数据库基础
数据库基础
数据库范式
数据库有三大范式。
范式的简介
范式的英文名称是Normal Form,它是英国人E.F.Codd(关系数据库的老祖宗)在上个世纪70年代提出关系数据库模型后总结出来的。范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。目前有迹可寻的共有8种范式,依次是:1NF,2NF,3NF,BCNF,4NF,5NF,DKNF,6NF。通常所用到的只是前三个范式,即:第一范式(1NF),第二范式(2NF),第三范式(3NF)。
数据往往种类繁多,而且每种数据之间又互相关联,因此,在设计数据库时,所需要满足的范式越多,那表的层次及结构也就越复杂,最终造成数据的处理困难。这样,还不如不满足这些范式呢。所以在使用范式的时候也要细细斟酌,是否一定要使用该范式,必须根据实际情况做出选择。一般情况下,我们使用前三个范式已经够用了,不再使用更多范式,就能完成对数据的优化,达到最优效果。
通俗的理解
第一范式就是属性不可分割,每个字段都应该是不可再拆分的。比如一个字段是姓名(NAME),在国内的话通常理解都是姓名是一个不可再拆分的单位,这时候就符合第一范式;但是在国外的话还要分为FIRST NAME和LAST NAME,这时候姓名这个字段就是还可以拆分为更小的单位的字段,就不符合第一范式了。
第二范式就是要求表中要有主键,表中其他其他字段都依赖于主键,因此第二范式只要记住主键约束就好了。比如说有一个表是学生表,学生表中有一个值唯一的字段学号,那么学生表中的其他所有字段都可以根据这个学号字段去获取,依赖主键的意思也就是相关的意思,因为学号的值是唯一的,因此就不会造成存储的信息对不上的问题,即学生001的姓名不会存到学生002那里去。
第三范式就是要求表中不能有其他表中存在的、存储相同信息的字段,通常实现是在通过外键去建立关联,因此第三范式只要记住外键约束就好了。比如说有一个表是学生表,学生表中有学号,姓名等字段,那如果要把他的系编号,系主任,系主任也存到这个学生表中,那就会造成数据大量的冗余,一是这些信息在系信息表中已存在,二是系中有1000个学生的话这些信息就要存1000遍。因此第三范式的做法是在学生表中增加一个系编号的字段(外键),与系信息表做关联。
数据库备份
冷备份发生在数据库已经正常关闭的情况下,将关键性文件拷贝到另外位置的一种说法 热备份是在数据库运行的情况下,采用归档方式备份数据的方法
冷备的优缺点:
1.是非常快速的备份方法(只需拷贝文件)
2.容易归档(简单拷贝即可)
3.容易恢复到某个时间点上(只需将文件再拷贝回去)
4.能与归档方法相结合,作数据库“最新状态”的恢复。
5.低度维护,高度安全。
冷备份不足:
1.单独使用时,只能提供到“某一时间点上”的恢复。
2.在实施备份的全过程中,数据库必须要作备份而不能作其它工作。也就是说,在冷备份过程中,数据库必须是关闭状态。
3.若磁盘空间有限,只能拷贝到磁带等其它外部存储设备上,速度会很慢。
4.不能按表或按用户恢复。
热备的优缺点
1.可在表空间或数据文件级备份,备份时间短。
2.备份时数据库仍可使用。
3.可达到秒级恢复(恢复到某一时间点上)。
4.可对几乎所有数据库实体作恢复。
5.恢复是快速的,在大多数情况下在数据库仍工作时恢复。
热备份的不足是:
1.不能出错,否则后果严重。
2.若热备份不成功,所得结果不可用于时间点的恢复。
3.因难于维护,所以要特别仔细小心,不允许“以失败而告终”。
锁
当并发事务同时访问一个资源时,有可能导致数据不一致,因此需要一种机制来将数据访问顺序化,以保证数据库数据的一致性。
数据库角度
独占锁,Oracle称为排他锁(Exclusive Lock,也叫X锁)独占锁锁定的资源只允许进行锁定操作的程序使用,其它任何对它的操作均不会被接受。执行数据更新命令,即INSERT、UPDATE 或DELETE 命令时,SQL Server 会自动使用独占锁。但当对象上有其它锁存在时,无法对其加独占锁。独占锁一直到事务结束才能被释放。
共享锁(Shared Lock,也叫S锁)共享锁锁定的资源可以被其它用户读取,但其它用户不能修改它。在SELECT 命令执行时,SQL Server 通常会对对象进行共享锁锁定。通常加共享锁的数据页被读取完毕后,共享锁就会立即被释放。
更新锁(Update Lock)更新锁是为了防止死锁而设立的。当SQL Server 准备更新数据时,它首先对数据对象作更新锁锁定,这样数据将不能被修改,但可以读取。等到SQL Server 确定要进行更新数据操作时,它会自动将更新锁换为独占锁。但当对象上有其它锁存在时,无法对其作更新锁锁定。
程序员角度
乐观锁(Optimistic Lock)乐观锁假定在处理数据时,不需要在应用程序的代码中做任何事情就可以直接在记录上加锁、即完全依靠数据库来管理锁的工作。一般情况下,当执行事务处理时SQL Server会自动对事务处理范围内更新到的表做锁定。
悲观锁(Pessimistic Lock)悲观锁对数据库系统的自动管理不感冒,需要程序员直接管理数据或对象上的加锁处理,并负责获取、共享和放弃正在使用的数据上的任何锁。
Oracle中可以使用:
select * from t for update: 会等待行锁释放之后,返回查询结果。
select * from t for update nowait: 不等待行锁释放,提示锁冲突,不返回结果
select * from t for update wait 5: 等待5秒,若行锁仍未释放,则提示锁冲突,不返回结果
select * from t for update skip locked: 查询返回查询结果,但忽略有行锁的记录
【使用格式】
SELECT…FOR UPDATE 语句的语法如下:
| SELECT … FOR UPDATE [OF column_list][WAIT n | NOWAIT][SKIP LOCKED]; |
其中:
OF 子句用于指定即将更新的列,即锁定行上的特定列。
WAIT 子句指定等待其他用户释放锁的秒数,防止无限期的等待。
SqlServer中可以使用显式事务:
begin transaction\
select * from ls1 with (tablockx) where f_account_id=37
….
