作。
恢复目录可以存在于ORACLE数据库的计划中。
虽然恢复目录可以用来备份多个数据库,建议为恢复目录数据库创建一个单独的数据库。
恢复目录数据库不能使用恢复目录备份自身。
3.2.建立恢复目录
第一步,在目录数据库中创建恢复目录所用表空间:
SQL> create tablespace rman_ts datafile ‘d:\oracle\oradata\rman\rman_ts.dbf’ size 20M;
表空间已创建。
第二步,在目录数据库中创建RMAN 用户并授权:
SQL> create user rman identified by rman default tablespace rman_ts temporary tablespace temp quota unlimited on rman_ts;
用户已创建。
SQL> grant recovery_catalog_owner to rman ;
授权成功。
SQL> grant connect, resource to rman ;
授权成功。
第三步,在目录数据库中创建恢复目录
C:>rman catalog rman/rman
恢复管理器:版本8.1.6.0.0 - Production
RMAN-06008:连接到恢复目录数据库
RMAN-06428:未安装恢复目录
RMAN>create catalog tablespace rman_ts;
RMAN-06431:恢复目录已创建
注意:虽然使用RMAN不一定必需恢复目录,但是推荐使用。因为恢复目录记载的信息大部分可以通过控制文件来记载,RMAN在恢复数据库时使用这些信息。不使用恢复目录将会对备份恢复操作有限制。
3.3.使用恢复目录的优势
可以存储脚本;
记载较长时间的备份恢复操作;
- 启动RMAN
RMAN为交互式命令行处理界面,也可以从企业管理器中运行。
为了使用下面的实例,先检查环境符合:
the target database is called “his” and has the same TNS alias
user rman has been granted “recovery_catalog_owner “privileges
目标数据库的连接用户为internal帐号,或者以其他SYSDBA类型帐号连接
the recovery catalog database is called “rman” and has the same TNS alias
the schema containing the recovery catalog is “rman” (same password)
在使用RMAN前,设置NLS_DATE_FORMAT 和NLS_LANG环境变量,很多RMAN LIST命令的输出结果是与日期时间相关的,这点在用户希望执行以时间为基准的恢复工作也很重要。
下例是环境变量的示范:
NLS_LANG= SIMPLIFIED CHINESE_CHINA.ZHS16GBK
NLS_DATE_FORMAT=DD-MON-YYYY HH24:MI:SS
为了保证RMAN使用时能连接恢复目录,恢复目录数据库必须打开,目标数据库至少要STARTED(unmount),否则RMAN会返回一个错误,目标数据库必须置于归档模式下。
4.1.使用不带恢复目录的RMAN
设置目标数据库的 ORACLE_SID ,执行:
% rman nocatalog
RMAN> connect target
RMAN> connect target internal/@his
4.2.使用带恢复目录的RMAN
% rman rman_ts rman/rman\@rman
RMAN> connect target
% rman rman_ts rman/rman\@rman target internal/@his
4.3.使用RMAN
一旦连接到目标数据库,可以通过交互界面或者事先存储的脚本执行指定RMAN命令, 下面是一个使用RMAN交互界面的实例:
RMAN> resync catalog;
RMAN-03022:正在编译命令:resync
RMAN-03023:正在执行命令:resync
RMAN-08002:正在启动全部恢复目录的 resync
RMAN-08004:完成全部 resync
使用脚本的实例:
RMAN> execute script alloc_1_disk;
创建或者替代存储的脚本:
RMAN> replace script alloc_1_disk {
2> allocate channel d1 type disk;
3> }
5.注册或者注销目标数据库
5.1.注册目标数据库
数据库状态:
恢复目录状态:打开
目标数据库:加载或者打开
目标数据库在第一次使用RMAN之前必须在恢复目录中注册:
第一步,启动恢复管理器,并且连接目标数据库:
C:>rman target internal/oracle\@his catalog rman/rman\@rman
恢复管理器:版本8.1.6.0.0 - Production
RMAN-06005:连接到目标数据库:HIS (DBID=3021445076)
RMAN-06008:连接到恢复目录数据库
第二步,注册数据库:
RMAN> register database;
RMAN-03022:正在编译命令:register
RMAN-03023:正在执行命令:register
RMAN-08006:注册在恢复目录中的数据库
RMAN-03023:正在执行命令:full resync
RMAN-08002:正在启动全部恢复目录的resync
RMAN-08004:完成全部resync
5.2.注销目标数据库
RMAN提供了一个注销工具,叫DBMS_RCVCAT工具包,请注意一旦注销了该目标数据库,就不可以使用恢复目录中含有的备份集来恢复数据库了。
为了能注销数据库,需要获得数据库的标识码(DB_ID)和数据库键值(DB_KEY)。其中连接目标数据库时将会获得DB_ID。
C:>rman target internal/oracle\@his catalog rman/rman\@rman
恢复管理器:版本8.1.6.0.0 - Production
RMAN-06005:连接到目标数据库:HIS (DBID=3021445076)
RMAN-06008:连接到恢复目录数据库
其中DBID=3021445076,利用DBID=3021445076查询数据库键值码:
连接到目标数据库,查询db表:
SQL> select * from db;
DB_KEY DB_ID CURR_DBINC_KEY
1 3021445076 2
获得DB_KEY=1,这样,该目标数据库DB_KEY=1,DBID=3021445076,利用两个值使用DBMS_RCVCAT工具包就可以注销数据库:
一、冷备份介绍:
冷备份数据库是将数据库关闭之后备份所有的关键性文件包括数据文件、控制文件、联机REDO LOG文件,将其拷贝到另外的位置。此外冷备份也可以包含对参数文件和口令文件的备份,但是这两种备份是可以根据需要进行选择的。,冷备份实际也是一种物理备份,是一个备份数据库物理文件的过程。因为冷备份要备份除了重做日志以外的所有数据库文件,因此也被成为完全的数据库备份。它的优缺点如下所示:
1、优点:
<1>只需拷贝文件即可,是非常快速的备份方法。
<2>只需将文件再拷贝回去,就可以恢复到某一时间点上。
<3>与数据库归档的模式相结合可以使数据库很好地恢复。
<4>维护量较少,但安全性确相对较高。
2、缺点:
<1>在进行数据库冷备份的过程中数据库必须处于关闭状态。
<2>单独使用冷备份时,数据库只能完成基于某一时间点上的恢复。
<3>若磁盘空间有限,冷备份只能将备份数据拷贝到磁带等其他外部存储上,速度会更慢。
<4>冷备份不能按表或按用户恢复。
3、具体备份步骤如下:
<1>以DBA用户或特权用户登录,查询动态性能视图v$datafile、v$controlfile可以分别列出数据库的数据文件以及控制文件。
SQL> select name from v`$datafile;
NAME ——————————————————————————– /u02/oradata/db01/system01.dbf /u02/oradata/db01/undotbs01.dbf /u02/oradata/db01/sysaux01.dbf /u02/oradata/db01/users01.dbf
SQL> select name from v$`controlfile;
NAME ——————————————————————————– /u02/oradata/db01/control01.ctl /u02/oradata/db01/control02.ctl /u02/oradata/db01/control03.ctl /u01/app/oracle/bak/control04.ctl
<2>以DBA用户或特权用户关闭数据库。
SQL> conn / as sysdba; Connected. SQL> shutdown normal Database closed. Database dismounted. ORACLE instance shut down.