….
update ls1 set …..
commit;
悲观锁与乐观锁的优缺点:乐观锁适用于写入比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行重试操作,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适.
锁模式
共享 (S)
用于不更改或不更新数据的操作(只读操作),如 SELECT 语句。 更新 (U) 用于可更新的资源中。防止当多个会话在读取、锁定以及随后可能进行的资源更新时发生常见形式的死锁。 排它 (X) 用于数据修改操作,例如 INSERT、UPDATE 或 DELETE。确保不会同时同一资源进行多重更新。 意向锁 用于建立锁的层次结构。意向锁的类型为:意向共享 (IS)、意向排它 (IX) 以及与意向排它共享 (SIX)。 架构锁 在执行依赖于表架构的操作时使用。架构锁的类型为:架构修改 (Sch-M) 和架构稳定性 (Sch-S)。 大容量更新 (BU) 向表中大容量复制数据并指定了 TABLOCK 提示时使用。
共享锁
共享 (S) 锁允许并发事务读取 (SELECT) 一个资源。资源上存在共享 (S) 锁时,任何其它事务都不能修改数据。一旦已经读取数据,便立即释放资源上的共享 (S) 锁,除非将事务隔离级别设置为可重复读或更高级别,或者在事务生存周期内用锁定提示保留共享 (S) 锁。
更新锁
更新 (U) 锁可以防止通常形式的死锁。一般更新模式由一个事务组成,此事务读取记录,获取资源(页或行)的共享 (S) 锁,然后修改行,此操作要求锁转换为排它 (X) 锁。如果两个事务获得了资源上的共享模式锁,然后试图同时更新数据,则一个事务尝试将锁转换为排它 (X) 锁。共享模式到排它锁的转换必须等待一段时间,因为一个事务的排它锁与其它事务的共享模式锁不兼容;发生锁等待。第二个事务试图获取排它 (X) 锁以进行更新。由于两个事务都要转换为排它 (X) 锁,并且每个事务都等待另一个事务释放共享模式锁,因此发生死锁。
若要避免这种潜在的死锁问题,请使用更新 (U) 锁。一次只有一个事务可以获得资源的更新 (U) 锁。如果事务修改资源,则更新 (U) 锁转换为排它 (X) 锁。否则,锁转换为共享锁。
排它锁
排它 (X) 锁可以防止并发事务对资源进行访问。其它事务不能读取或修改排它 (X) 锁锁定的数据。
意向锁
意向锁表示 SQL Server 需要在层次结构中的某些底层资源上获取共享 (S) 锁或排它 (X) 锁。例如,放置在表级的共享意向锁表示事务打算在表中的页或行上放置共享 (S) 锁。在表级设置意向锁可防止另一个事务随后在包含那一页的表上获取排它 (X) 锁。意向锁可以提高性能,因为 SQL Server 仅在表级检查意向锁来确定事务是否可以安全地获取该表上的锁。而无须检查表中的每行或每页上的锁以确定事务是否可以锁定整个表。
意向锁包括意向共享 (IS)、意向排它 (IX) 以及与意向排它共享 (SIX)。
锁的范围
锁粒度是被封锁目标的大小,封锁粒度小则并发性高,但开销大,封锁粒度大则并发性低但开销小
SQL Server支持的锁粒度可以分为为行、页、键、键范围、索引、表或数据库获取锁
死锁
当两个用户希望持有对方的资源时就会发生死锁.即两个用户互相等待对方释放资源时,oracle认定为产生了死锁,在这种情况下,将以牺牲一个用户作为代价,另一个用户继续执行,牺牲的用户的事务将回滚。
场景
1:用户 1 对 A 表进行 Update,没有提交。
2:用户 2 对 B 表进行 Update,没有提交。
此时双反不存在资源共享的问题。
3:如果用户 2 此时对 A 表作 update,则会发生阻塞,需要等到用户一的事物结束。
4:如果此时用户 1 又对 B 表作 update,则产生死锁。此时 Oracle 会选择其中一个用户进行会滚,使另一个用户继续执行操作。
类似如下操作
增设table2(D,E)
D E
d1 e1
d2 e2
在第一个连接中执行以下语句
begin tran
update table1 set A=’aa’ where B=’b2’
waitfor delay ’00:00:30’
update table2 set D=’d5’ where E=’e1’ commit tran
在第二个连接中执行以下语句
begin tran
update table2 set D=’d5’ where E=’e1’
waitfor delay ’00:00:10’
update table1 set A=’aa’ where B=’b2’commit tran
在 Oracle 系统中能自动发现死锁,并选择代价最小的,即完成工作量最少的事务予以撤消,释放该事务所拥有的全部锁,记其它的事务继续工作下去。