<3>复制数据文件,复制时应该将文件复制到单独的一个硬盘或者磁盘上。控制文件是相互镜像的,因此只需复制一个控制文件即可。
cp /u02/oradata/db01/*.dbf /u01/app/oracle/bak
cp /u02/oradata/db01/*.ctl /u01/app/oracle/bak
<4>启动例程打开数据库。
SQL> conn / as sysdba; Connected to an idle instance. SQL> startup ORACLE instance started.
Total System Global Area 285212672 bytes Fixed Size 1218992 bytes Variable Size 83887696 bytes Database Buffers 197132288 bytes Redo Buffers 2973696 bytes Database mounted. Database opened. SQL>
二、热备份:
热备份是在数据库运行的情况下,采用archive log mode方式备份数据库的方法。热备份要求数据库处于archive log模式下操作,并需要大量的档案空间。一旦数据库处于archive loh
模式,就可以进行备份了,当执行备份时,只能在数据文件级或表空间进行。
1、优点:
<1>可在表空间或数据文件级备份,备份时间短。
<2>可达到秒级恢复(恢复到某一时间点上)。
<3>可对几乎所有数据库实体作恢复。
<4>恢复是快速的,在大多数情况下在数据库仍工作时恢复。
<5>备份时数据库仍可用。
2、缺点:
<1>因难以维护,所以要特别仔细小心,不允许“以失败而告终”。
<2>若热备份不成功,所得结果不可用于时间点的恢复。
<3>不能出错,否则后果严重。
3、设置初始归档模式:
设置归档模式数据库必须处在mount而非open状态下:
<1>首先查看数据库是否处在archive log模式下:
SQL> archive log list; Database log mode No Archive Mode Automatic archival Disabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 1 Current log sequence 2
<2>在mount状态下启动数据库:
SQL> startup mount; ORACLE instance started.
Total System Global Area 285212672 bytes Fixed Size 1218992 bytes Variable Size 83887696 bytes Database Buffers 197132288 bytes Redo Buffers 2973696 bytes Database mounted.
<3>设置数据库为归档模式:
SQL> alter database archivelog;
Database altered.
<4>打开数据库:
SQL> alter database open;
Database altered.
<5>将数据库设置成自动归档,使用以下命令:
SQL> alter system set log_archive_start=true scope=spfile;
System altered.
<6>确定数据库处于归档模式下,并且设置自动存档:
SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination USE_DB_RECOVERY_FILE_DEST Oldest online log sequence 1 Next log sequence to archive 2 Current log sequence 2
上面的Archive destination所定义的具体位置,可以查看$ORACLE_HOME/dbs/spfile<dbname>.ora文件中的db_recovery_file_dest参数的值。
4、联机备份:
联机备份是热备份的一种备份方法,是指当表空间处于ONLINE状态时,备份表空间的所有数据文件和单个数据文件的过程。使用联机备份的优点是不影响用户在表空间上的所有访问操作,但联机备份的缺点可能生产更多的重做日志文件和归档日志文件。以下是联机备份的具体步骤:
<1>以DBA用户或特权用户登录,确定表空间所包含的数据文件。通过查询数据字典DBA_DATA_FILES,可以得到数据文件和表空间的对应关系:
SQL> select file_name from dba_data_files where tablespace_name=’USERS’;
FILE_NAME ——————————————————————————– /u02/oradata/db01/users01.dbf
<2>设置表空间为备份模式,在复制表空间的数据文件之前必须将表空间设置成为备份模式:
SQL> alter tablespace users begin backup;
Tablespace altered.
<3>复制users数据文件到备份目录:
[oracle\@server1 bak]`$ cp /u02/oradata/db01/users01.dbf /bak
<4>复制后表空间就不需要设置成为备份模式了,因此可以将其返回正常模式:
SQL> alter tablespace users end backup;
Tablespace altered.
5、脱机备份:
脱机备份也是热备份的一种方法,是指当表空间处于offline时,备份表空间的所有数据文件以及单个数据文件的过程。它的优点是会生产较少的重做日志文件,缺点是当用户正在进行脱机备份时所备份的表空间将不能访问,由于SYSTEM系统表空间和正在使用的UNDO表空间不能被脱机,因此脱机备份不适用于SYSTEM表空间和正在使用的UNDO表空间。
<1>使用DBA用户或特权用户登录,确定表空间所包含的数据文件。这个和联机备份的第一步相同:
SQL> select file_name from dba_data_files where tablespace_name=’USERS’;
FILE_NAME ——————————————————————————– /u02/oradata/db01/users01.dbf
<2>设置表空间为脱机状态,将表空间设置为脱机状态后用户将不能访问该表空间上的任何对象,因此也可以确保OFFLINE的表空间的数据文件不会发生改变。
SQL> alter tablespace users offline;
Tablespace altered.
SQL> select tablespace_name,online_status from dba_data_files;
TABLESPACE_NAME ONLINE_ —————————— ——- USERS OFFLINE SYSAUX ONLINE UNDOTBS1 ONLINE SYSTEM SYSTEM
<3>复制users数据文件到备份目录: [oracle@server1 bak]$` cp /u02/oradata/db01/users01.dbf /bak
<4>复制完后将表空间置于online状态:
SQL> alter tablespace users online;
Tablespace altered.
SQL> select tablespace_name,online_status from dba_data_files;
TABLESPACE_NAME ONLINE_ —————————— ——- USERS ONLINE SYSAUX ONLINE UNDOTBS1 ONLINE SYSTEM SYSTEM
闪回技术
flashback
show recyclebin
exp/imp
基本语法和实例:\
EXP:有三种主要的方式(完全、用户、表)
1、完全:EXP SYSTEM/MANAGER BUFFER=64000 FILE=C:\FULL.DMP FULL=Y如果要执行完全导出,必须具有特殊的权限
2、用户模式:EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC这样用户SONIC的所有对象被输出到文件中。
3、表模式:EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC TABLES=(SONIC)这样用户SONIC的表SONIC就被导出
IMP:具有三种模式(完全、用户、表)
1、完全:IMP SYSTEM/MANAGER BUFFER=64000 FILE=C:\FULL.DMP FULL=Y\
2、用户模式:IMP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP FROMUSER=SONIC TOUSER=SONIC这样用户SONIC的所有对象被导入到文件中。必须指定FROMUSER、TOUSER参数,这样才能导入数据。\
3、表模式:EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC TABLES=(SONIC)这样用户SONIC的表SONIC就被导入。
ORACLE数据库有两类备份方法。第一类为物理备份,该方法实现数据库的完整恢复,但数据库必须运行在归挡模式下(业务数据库在非归挡模式下运行),且需要极大的外部存储设备,例如磁带库;第二类备份方式为逻辑备份,业务数据库采用此种方式,此方法不需要数据库运行在归挡模式下,不但备份简单,而且可以不需要外部存储设备。\
数据库逻辑备份方法\
ORACLE数据库的逻辑备份分为三种模式:表备份、用户备份和完全备份。\
表模式\
备份某个用户模式下指定的对象(表)。业务数据库通常采用这种备份方式。\
若备份到本地文件,使用如下命令:\
exp icdmain/icd rows=y indexes=n compress=n buffer=65536\
feedback=100000 volsize=0\
file=exp_icdmain_csd_yyyymmdd.dmp\
log=exp_icdmain_csd_yyyymmdd.log\
tables=icdmain.commoninformation,icdmain.serviceinfo,icdmain.dealinfo\
若直接备份到磁带设备,使用如下命令:\
exp icdmain/icd rows=y indexes=n compress=n buffer=65536\
feedback=100000 volsize=0\
file=/dev/rmt0\
log=exp_icdmain_csd_yyyymmdd.log\
tables=icdmain.commoninformation,icdmain.serviceinfo,icdmain.dealinfo\
注:在磁盘空间允许的情况下,应先备份到本地服务器,然后再拷贝到磁带。出于速度方面的考虑,尽量不要直接备份到磁带设备。\
用户模式\
备份某个用户模式下的所有对象。业务数据库通常采用这种备份方式。\
若备份到本地文件,使用如下命令:\
exp icdmain/icd owner=icdmain rows=y indexes=n compress=n buffer=65536\
feedback=100000 volsize=0\
file=exp_icdmain_yyyymmdd.dmp\
log=exp_icdmain_yyyymmdd.log\
若直接备份到磁带设备,使用如下命令:\
exp icdmain/icd owner=icdmain rows=y indexes=n compress=n buffer=65536\
feedback=100000 volsize=0\
file=/dev/rmt0\
log=exp_icdmain_yyyymmdd.log\
注:如果磁盘有空间,建议备份到磁盘,然后再拷贝到磁带。如果数据库数据量较小,可采用这种办法备份。
以下为详细的导入导出实例:
一、数据导出:
1、将数据库TEST完全导出,用户名system 密码manager 导出到D:\daochu.dmp中
exp system/manager\@TEST file=d:\daochu.dmp full=y
2、将数据库中system用户与sys用户的表导出
exp system/manager\@TEST file=d:\daochu.dmp owner=(system,sys)
3、将数据库中的表table1 、table2导出
exp system/manager\@TEST file=d:\daochu.dmp tables=(table1,table2)
4、将数据库中的表table1中的字段filed1以”00”打头的数据导出
exp system/manager\@TEST file=d:\daochu.dmp tables=(table1) query=\” where filed1 like ‘00%’\”
上面是常用的导出,对于压缩我不太在意,用winzip把dmp文件可以很好的压缩。
不过在上面命令后面 加上 compress=y 就可以了
二、数据的导入
1、将D:\daochu.dmp 中的数据导入 TEST数据库中。
imp system/manager\@TEST file=d:\daochu.dmp
上面可能有点问题,因为有的表已经存在,然后它就报错,对该表就不进行导入。
在后面加上 ignore=y 就可以了。
2 将d:\daochu.dmp中的表table1 导入
imp system/manager\@TEST file=d:\daochu.dmp tables=(table1)
基本上上面的导入导出够用了。不少情况我是将表彻底删除,然后导入。
注意:
你要有足够的权限,权限不够它会提示你。
数据库时可以连上的。可以用tnsping TEST 来获得数据库TEST能否连上。
expdp/impdp
expdp/impdp和exp/imp的区别
1、exp和imp是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用。
2、expdp和impdp是服务端的工具程序,他们只能在oracle服务端使用,不能在客户端使用。
3、imp只适用于exp导出的文件,不适用于expdp导出文件;impdp只适用于expdp导出的文件,而不适用于exp导出文件。
4、对于10g以上的服务器,使用exp通常不能导出0行数据的空表,而此时必须使用expdp导出。
二、expdp导出步骤
(1)创建逻辑目录:
第一步:在服务器上创建真实的目录;(注意:第三步创建逻辑目录的命令不会在OS上创建真正的目录,所以要先在服务器上创建真实的目录。如下图:)

第二步:用sys管理员登录sqlplus;

oracle@ypdbtest:/home/oracle/dmp/vechcore>sqlplus
SQL*Plus: Release 11.2.0.4.0 Production on Tue Sep 5 09:20:49 2017
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Enter user-name: sys as sysdba
Enter password:
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL>
第三步:创建逻辑目录;
SQL> create directory data_dir as ‘/home/oracle/dmp/user’;
Directory created.