解决办法:
- 查找出被锁的表
select b.owner,b.object_name,a.session_id,a.locked_mode
from v$locked_object a,dba_objects b
where b.object_id = a.object_id;
select b.username,b.sid,b.serial#,logon_time
from v$locked_object a,v$session b
where a.session_id = b.sid order by b.logon_time;
| 与Oracle类似,SQL Server提供了自动检测和处理死锁的功能。当系统检测到死锁时,SQL Server会选择一个运行撤消时花费最少的事务作为死锁牺牲品,并通知应用程序取消当前请求,以便事务可以继续进行。设置死锁优先级–设置死锁的优先级,调整一个查询会话由于死锁而被终止运行的可能性SET DeadLock_Priority Low | Normal | High | numeric-priority。 |
–是当前连接很有可能被终止运行
set deadlock_priority Low
–SQL Server终止回滚代价较小的连接
set deadlock_priority Normal
–减少连接被终止的可能性,除非另一个连接也是High或数值优先级大于5
set deadlock_priority High
–数值优先级:-10到10的值,-10最有可能被终止运行,10最不可能被终止运行,
–两个数字谁大,谁就越不可能在死锁中被终止
set deadlock_priority 10
从系统性能上考虑,应该尽可能减少资源竞争,增大吞吐量,因此用户在给并发操作加锁时,应注意以下几点:
-
1、对于 UPDATE 和 DELETE 操作,应只锁要做改动的行,在完成修改后立即提交。
-
2、当多个事务正利用共享更新的方式进行更新,则不要使用共享封锁,而应采用共享更新锁,这样其它用户就能使用行级锁,以增加并行性。
-
3、尽可能将对一个表的操作的并发事务施加共享更新锁,从而可提高并行性。
-
4、在应用负荷较高的期间,不宜对基础数据结构(表、索引、簇和视图)进行修改
如何避免死锁\
1 使用事务时,尽量缩短事务的逻辑处理过程,及早提交或回滚事务;\
2 设置死锁超时参数为合理范围,如:3分钟-10分种;超过时间,自动放弃本次操作,避免进程悬挂;\
3 优化程序,检查并避免死锁现象出现;\
4 .对所有的脚本和SP都要仔细测试,在正是版本之前。\
5 所有的SP都要有错误处理(通过@error)\
6 一般不要修改SQL SERVER事务的默认级别。不推荐强行加锁
事务
ACID 原则
原子性 (Atomicity):事务的原子性是指一个事务中包含的一条语句或者多条语句构成了一个完整的逻辑单元,这个逻辑单元具有不可再分的原子性。这个逻辑单元要么一起提交执行全部成功,要么一起提交执行全部失败。
一致性 (Consistency):可以理解为数据的完整性,事务的提交要确保在数据库上的操作没有破坏数据的完整性,比如说不要违背一些约束的数据插入或者修改行为。一旦破坏了数据的完整性,SQL Server 会回滚这个事务来确保数据库中的数据是一致的。
隔离性(Isolation):与数据库中的事务隔离级别以及锁相关,多个用户可以对同一数据并发访问而又不破坏数据的正确性和完整性。但是,并行事务的修改必须与其它并行事务的修改相互独立,隔离。但是在不同的隔离级别下,事务的读取操作可能得到的结果是不同的。
持久性(Durability):数据持久化,事务一旦对数据的操作完成并提交后,数据修改就已经完成,即使服务重启这些数据也不会改变。相反,如果在事务的执行过程中,系统服务崩溃或者重启,那么事务所有的操作就会被回滚,即回到事务操作之前的状态。
事务隔离级别:
1、用于控制并发用户如何读写数据的操做。
2、读操作默认使用共享锁;写操作需要使用排它锁。
3、读操作能够控制他的处理的方式,写操作不能控制它的处理方式
read uncommited(读取未提交数据),
read commited(读取已提交数据)读取的默认方式,(ORACLE 默认)
repeatable read(可重复读),(MySQL,MSSQL 默认)
serializable(可序列化),
snapshot(快照),
read commited
snapshot(已经提交读隔离)(后两个是sql server 2005 里面 引入的)。
隔离的强度依次递增。
隔离级别越高,读操作的请求锁定就越严格,
锁的持有时间久越长;所以隔离级别越高,
一致性就越高,并发性就越低,同时性能也相对影响越大.
read uncommited(读取未提交数据),
read uncommitted:最低的隔离级别:查询的时候不会请求共享锁,
所以不会和排它锁产生冲突(不会等待排它锁执行完),
查询效率非常高,速度飞快。但是缺点:会查到“脏数据”
(排它锁的事务已经将数据修改,还没提交,这个时候查询到的数据 是已经更改过的。如果事务回滚,就是“脏数据”)
优点:查询效率非常高,速度非常快。
缺点:会产生“脏数据”
适用性:
适用于 像聊天软件的 聊天记录,会是软件的运行速度非常快。 但是不适用于 商务软件。尤其是银行
set transaction isolation level read uncommitted;
read commited(读取已提交数据)读取的默认方式,
读取的默认隔离级别就是read committed 和上面正好相反。
如果上面情况,采用read committed 隔离级别查询的话查到的就是还没有更改之前的数据。
set transaction isolation level read committed;
repeatable read(可重复读),
查询的时候会加上共享锁,但是查询完成之后,共享锁就会被撤销。
比如一些购票系统,如果查到票了,当买的时候就没有,这是不行的。
所以要在查询到数据之后做一些延迟共享锁,进而阻塞排它锁来修改。
(如果查询的事务没有提交,不会释放共享锁,这个时候独占锁就不能访问这条数据)
注意:
1、repeatable 只会锁定查询的数据 ,而 其他行数据还可以进行 修改(更新、删除)(下面那条语句共享锁只会锁定 shipperid为4 的行)
2、其他进行插入数据,并且插入的数据满足第一次开始事务时的 查询的筛选条件的时候;
第二次查询的时候就会将新插入的数据 查询出来。这就叫做“幻读”(解决幻读,需要更高级别的隔离,就是下面的serializable)
set transaction isolation level repeatable read;
serializable(可序列化),
更高级的 隔离。用户解决“幻读”(上面提到的)。
就是使用上面的(repeatable read) 加上共享锁 并不撤销,如果锁定的 一行数据,
那么 其他的进程 还可以对 其他的数据进行操作,也可以 进行新增和删除的操作。
所以如果想要在查询的时候,不能对整张表进行任何操作,
那么就要 将表的结构也 锁定 (就需要使用 更强的 锁定)
set transaction isolation level serializable;
ISO只规定以上四级
SNAPSHOT ISOLATION(快照,MSSQL独有),
为数据产生一个临时数据库,当sql server 数据更新之前将当前数据库复制到 tempdb数据库里面,
查询就是从tempdb数据库中查询,但是不能再 使用 snapshot 线程的事务内执行 修改操作,
因为不能修改 旧版本数据库(tempdb),会报错。
snapshot隔离级别,读操作 不适用 共享锁,使用的是“行版本控制”,
所以读数据的性能效率很高,但是修改操作性能就降低的很多。
因为是将 数据库 中的数据 复制到 tempdb 数据库中,所以不会产生 幻读。
set transaction isolation level snapshot;
带来两个问题:
1、当 另外一个事务 已经提交,但是这边的查询到数据还是没有修改。因为 每次查询到的快照是针对于 本次回话对应的那个 transaction 的,因为在这个事务里面是没有修改的,所以查询到的数据是没有修改的。
2、(更新问题)因为 那边的数据已经是 飞凤公司了,但是这里还是 联邦,所以,在这个事务里面是不能对表进行修改,因为访问的是临时数据库,想要对 数据库修改是不可能的(sql server 就会报错,阻止修改)
存储过程
存储过程是预编译,安全性高,也是大大提高了效率,存储过程可以重复使用以减少数据库开发人员的工作量,复杂的逻辑我们可以使用存储过程完成,在存储过程中我们可以使用临时表,还可以定义变量,拼接sql语句,调用时,只需执行这个存储过程名,传入我们所需要的参数即可。
存储过程优缺点:
优点:
-
存储过程增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
-
可保证数据的安全性和完整性。
3. 通过存储过程可以使没有权限的用户在控制之下间接地存取数据库,从而保证数据的安全。
通过存储过程可以使相关的动作在一起发生,从而可以维护数据库的完整性。
-
再运行存储过程前,数据库已对其进行了语法和句法分析,并给出了优化执行方案。这种已经编译好的过程可极大地改善SQL语句的性能。 由于执行SQL语句的大部分工作已经完成,所以存储过程能以极快的速度执行。
-
可以降低网络的通信量, 不需要通过网络来传送很多sql语句到数据库服务器了
-
使体现企业规则的运算程序放入数据库服务器中,以便集中控制
当企业规则发生变化时在服务器中改变存储过程即可,无须修改任何应用程序。企业规则的特点是要经常变化,如果把体现企业规则的运算程序放入应用程序中,则当企业规则发生变化时,就需要修改应用程序工作量非常之大(修改、发行和安装应用程序)。如果把体现企业规则的 运算放入存储过程中,则当企业规则发生变化时,只要修改存储过程就可以了,应用程序无须任何变化。
缺点:
-
可移植性差
-
占用服务器端多的资源,对服务器造成很大的压力
-
可读性和可维护性不好
函数
Oracle中function和procedure的区别?