第四步:查看管理员目录,检查是否存在;
SQL> select * from dba_directories;
OWNER DIRECTORY_NAME
DIRECTORY_PATH
SYS DATA_DIR
/home/oracle/dmp/user
第五步:用sys管理员给你的指定用户赋予在该目录的操作权限。
SQL> grant read,write on directory data_dir to user;
Grant succeeded.
(2)用expdp导出dmp,有五种导出方式:
第一种:“full=y”,全量导出数据库;
expdp user/passwd@orcl dumpfile=expdp.dmp directory=data_dir full=y logfile=expdp.log;
第二种:schemas按用户导出;
expdp user/passwd@orcl schemas=user dumpfile=expdp.dmp directory=data_dir logfile=expdp.log;
第三种:按表空间导出;
expdp sys/passwd@orcl tablespace=tbs1,tbs2 dumpfile=expdp.dmp directory=data_dir logfile=expdp.log;
第四种:导出表;
expdp user/passwd@orcl tables=table1,table2 dumpfile=expdp.dmp directory=data_dir logfile=expdp.log;
第五种:按查询条件导;
expdp user/passwd@orcl tables=table1=’where number=1234’ dumpfile=expdp.dmp directory=data_dir logfile=expdp.log;
三、impdp导入步骤
(1)如果不是同一台服务器,需要先将上面的dmp文件下载到目标服务器上,具体命令参照:http://www.cnblogs.com/promise-x/p/7452972.html
(2)参照“expdp导出步骤”里的前三步,建立逻辑目录;
(3)用impdp命令导入,对应五种方式:
第一种:“full=y”,全量导入数据库;
impdp user/passwd directory=data_dir dumpfile=expdp.dmp full=y;
第二种:同名用户导入,从用户A导入到用户A;
impdp A/passwd schemas=A directory=data_dir dumpfile=expdp.dmp logfile=impdp.log;
第三种:①从A用户中把表table1和table2导入到B用户中;
impdp B/passwdtables=A.table1,A.table2 remap_schema=A:B directory=data_dir dumpfile=expdp.dmp logfile=impdp.log;
②将表空间TBS01、TBS02、TBS03导入到表空间A_TBS,将用户B的数据导入到A,并生成新的oid防止冲突;
impdp A/passwd remap_tablespace=TBS01:A_TBS,TBS02:A_TBS,TBS03:A_TBS remap_schema=B:A FULL=Y transform=oid:n
directory=data_dir dumpfile=expdp.dmp logfile=impdp.log
第四种:导入表空间;
impdp sys/passwd tablespaces=tbs1 directory=data_dir dumpfile=expdp.dmp logfile=impdp.log;
第五种:追加数据;
impdp sys/passwd directory=data_dir dumpfile=expdp.dmp schemas=system table_exists_action=replace logfile=impdp.log;
–table_exists_action:导入对象已存在时执行的操作。有效关键字:SKIP,APPEND,REPLACE和TRUNCATE
四、expdp关键字与命令
(1)关键字 说明 (默认)
ATTACH 连接到现有作业, 例如 ATTACH [=作业名]。
COMPRESSION 减小转储文件内容的大小, 其中有效关键字 值为: ALL, (METADATA_ONLY), DATA_ONLY 和 NONE。
CONTENT 指定要卸载的数据, 其中有效关键字 值为: (ALL), DATA_ONLY 和 METADATA_ONLY。
DATA_OPTIONS 数据层标记, 其中唯一有效的值为: 使用CLOB格式的 XML_CLOBS-write XML 数据类型。
DIRECTORY 供转储文件和日志文件使用的目录对象,即逻辑目录。
DUMPFILE 目标转储文件 (expdp.dmp) 的列表,例如 DUMPFILE=expdp1.dmp, expdp2.dmp。
ENCRYPTION 加密部分或全部转储文件, 其中有效关键字值为: ALL, DATA_ONLY, METADATA_ONLY,ENCRYPTED_COLUMNS_ONLY 或 NONE。
ENCRYPTION_ALGORITHM 指定应如何完成加密, 其中有效关键字值为: (AES128), AES192 和 AES256。
ENCRYPTION_MODE 生成加密密钥的方法, 其中有效关键字值为: DUAL, PASSWORD 和 (TRANSPARENT)。
ENCRYPTION_PASSWORD 用于创建加密列数据的口令关键字。
ESTIMATE 计算作业估计值, 其中有效关键字值为: (BLOCKS) 和 STATISTICS。
ESTIMATE_ONLY 在不执行导出的情况下计算作业估计值。
EXCLUDE 排除特定的对象类型, 例如 EXCLUDE=TABLE:EMP。例:EXCLUDE=[object_type]:[name_clause],[object_type]:[name_clause] 。
FILESIZE 以字节为单位指定每个转储文件的大小。
FLASHBACK_SCN 用于将会话快照设置回以前状态的 SCN。 – 指定导出特定SCN时刻的表数据。
FLASHBACK_TIME 用于获取最接近指定时间的 SCN 的时间。– 定导出特定时间点的表数据,注意FLASHBACK_SCN和FLASHBACK_TIME不能同时使用。
FULL 导出整个数据库 (N)。
HELP 显示帮助消息 (N)。
INCLUDE 包括特定的对象类型, 例如 INCLUDE=TABLE_DATA。
JOB_NAME 要创建的导出作业的名称。
LOGFILE 日志文件名 (export.log)。
NETWORK_LINK 链接到源系统的远程数据库的名称。
NOLOGFILE 不写入日志文件 (N)。
PARALLEL 更改当前作业的活动 worker 的数目。
PARFILE 指定参数文件。
QUERY 用于导出表的子集的谓词子句。–QUERY = [schema.][table_name:] query_clause。
REMAP_DATA 指定数据转换函数,例如 REMAP_DATA=EMP.EMPNO:REMAPPKG.EMPNO。
REUSE_DUMPFILES 覆盖目标转储文件 (如果文件存在) (N)。
SAMPLE 要导出的数据的百分比。
SCHEMAS 要导出的方案的列表 (登录方案)。
STATUS 在默认值 (0) 将显示可用时的新状态的情况下,要监视的频率 (以秒计) 作业状态。
TABLES 标识要导出的表的列表 - 只有一个方案。–[schema_name.]table_name[:partition_name][,…]
TABLESPACES 标识要导出的表空间的列表。
TRANSPORTABLE 指定是否可以使用可传输方法, 其中有效关键字值为: ALWAYS, (NEVER)。
TRANSPORT_FULL_CHECK 验证所有表的存储段 (N)。
TRANSPORT_TABLESPACES 要从中卸载元数据的表空间的列表。
VERSION 要导出的对象的版本, 其中有效关键字为:(COMPATIBLE), LATEST 或任何有效的数据库版本。
(2)命令 说明
ADD_FILE 向转储文件集中添加转储文件。
CONTINUE_CLIENT 返回到记录模式。如果处于空闲状态, 将重新启动作业。
EXIT_CLIENT 退出客户机会话并使作业处于运行状态。
FILESIZE 后续 ADD_FILE 命令的默认文件大小 (字节)。
HELP 总结交互命令。
KILL_JOB 分离和删除作业。
PARALLEL 更改当前作业的活动 worker 的数目。PARALLEL=<worker 的数目>。
_DUMPFILES 覆盖目标转储文件 (如果文件存在) (N)。
START_JOB 启动/恢复当前作业。
STATUS 在默认值 (0) 将显示可用时的新状态的情况下,要监视的频率 (以秒计) 作业状态。STATUS[=interval]。
STOP_JOB 顺序关闭执行的作业并退出客户机。STOP_JOB=IMMEDIATE 将立即关闭数据泵作业。
五、impdp关键字与命令
(1)关键字 说明 (默认)
ATTACH 连接到现有作业, 例如 ATTACH [=作业名]。
CONTENT 指定要卸载的数据, 其中有效关键字 值为: (ALL), DATA_ONLY 和 METADATA_ONLY。
DATA_OPTIONS 数据层标记,其中唯一有效的值为:SKIP_CONSTRAINT_ERRORS-约束条件错误不严重。
DIRECTORY 供转储文件,日志文件和sql文件使用的目录对象,即逻辑目录。
DUMPFILE 要从(expdp.dmp)中导入的转储文件的列表,例如 DUMPFILE=expdp1.dmp, expdp2.dmp。
ENCRYPTION_PASSWORD 用于访问加密列数据的口令关键字。此参数对网络导入作业无效。
ESTIMATE 计算作业估计值, 其中有效关键字为:(BLOCKS)和STATISTICS。
EXCLUDE 排除特定的对象类型, 例如 EXCLUDE=TABLE:EMP。
FLASHBACK_SCN 用于将会话快照设置回以前状态的 SCN。
FLASHBACK_TIME 用于获取最接近指定时间的 SCN 的时间。
FULL 从源导入全部对象(Y)。
HELP 显示帮助消息(N)。
INCLUDE 包括特定的对象类型, 例如 INCLUDE=TABLE_DATA。
JOB_NAME 要创建的导入作业的名称。
LOGFILE 日志文件名(import.log)。
NETWORK_LINK 链接到源系统的远程数据库的名称。
NOLOGFILE 不写入日志文件。
PARALLEL 更改当前作业的活动worker的数目。
PARFILE 指定参数文件。
PARTITION_OPTIONS 指定应如何转换分区,其中有效关键字为:DEPARTITION,MERGE和(NONE)。
QUERY 用于导入表的子集的谓词子句。
REMAP_DATA 指定数据转换函数,例如REMAP_DATA=EMP.EMPNO:REMAPPKG.EMPNO。
REMAP_DATAFILE 在所有DDL语句中重新定义数据文件引用。
REMAP_SCHEMA 将一个方案中的对象加载到另一个方案。
REMAP_TABLE 表名重新映射到另一个表,例如 REMAP_TABLE=EMP.EMPNO:REMAPPKG.EMPNO。
REMAP_TABLESPACE 将表空间对象重新映射到另一个表空间。
REUSE_DATAFILES 如果表空间已存在, 则将其初始化 (N)。
SCHEMAS 要导入的方案的列表。
SKIP_UNUSABLE_INDEXES 跳过设置为无用索引状态的索引。
SQLFILE 将所有的 SQL DDL 写入指定的文件。
STATUS 在默认值(0)将显示可用时的新状态的情况下,要监视的频率(以秒计)作业状态。
STREAMS_CONFIGURATION 启用流元数据的加载。
TABLE_EXISTS_ACTION 导入对象已存在时执行的操作。有效关键字:(SKIP),APPEND,REPLACE和TRUNCATE。
TABLES 标识要导入的表的列表。
TABLESPACES 标识要导入的表空间的列表。
TRANSFORM 要应用于适用对象的元数据转换。有效转换关键字为:SEGMENT_ATTRIBUTES,STORAGE,OID和PCTSPACE。
TRANSPORTABLE 用于选择可传输数据移动的选项。有效关键字为: ALWAYS 和 (NEVER)。仅在 NETWORK_LINK 模式导入操作中有效。
TRANSPORT_DATAFILES 按可传输模式导入的数据文件的列表。
TRANSPORT_FULL_CHECK 验证所有表的存储段 (N)。
TRANSPORT_TABLESPACES 要从中加载元数据的表空间的列表。仅在 NETWORK_LINK 模式导入操作中有效。
VERSION 要导出的对象的版本, 其中有效关键字为:(COMPATIBLE), LATEST 或任何有效的数据库版本。仅对 NETWORK_LINK 和 SQLFILE 有效。
(2)命令 说明
CONTINUE_CLIENT 返回到记录模式。如果处于空闲状态, 将重新启动作业。
EXIT_CLIENT 退出客户机会话并使作业处于运行状态。
HELP 总结交互命令。
KILL_JOB 分离和删除作业。
PARALLEL 更改当前作业的活动 worker 的数目。PARALLEL=<worker 的数目>。
START_JOB 启动/恢复当前作业。START_JOB=SKIP_CURRENT 在开始作业之前将跳过作业停止时执行的任意操作。
STATUS 在默认值 (0) 将显示可用时的新状态的情况下,要监视的频率 (以秒计) 作业状态。STATUS[=interval]。
STOP_JOB 顺序关闭执行的作业并退出客户机。STOP_JOB=IMMEDIATE 将立即关闭数据泵作业。