-
可以理解函数是存储过程的一种
-
函数可以没有参数,但是一定需要一个返回值,存储过程可以没有参数,不需要返回值
-
函数return返回值没有返回参数模式,存储过程通过out参数返回值, 如果需要返回多个参数则建议使用存储过程
-
在sql数据操纵语句中只能调用函数而不能调用存储过程
触发器
触发器是一种特殊的存储过程,主要是通过事件触发而被执行。它可以强化约束来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以级联运算。
常见的触发器有三种:分别应用于Insert , Update , Delete 事件。
数据库优化
这个问题说大不大,说难不难,很多人盲目说优化,其实这本身就是是有问题的。首先,为什么要优化,我们的需求,性能满足的时候还用的着优化吗?当然不了,优化自然是针对其中的问题,性能瓶颈来进行。如果接受的是严谨的教育,他所做的一切数据库操作自然都是规范合规,当然也是最佳,当然也根本无论谈论优化了。当然了,对于这些规范的操作可以进行总结,也可以视为数据库优化了。总结按照以下分类和方法进行优化。
硬件方面
工欲善其事,必欲利其器,大内存,多核心cpu,高速硬盘,高带宽对于提升数据库性能有不少的帮助,当然这自然是以来用户预算,在足够的预算下对硬件的提升对整体数据库的提升有不少帮助。
软件方面
合适的操作系统,Linux等操作系统的性能相当windows来说要好不少,当然也会让数据库发挥最佳性能。
合适的数据库,有些数据库本身就不适合大数据量,如果数据量特别巨大,那么停止优化,切换数据库不失为最佳的选择。
数据库设计
合适的字段
合适的表设计
合适的分表
合适的索引
读写分离
大的数据表尽量使用独立的表空间
查询优化
尽可能获取需要的最少信息
减少函数,尤其是聚合函数的使用
尽次可能单查询
问题诊断定位 执行计划检查
常见SQL语句的问题
比如常用的字段建索引,联合查询考虑联合索引。(PS:如果你有基础,可以敞开谈谈聚集索引和非聚集索引的使用场景和区别)
避免select * 的写法、尽量不用in和not in 这种耗性能的用法等等。
尽量避免大事务操作、减少循环算法,对于大数据量的操作,避免使用游标的用法等等。
程序的优化
尽可能分页查询
缓存的使用,尽可能使用内存数据库进行换缓存避免数据重复查询增加服务器负担。
SQL语言
ANSI SQL
“美国国家标准化组织(ANSI)”是一个核准多种行业标准的组织。SQL作为关系型数据库所使用的标准语言,最初是基于IBM的实现1986年被批准的。1987年,“国际标准化组织(ISO)”把ANSI SQL作为国际标准。这个标准在1992年进行了修订(SQL-92),1999年再次修订(SQL-99)。最新的是SQL-2011。
最新为SQL ANSI-2011(ISO/IEC TR 19075)
标准 版本 标题 委员会
ISO/IEC TR 19075-1:2011 1 Part 1: XQuery Regular Expression Support in SQL ISO/IEC JTC 1/SC 32
ISO/IEC TR 19075-2:2015 2 Part 2: SQL Support for Time-Related Information ISO/IEC JTC 1/SC 32
ISO/IEC TR 19075-3:2015 1 Part 3: SQL Embedded in Programs using the JavaTM programming language ISO/IEC JTC 1/SC 32
ISO/IEC TR 19075-4:2015 1 Part 4: SQL with Routines and types using the JavaTM programming language ISO/IEC JTC 1/SC 32
ISO/IEC TR 19075-5:2016 1 Part 5: Row Pattern Recognition in SQL ISO/IEC JTC 1/SC 32
ISO/IEC TR 19075-6:2017 1 Part 6: SQL support for JavaScript Object Notation (JSON) ISO/IEC JTC 1/SC 32
ISO/IEC TR 19075-7:2017 1 Part 7: Polymorphic table functions in SQL ISO/IEC JTC 1/SC 32
DDL
其语句包括动词CREATE,ALTER和DROP。在数据库中创建新表或修改、删除表(CREATE TABLE 或 DROP TABLE);为表加入索引等。
create
常用数据类型
varchar2(n):变长字符串n<=4000
char(n):定长字符串n<=2000
number(p,s):p表示精度,s表示小数位数,最大位数是38位
date:时问日期(7字节)
binary_float:浮点型,32位
binary_double:双精度型,64位
blob:大二进制对象,<=4G
clob:大字符串对象,<=4G
bfile:外部的二进制文件
表
主键
在创建表时定义主键
使用alter table语句定义主键
使用alter table修改主键状态
外键
在创建表时定义外键
使用alter table语句定义外键
使用alter table修改外键状态
约束
check约束
Check约束用以限制单列的可能取值范围,需要在Check约束中指定逻辑表达式,该逻辑表达式必须返回逻辑值(TRUE或FALSE),在Check中,把UNKNOWN值认为是TRUE。
check(expression)
1,在check约束中
如果expression返回的结果是Unknown,那么check返回的结果是true。
create table dbo.dt_check
(
id int null constraint ck_ID_is_Positive check(id>0)
)
插入数据,测试check约束的工作机制
insert into dbo.dt_check
values(null)
insert into dbo.dt_check
values(1)
insert into dbo.dt_check
values(0)
INSERT 语句与 CHECK 约束”ck_ID_is_Positive”冲突。该冲突发生于数据库”db_study”,表”dbo.dt_check”, column ‘id’。
语句已终止。
NULL和1 插入成功,而0插入失败。
2,在表级别上定义Check约束
在表级别上定义Check约束,可以对多列的可能取值进行限制
create table dbo.dt_check
(
id int null ,
code int null,
constraint ck_IDCode_is_Positive check(id>0 and code >0)
)
在一个已经创建的table上,通过alter table命令来增加、修改和删除check约束,添加的约束是表级别的约束
3,增加check约束
alter table dbo.dt_check
add constraint ck_ID_is_Positive check(id>0)
4,删除check约束
alter table dbo.dt_check
drop constraint ck_ID_is_Positive
5,修改Check约束
没法直接修改Check约束,变通方法是:必须先删除约束,然后添加新的check约束
alter table dbo.dt_check
drop constraint ck_ID_is_Positive
alter table dbo.dt_check
add constraint ck_ID_is_Positive check(id>0)
6,通过alter table命令增加新的列,并在列级别上创建check 约束
alter table dbo.dt_check
add sex char(1) not null
constraint ck_sex check(sex in(‘M’,’F’))
not null约束
unique约束
索引
视图
序列
同义词
drop
alter
DML(DML:Data Manipulation Language)
insert
插入数据
复制表数据
create table…as select…
insert into…select
update
merge
delete
truncate
DQL(DQL: Data Query Language)
select
from子句
投影
where子句
比较运算符
=
<>
<
<=
=
LIKE
%
_
布尔操作
OR
AND
NOT
BETWEEN…AND…IN
order by子句
asc
desc
distinct
算数运算:
*
/
基本函数
字符函数
concat(c1,c2)
length(c)
lower(c)/upper(c)
ltrim(c)/rtrim(c)/trim(c)
replace(c1,c2,c3)
substr(c1,i,j)
数字函数
abs(n)
acos(n)/asin(n)/atan(n)/cos(n)/sin(n)/tan(n)
ceil(n)/floor(n)
exp(n)/ln(n)
power(n1,n2)
round(n1,n2)
sign(n)
sqrt(n)
日期函数
add_months(d,i)
last_day(d)
month_between(d1,d2)
new_time(d,tz1,tz2)
sysdate
转换函数
convert(c,dset,sset)
to_char(x,fmt)
to_date(c,fmt)
分组函数/聚合函数
AVG
MAX
MIN
SUM
COUNT
STDDEV
VARIANCE
group by
having子句
集合操作
UNION
INTERSECT
MINUS
子查询
表连接
内连接 inner join
外连接
左外连接
右外连接
全外连接
case语句
decode函数
DCL(数据控制语言 Data Control Language )
它的语句通过GRANT或REVOKE实现权限控制,确定单个用户和用户组对数据库对象的访问。某些RDBMS可用GRANT或REVOKE控制对表单个列的访问。
grant
revoke
TCL(事务控制语言)
它的语句能确保被DML语句影响的表的所有行及时得以更新。包括COMMIT(提交)命令、SAVEPOINT(保存点)命令、ROLLBACK(回滚)命令。
CCL(指针控制语言)
它的语句,像DECLARE CURSOR,FETCH INTO和UPDATE WHERE CURRENT用于对一个或多个表单独行的操作。
常见函数
- sign() decode()函数用法(sql server ,oracle,mysql支持)
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1 ,例如:
decode ()函数说明:
decode (
expression,
condition_01, result_01,
condition_02, result_02,
……,
condition_n, result_n,
result_default)
若表达式expression值与condition_01值匹配,则返回result_01,若不匹配,则继续判断; 若表达式expression值与condition_02值匹配,则返回result_02,若不匹配,则继续判断;
。。。。。
select courseid, coursename ,score ,decode(sign(score-60),-1,’fail’,’pass’) as mark from course
-
pivot unpivot 行业转换函数(sql server ,mysql支持)
select * from tb
-——————————-结果————————————————————————————
姓名 课程 分数\
-——— ———- ———–\
张三 语文 74\
张三 数学 83\
张三 物理 93\
李四 语文 74\
李四 数学 84\
李四 物理 94\
\
现在的问题是:我想根据姓名统计这个人的三门成绩,即:姓名 语文 数学 物理
-——————————-结果————————————————————————————
姓名 语文 数学 物理\
-——— ———– ———– ———–\
李四 74 84 94\
张三 74 83 93
\
首先看看使用case when end结构的时候:
select 姓名,\
max(case 课程 when ‘语文’ then 分数 else 0 end)语文,\
max(case 课程 when ‘数学’then 分数 else 0 end)数学,\
max(case 课程 when ‘物理’then 分数 else 0 end)物理\
from tb\
group by 姓名
这个结果就是我们想要的,数据列少的时候,如果多的时候就需要使用pivot:
select * from tb pivot(max(分数) for 课程 in (语文,数学,物理))a
unpivot 用法类似:
select 姓名,课程,分数 from tb unpivot (分数 for 课程 in ([语文],[数学],[物理]) ) t
MySQL
Ubuntu Docker部署mysql
1.创建安装目录 mnt为硬盘挂载目录,根据实际情况修改
sudo mkdir -p /mnt/mysql
cd /mnt/mysql
sudo gedit docker-compose.yml
2.编写docker-compose.yml
version: ‘3.1’
services:
db:
image: mysql:8.0 #mysql版本
volumes:
-
/data/db:/var/lib/mysql
-
./etc/my.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf
restart: always
ports:
- 33306:3306
environment:
MYSQL_ROOT_PASSWORD: 123456 #访问密码
secure_file_priv:
3.创建配置文件
cd /mnt/mysql
sudo mkdir etc
gedit my.cnf
[mysqld]
character-set-server=utf8
log-bin=mysql-bin
server-id=1