数据库集群技术
RAC应用
ASM
容灾和数据卫士
故障诊断
商业智能与数据仓库
多维数据库
数据挖掘
Oracle事务隔离级别
设置一个事务的隔离级别:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET TRANSACTION READ ONLY;
SET TRANSACTION READ WRITE;
注意:这些语句是互斥的,不能同时设置两个或两个以上的选项。
设置单个会话的隔离级别:
ALTER SESSION SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
ALTER SESSION SET TRANSACTION ISOLATION SERIALIZABLE;
隔离级别 脏读 不可重复读 幻读
Read Uncommited Y Y Y
Read Commited N Y Y
Repeatable read N N Y
Serialized N N N
索引
创建标准索引:
CREATE INDEX 索引名 ON 表名 (列名) TABLESPACE 表空间名;
创建唯一索引:
CREATE unique INDEX 索引名 ON 表名 (列名) TABLESPACE 表空间名;
创建组合索引:
CREATE INDEX 索引名 ON 表名 (列名1,列名2) TABLESPACE 表空间名;
创建反向键索引:
CREATE INDEX 索引名 ON 表名 (列名) reverse TABLESPACE 表空间名;
索引使用原则:
索引字段建议建立NOT NULL约束
经常与其他表进行连接的表,在连接字段上应该建立索引;
经常出现在Where子句中的字段且过滤性很强的,特别是大表的字段,应该建立索引;
可选择性高的关键字 ,应该建立索引;
可选择性低的关键字,但数据的值分布差异很大时,选择性数据比较少时仍然可以利用索引提高效率
复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的第一个字段,一般是选择性较好的且在where子句中常用的字段上;
B、复合索引的几个字段经常同时以AND方式出现在Where子句中可以建立复合索引;否则单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
频繁DML的表,不要建立太多的索引;
不要将那些频繁修改的列作为索引列;
索引的优缺点:
有点:
-
创建唯一性索引,保证数据库表中每一行数据的唯一性
-
大大加快数据的检索速度,这也是创建索引的最主要的原因
-
加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-
在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
缺点:
-
索引创建在表上,不能创建在视图上
-
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
-
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大
-
当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度
-
怎样创建一个视图,视图的好处, 视图可以控制权限吗?
create view 视图名 as select 列名 [别名] … from 表 [unio [all] select … ] ]
好处:
-
可以简单的将视图理解为sql查询语句,视图最大的好处是不占系统空间
-
一些安全性很高的系统,不会公布系统的表结构,可能会使用视图将一些敏感信息过虑或者重命名后公布结构
锁
oracle的锁又几种,定义分别是什么;
1. 行共享锁 (ROW SHARE)
2. 行排他锁(ROW EXCLUSIVE)
3 . 共享锁(SHARE)
4. 共享行排他锁(SHARE ROW EXCLUSIVE)
5. 排他锁(EXCLUSIVE)
使用方法:
SELECT * FROM order_master WHERE vencode=”V002”
FOR UPDATE WAIT 5;
LOCK TABLE order_master IN SHARE MODE;
LOCK TABLE itemfile IN EXCLUSIVE MODE NOWAIT;
ORACLE锁具体分为以下几类:
1、按用户和系统分可以分为自动锁和显示锁
1.1自动锁( Automatic Locks)当进行一项数据库操作时,缺省情况下,系统自动为此数据库操作获得所有有必要的锁。
自动锁分为三种:
-
DML 锁
-
DDL 锁
-
systemlocks。
1.2显式锁( Manual Data Locks)某些情况下,需要用户显示的锁定数据库操作要用到的数据,才能使数据库操作执行得更好,显示锁是用户为数据库对象设定的。
3、按操作分可以分为DML锁、DLL锁和System Locks
3.1DML锁
DML 锁用于控制并发事务中的数据操纵,保证数据的一致性和完整性。
DML锁主要用于保护并发情况下的数据完整性。
DML 语句能够自动地获得所需的表级锁(TM)与行级(事务)锁(TX)。
它又分为:
( 1) TM 锁(表级锁)
( 2) TX 锁( 事务锁或行级锁)
当 Oracle 执行 DML 语句时,系统自动在所要操作的表上申请 TM 类型的锁。当 TM 锁获得后,系统再自动申请 TX 类型的锁,并将实际锁定的数据行的锁标志位进行置位。
这样在事务加锁前检查 TX锁相容性时就不用再逐行检查锁标志,而只需检查 TM 锁模式的相容性即可,大大提高了系统的效率。
在数据行上只有 X 锁(排他锁)。
在 Oracle 数据库中,当一个事务首次发起一个 DML 语句时就获得一个 TX 锁,该锁保持到事务被提交或回滚。当两个或多个会话在表的同一条记录上执行 DML 语句时,第一个会话在该条记录上加锁,其他的会话处于等待状态。当第一个会话提交后, TX 锁被释放,其他会话才可以加锁。
当 Oracle 数据库发生 TX 锁等待时,如果不及时处理常常会引起 Oracle 数据库挂起,或导致死锁的发生,产生ORA-600 的错误。这些现象都会对实际应用产生极大的危害,如长时间未响应,大量事务失败等。
3.1.1TM 锁(表级锁)
TM 锁用于确保在修改表的内容时,表的结构不会改变,例如防止在 DML 语句执行期间相关的表被移除。当用户对表执行 DDL 或 DML 操作时,将获取一个此表的表级锁。
当事务获得行锁后,此事务也将自动获得该行的表锁(共享锁),以防止其它事务进行 DDL 语句影响记录行的更新。
事务也可以在进行过程中获得共享锁或排它锁,只有当事务显示使用 LOCK TABLE 语 句显示的定义一个排它锁时,事务才会获得表上的排它锁,也可使用 LOCK TABLE 显示的定义一个表级的共享锁。
TM 锁包括了 SS、SX、S、X 等多种模式,在数据库中用 0-6 来表示。不同的 SQL 操作产生不同类型的 TM 锁.