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
symbolic-links=0
secure_file_priv =
wait_timeout=120
interactive_timeout=120
default-time_zone = ‘+8:00’
skip-external-locking
skip-name-resolve
open_files_limit = 10240
max_connections = 1000
max_connect_errors = 6000
table_open_cache = 800
max_allowed_packet = 40m
sort_buffer_size = 2M
join_buffer_size = 1M
thread_cache_size = 32
query_cache_size = 64M
transaction_isolation = READ-COMMITTED
tmp_table_size = 128M
max_heap_table_size = 128M
log-bin = mysql-bin
sync-binlog = 1
binlog_format = ROW
binlog_cache_size = 1M
key_buffer_size = 128M
read_buffer_size = 2M
read_rnd_buffer_size = 4M
bulk_insert_buffer_size = 64M
lower_case_table_names = 1
explicit_defaults_for_timestamp=true
skip_name_resolve = ON
event_scheduler = ON
log_bin_trust_function_creators = 1
innodb_buffer_pool_size = 512M
innodb_flush_log_at_trx_commit = 1
innodb_file_per_table = 1
innodb_log_buffer_size = 4M
innodb_log_file_size = 256M
innodb_max_dirty_pages_pct = 90
innodb_read_io_threads = 4
innodb_write_io_threads = 4
4.docker-compose构建
cd /mnt/mysql
docker-compose up -d
5.验证启动状态
6.优化指南
max_connections:允许客户端并发连接的最大数量,默认值是151,一般将该参数设置为500-2000
max_connect_errors:如果客户端尝试连接的错误数量超过这个参数设置的值,则服务器不再接受新的客户端连接。可以通过清空主机的缓存来解除服务器的这种阻止新连接的状态,通过FLUSH HOSTS或mysqladmin flush-hosts命令来清空缓存。这个参数的默认值是100,一般将该参数设置为100000。
interactive_timeout:Mysql关闭交互连接前的等待时间,单位是秒,默认是8小时,建议不要将该参数设置超过24小时,即86400
wait_timeout:Mysql关闭非交互连接前的等待时间,单位是秒,默认是8小时,建议不要将该参数设置超过24小时,即86400
skip_name_resolve:如果这个参数设为OFF,则MySQL服务在检查客户端连接的时候会解析主机名;如果这个参数设为ON,则MySQL服务只会使用IP,在这种情况下,授权表中的Host字段必须是IP地址或localhost。
这个参数默认是关闭的
back_log:MySQL服务器连接请求队列所能处理的最大连接请求数,如果队列放满了,后续的连接才会拒绝。当主要的MySQL线程在很短时间内获取大量连接请求时,这个参数会生效。接下来,MySQL主线程会花费很短的时间去检查连接,然后开启新的线程。这个参数指定了MySQL的TCP/IP监听队列的大小。如果MySQL服务器在短时间内有大量的连接,可以增加这个参数。
文件相关参数sync_binlog:控制二进制日志被同步到磁盘前二进制日志提交组的数量。当这个参数为0的时候,二进制日志不会被同步到磁盘;当这个参数设为0以上的数值时,就会有设置该数值的二进制提交组定期同步日志到磁盘。当这个参数设为1的时候,所有事务在提交前会被同步到二进制日志中,因而即使MySQL服务器发生意外重启,任何二进制日志中没有的事务只会处于准备状态,这会导致MySQL服务器自动恢复以回滚这些事务。这样就会保证二进制日志不会丢失事务,是最安全的选项;同时由于增加了磁盘写,这对性能有一定降低。将这个参数设为1以上的数值会提高数据库的性能,但同时会伴随数据丢失的风险。建议将该参数设为2、4、6、8、16。
expire_logs_days:二进制日志自动删掉的时间间隔。默认值为0,代表不会自动删除二进制日志。想手动删除二进制日志,可以执行 PURGE BINARY LOGS。
max_binlog_size:二进制日志文件的最大容量,当写入的二进制日志超过这个值的时候,会完成当前二进制的写入,向新的二进制日志写入日志。这个参数最小值时4096字节;最大值和默认值时1GB。相同事务中的语句都会写入同一个二进制日志,当一个事务很大时,二进制日志实际的大小会超过max_binlog_size参数设置的值。如果max_relay_log_size参数设为0,则max_relay_log_size参数会使用和max_binlog_size参数同样的大小。建议将此参数设为512M。
local_infile:是否允许客户端使用LOAD DATA INFILE语句。如果这个参数没有开启,客户端不能在LOAD DATA语句中使用LOCAL参数。
open_files_limit:操作系统允许MySQL服务打开的文件数量。这个参数实际的值以系统启动时设定的值、max_connections和table_open_cache为基础,使用下列的规则:
10 + max_connections + (table_open_cache * 2)
max_connections * 5
MySQL启动时指定open_files_limit的值
缓存控制参数binlog_cache_size:在事务中二进制日志使用的缓存大小。如果MySQL服务器支持所有的存储引擎且启用二进制日志,每个客户端都会被分配一个二进制日志缓存。如果数据库中有很多大的事务,增大这个缓存可以获得更好的性能。
Binlog_cache_use和Binlog_cache_disk_use这两个参数对于binlog_cache_size参数的优化很有用。binlog_cache_size参数只设置事务所使用的缓存,非事务SQL语句所使用的缓存由binlog_stmt_cache_size系统参数控制。建议不要将这个参数设为超过64MB,以防止客户端连接多而影响MySQL服务的性能。
max_binlog_cache_size:如果一个事务需要的内存超过这个参数,服务器会报错”Multi-statement transaction required more than ‘max_binlog_cache_size’ bytes”。这个参数最大的推荐值是4GB,这是因为MySQL不能在二进制日志设为超过4GB的情况下正常的工作。建议将该参数设为binlog_cache_size*2。