TM 锁类型表
| 锁模式 | 锁描述 | 解释 | SQL操作 |
| 0 | none | :– | :– |
| 1 | NULL | 空 | Select |
| 2 | SS(Row-S) | 行级共享锁,其他对象只能查询数据行 | Select for update、Lock for update、Lock row share |
| 3 | SX(Row-X) | 行级排他锁,在提交前不允许做DML操作 | Insert、Update、Delete、Lock row share |
| 4 | S(Share) | 共享锁 | Create index、Lock share |
| 5 | SSX(S/Row-X) | 共享行级排它锁 | Lock share row exclusive |
| 6 | X(Exclusive) | 排它锁 | Alter table、Drop table、Drop index 、Truncate table、Lock exclusive |
3.1.2TX 锁( 事务锁或行级锁)
当事务执行数据库插入、更新、删除操作时,该事务自动获得操作表中操作行的排它锁。
事务发起第一个修改时会得到TX 锁(事务锁),而且会一直持有这个锁,直至事务执行提交(COMMIT)或回滚(ROLLBACK)。
对用户的数据操纵, Oracle 可以自动为操纵的数据进行加锁,但如果有操纵授权,则为满足并发操纵的需要另外实施加锁。
DML 锁可由一个用户进程以显式的方式加锁,也可通过某些 SQL 语句隐含方式实现。 这部分属于 Manual Data Locks。
原理:一个事务要修改块中的数据,必须获得该块中的一个itl,通过itl和undo segment header中的transaction table,可以知道事务是否处于活动阶段。事务在修改块时(其实就是在修改行)会检查行中row header中的标志位,如果该标志位为0(该行没有被活动的事务锁住),就把该标志位修改为事务在该块获得的itl的序号,这样当前事务就获得了对记录的锁定,然后就可以修改行数据了,这也就是oracle行锁实现的原理。
DML 锁有如下三种加锁方式:
-
共享锁方式( SHARE)
-
独占锁方式( EXCLUSIVE)
-
共享更新锁( SHARE UPDATE)
3.1.1.1共享方式的表级锁( Share)
共享方式的表级锁是对表中的所有数据进行加锁,该锁用于保护查询数据的一致性,防止其它用户对已加锁的表进行更新。
其它用户只能对该表再施加共享方式的锁,而不能再对该表施加独占方式的锁,共享更新锁可以再施加,但不允许持有共享更新封锁的进程做更新。
共享该表的所有用户只能查询表中的数据,但不能更新。
共享方式的表级锁只能由用户用 SQL 语句来设置.
语句格式如下:
LOCK TABLE <表名>\[,<表名>]... IN SHARE MODE \[NOWAIT] 12
- 执行该语句,对一个或多个表施加共享方式的表封锁。
当指定了选择项NOWAIT,若该锁暂时不能施加成功,则返回并由用户决定是进行等待,还是先去执行别的语句。
持有共享锁的事务,在出现如下之一的条件时,便释放其共享锁:
-
A、执行 COMMIT 或 ROLLBACK 语句。
-
B、退出数据库( LOG OFF)。
-
C、程序停止运行。
共享方式表级锁常用于一致性查询过程,即在查询数据期间表中的数据不发生改变。
3.1.1.2独占方式表级锁( Exclusive)
独占方式表级锁是用于加锁表中的所有数据,拥有该独占方式表封锁的用户,即可以查询该表,又可以更新该表,其它的用户不能再对该表施加任何加锁(包括共享、独占或共享更新封锁)。
其它用户虽然不能更新该表,但可以查询该表。
独占方式的表封锁可通过如下的 SQL 语句来显示地获得:
LOCK TABLE <表名>\[,<表名>].... IN EXCLUSIVE MODE \[NOWAIT] 12
- 独占方式的表级锁也可以在用户执行 DML 语句 INSERT、UPDATE、DELETE时隐含获得。
拥有独占方式表封锁的事务,在出现如下条件之一时,便释放该封锁:
-
( 1)、执行 COMMIT 或 ROLLBACK 语句。
-
( 2)、退出数据库( LOG OFF)
-
( 3)、程序停止运行。
独占方式封锁通常用于更新数据,当某个更新事务涉及多个表时,可减少发生死锁.
3.1.1.3共享更新加锁方式( Share Update)
共享更新加锁是对一个表的一行或多行进行加锁,因而也称作行级加锁。表级加锁虽然保证了数据的一致性,但却减弱了操作数据的并行性。
行级加锁确保在用户取得被更新的行到该行进行更新这段时间内不被其它用户所修改。
因而行级锁即可保证数据的一致性又能提高数据操作的迸发性。
可通过如下的两种方式来获得行级封锁:
( 1)、执行如下的 SQL 封锁语句,以显示的方式获得:
LOCK TABLE < 表 名 >[,< 表 名 >]…. IN SHARE UPDATE MODE [NOWAIT] 123456
( 2)、用如下的 SELECT …FOR UPDATE 语句获得:
SELECT <列名>\[,<列名>]...FROM <表名> WHERE <条件> FOR UPDATE OF <列名>\[,<列名>].....\[NOWAIT] 123456
一旦用户对某个行施加了行级加锁,则该用户可以查询也可以更新被加锁的数据行,其它用户只能查询但不能更新被加锁的数据行.
如果其它用户想更新该表中的数据行,则也必须对该表施加行级锁.即使多个用户对一个表均使用了共享更新,但也不允许两个事务同时对一个表进行更新,真正对表进行更新时,是以独占方式锁表,一直到提交或复原该事务为止。
行锁永远是独占方式锁。
当出现如下之一的条件,便释放共享更新锁:
-
( 1)、执行提交( COMMIT)语句;
-
( 2)、退出数据库( LOG OFF)
-
( 3)、程序停止运行。
执行 ROLLBACK 操作不能释放行锁。
3.2DLL锁( dictionary locks)
DDL 锁用于保护数据库对象的结构,如表、索引等的结构定义。
DDL 锁又可以分为:
-
排它 DDL 锁、
-
共享 DDL 锁、
-
分析锁
3.2.1排它 DDL 锁
创建、修改、删除一个数据库对象的 DDL 语句获得操作对象的 排它锁。
如使用 alter table 语句时,为了维护数据的完成性、一致性、合法性,该事务获得一排它 DDL 锁
3.2.2共享 DDL 锁
需在数据库对象之间建立相互依赖关系的 DDL 语句通常需共享获得 DDL锁。
如创建一个包,该包中的过程与函数引用了不同的数据库表,当编译此包时该事务就获得了引用表的共享 DDL 锁。
3.2.3分析锁
ORACLE 使用共享池存储分析与优化过的 SQL 语句及 PL/SQL 程序,使运行相同语句的应用速度更快。
一个在共享池中缓存的对象获得它所引用数据库对象的分析锁。
分析锁是一种独特的 DDL 锁类型, ORACLE 使用它追踪共享池对象及它所引用数据库对象之间的依赖关系。
当一个事务修改或删除了共享池持有分析锁的数据库对象时, ORACLE 使共享池中的对象作废,下次在引用这条SQL/PLSQL 语 句时, ORACLE 重新分析编译此语句。
DDL 级加锁也是由 ORACLE RDBMS 来控制,它用于保护数据字典和数据定义改变时的一致性和完整性。 它是系统在对 SQL 定义语句作语法分析时自动地加锁,无需用户干予。
字典/语法分析加锁共分三类:
-
( 1)字典操作锁:
-
( 2) 字典定义锁:
-
( 3)表定义锁:
3.3 System Locks
oracle使用不同类型的系统锁来保护内部数据库和内存结构.
这些机制是用户无法访问的。
4.内部闩锁
内部闩锁:这是ORACLE中的一种特殊锁,用于顺序访问内部系统结构。当事务需向缓冲区写入信息时,为了使用此块内存区域,ORACLE首先必须取得这块内存区域的闩锁,才能向此块内存写入信息。
主从同步
1 利用Oracle自身组件
DG方案
DG方案也叫ADG方案,英语全称Physical Standby(Active DataGuard)。支持恢复与只读并行,但由于并不是日志的逻辑应用机制,在读写分离的场景中最为局限 ,将生产机的logfiles传递给容灾机,通过Redo Apply技术来保障数据镜像能力,物理上提供了与生产数据库在数据块级的一致性镜像,也叫physical方式。Physical方式支持异步传输方式,但容灾机处在恢复状态,不可用;
Logical Standby
通过SQL Apply(即Log Miner)技术,将接收到的日志文件还原成SQL语句,并在逻辑备份数据库上执行,从而达到数据一致性的目的,也叫logical 方式。logical方式只支持同步传输方式,但容灾机可以处在read-only状态
Streams
实时将数据复制到另外一个库供读取。最灵活,但最不稳定。
2 选择商业化第三方的产品
GoldenGate 虽然属于第三方,但是已经被Oracle收购!
老牌的Shareplex,还是本土DSG公司的RealSync和九桥公司的DDS,或是Oracle新贵GoldenGate,都是可供选择的目标。
随着GoldenGate被Oracle收购和推广,个人认为GoldenGate在容灾、数据分发和同步方面将大行其道。
DSG RealSync同步du软件的实现方案:
扩展知识:
读写分离的重点其实就是数据同步,能实现数据实时同步的技术很多,基于OS层(例如VERITAS VVR),基于存储复制(中高端存储大多都支持),基于应用分发或者基于数据库层的技术。因为数据同步可能并不是单一的DB整库同步,会涉及到业务数据选择以及多源整合等问题,因此OS复制和存储复制多数情况并不适合做读写分离的技术首选。
基于日志的Oracle复制技术,Oracle自身组件可以实现,同时也有成熟的商业软件。选商业的独立产品还是Oracle自身的组件功能,这取决于多方面的因素。比如团队的相应技术运维能力、项目投入成本、业务系统的负载程度等。
| Oracle DataGuard | Oracle GoldenGate |
| :—— | :———————————————- | :———————————————————————————————————– |
| 原理 | 复制归档日志或在线日志 | 抽取在线日志中的数据变化,转换为GGS自定义的数据格式存放在本地队列或远端队列中 |
| 稳定性 | 作为灾备的稳定性极高 | 稳定性不如DataGuard |
| 维护 | 维护简单,极少出现问题 | 命令行方式,维护较复杂 |
| 对象支持 | 完全支持 | 部分对象需手工创建于维护 |
| 备份端可用性 | 备份端处于恢复或只读状态,在只读状态下不能同时进行恢复。 | 两端数据库是活动的,备份端可以提供实时的数据查询及报表业务等,从而提高系统整体的业务处理能力,充分利用备份端的计算能力,提升系统整体业务处理性能。可以实现两端数据的同时写入 |
| 接管时间 | 数据库工作在mount状态下,接管业务时,数据库要open | 可实现立即接管 |
| 复制方式 | 通过恢复机制实现的,无法实现同步复制 | GoldenGate可以提供秒一级的大量数据实时捕捉和投递,异步复制方式,无法实现同步复制 |
| 资源占用 | 复制通过数据库的LGWR进程或ARCN进程完成,占用数据库少量资源 | 业务高峰时在数据抽取转换时消耗系统资源较多,低峰时占用较小 |
| 异构数据库支持 | 单一数据库解决方案,仅运行在Oracle数据库上,源端和目标端操作系统必须相同,版本号可以不同 | 可以在不同类型和版本的数据库之间进行数据复制。如ORACLE,DB2,SYBASE,SQL SERVER,INFORMIX、Teradata等。 适用于不同操作系统如windows、Linux、unix、aix等 |
| 带宽占用 | 使用Oracle Net传输日志,可通过高级压缩选项进行压缩,压缩比在2-3倍 | 利用TCP/IP传输数据变化,集成数据压缩,提供理论可达到9:1压缩比的数据压缩特性 |
| 拓扑结构 | 可以实现一对多模式 | 可以实现一对一、一对多、多对一、双向复制等多种拓扑结构 |
Docker 安装
Docker Compose 安装 第一种方法:由于官网使用的是 curl安装方法,实在太慢,不敢恭维 0.ubuntu apt-get下载慢 解决办法 1.更新源 sudo apt-install update 2.安装python-pip sudo apt install python3-pip 3.查看版本 sudo pip –version 4.更新pip版本 sudo pip install –upgrade pip 5.安装docker-compose sudo pip install docker-compose 6.查看docker-compose版本 sudo docker-compose –version 以上安装完成 更新docker-compose 版本 sudo pip install –upgrade docker-comopse 卸载pip安装的应用 sudo pip uninstall 引用名如docker-compose 卸载pip sudo apt-get remove docker-compose