binlog_stmt_cache_size:这个参数决定二进制日志处理非事务性语句的缓存。如果MySQL服务支持任何事务性的存储引擎且开启了二进制日志,每个客户端连接都会被分配二进制日志事务和语句缓存。如果数据库中经常运行大的事务,增加这个缓存可以获得更好的性能。
table_open_cache:所有线程能打开的表的数量。
thread_cache_size:MySQL服务缓存以重用的线程数。当客户端断开连接的时候,如果线程缓存没有使用满,则客户端的线程被放入缓存中。如果有客户端断开连接后再次连接到MySQL服务且线程在缓存中,则MySQL服务会优先使用缓存中的线程;如果线程缓存没有这些线程,则MySQL服务器会创建新的线程。如果数据库有很多的新连接,可以增加这个参数来提升性能。如果MySQL服务器每秒有上百个连接,可以增大thread_cache_size参数来使MySQL服务器使用缓存的线程。通过检查Connections和Threads_created状态参数,可以判断线程缓存是否足够。这个参数默认的值是由下面的公式来决定的:8 + (max_connections / 100)
建议将此参数设置为300~500。线程缓存的命中率计算公式为(1-thread_created/connections)*100%,可以通过这个公式来优化和调整thread_cache_size参数。
query_cache_size:为查询结果所分配的缓存。默认这个参数是没有开启的。这个参数的值应设为整数的1024倍,如果设为其他值则会被自动调整为接近此数值的1024倍。这个参数最小需要40KB。建议不要将此参数设为大于256MB,以免占用太多的系统内存。
query_cache_min_res_unit:查询缓存所分配的最小块的大小。默认值是4096(4KB)。
query_cache_type:设置查询缓存的类型。当这个参数为0或OFF时,则MySQL服务器不会启用查询缓存;当这个参数为1或ON时,则MySQL服务器会缓存所有查询结果(除了带有SELECT SQL_NO_CACHE的语句);当这个参数为2或DEMAND时,则MySQL服务器只会缓存带有SELECT SQL_CACHE的语句。
sort_buffer_size:每个会话执行排序操作所分配的内存大小。想要增大max_sort_length参数,需要增大sort_buffer_size参数。如果在SHOW GLOBAL STATUS输出结果中看到每秒输出的Sort_merge_passes状态参数很大,可以考虑增大sort_buffer_size这个值来提高ORDER BY 和 GROUP BY的处理速度。建议设置为1~4MB。当个别会话需要执行大的排序操作时,在会话级别增大这个参数。
read_buffer_size:为每个线程对MyISAm表执行顺序读所分配的内存。如果数据库有很多顺序读,可以增加这个参数,默认值是131072字节。这个参数的值需要是4KB的整数倍。这个参数也用在下面场景中:
当执行ORDER BY操作时,缓存索引到临时文件(不是临时表)中;
执行批量插入到分区表中;
缓存嵌套查询的执行结果。
read_rnd_buffer_size:这个参数用在MyISAM表和任何存储引擎表随机读所使用的内存。当从MyISAM表中以键排序读取数据的时候,扫描的行将使用这个缓存以避免磁盘的扫描。将这个值设到一个较大的值可以显著提升ORDER BY的性能。然后,这个参数会应用到所有的客户端连接,所有不应该将这个参数在全局级别设为一个较大的值;在运行大查询的会话中,在会话级别增大这个参数即可。
join_buffer_size:MySQL服务器用来作普通索引扫描、范围索引扫描和不使用索引而执行全表扫描这些操作所用的缓存大小。通常,获取最快连接的方法是增加索引。当不能增加索引的时候,使全连接变快的方法是增大join_buffer_size参数。对于执行全连接的两张表,每张表都被分配一块连接内存。对于没有使用索引的多表复杂连接,需要多块连接内存。通常来说,可以将此参数在全局上设置一个较小的值,而在需要执行大连接的会话中在会话级别进行设置。默认值是256KB。
net_buffer_length:每个客户端线程和连接缓存和结果缓存交互,每个缓存最初都被分配大小为net_buffer_length的容量,并动态增长,直至达到max_allowed_packet参数的大小。当每条SQL语句执行完毕后,结果缓存会缩小到net_buffer_length大小。不建议更改这个参数,除非你的系统有很少的内存,可以调整这个参数。如果语句需要的内存超过了这个参数的大小,则连接缓存会自动增大。net_buffer_length参数最大可以设置到1MB。不能在会话级别设置这个参数。
max_allowed_packet:网络传输时单个数据包的大小。默认值是4MB。包信息缓存的初始值是由net_buffer_length指定的,但是包可能会增长到max_allowed_packet参数设置的值。如果要使用BLOB字段或长字符串,需要增加这个参数的值。这个参数的值需要设置成和最大的BLOB字段一样的大小。max_allowed_packet参数的协议限制是1GB。这个参数应该是1024整数倍。
bulk_insert_buffer_size:MyISAM表使用一种特殊的树状缓存来提高批量插入的速度,如INSERT … SELECT,INSERT … VALUES (…),(…), …,对空表执行执行LOAD DATA INFILE。这个参数每个线程的树状缓存大小。将这个参数设为0会关闭这个参数。这个参数的默认值是8MB。
max_heap_table_size:这个参数设置用户创建的MEMORY表允许增长的最大容量,这个参数用来MEMORY表的MAX_ROWS值。设置这个参数对已有的MEMORY表没有影响,除非表重建或执行ALTER TABLE、TRUNCATE TABLE语句。
这个参数也和tmp_table_size参数一起来现在内部in-memory表的大小。如果内存表使用频繁,可以增大这个参数的值。
tmp_table_size:内部内存临时表的最大内存。这个参数不会应用到用户创建的MEMORY表。如果内存临时表的大小超过了这个参数的值,则MySQL会自动将超出的部分转化为磁盘上的临时表。在MySQL 5.7.5版本,internal_tmp_disk_storage_engine存储引擎将作为磁盘临时表的默认引擎。在MySQL 5.7.5之前的版本,会使用MyISAM存储引擎。如果有很多的GROUP BY查询且系统内存充裕,可以考虑增大这个参数。
innodb_buffer_pool_dump_at_shutdown:指定在MySQL服务关闭时,是否记录InnoDB缓存池中的缓存页,以缩短下次重启时的预热过程。通常和innodb_buffer_pool_load_at_startup参数搭配使用。innodb_buffer_pool_dump_pct参数定义了保留的最近使用缓存页的百分比。
innodb_buffer_pool_dump_now:立刻记录InnoDB缓冲池中的缓存页。通常和innodb_buffer_pool_load_now搭配使用。
innodb_buffer_pool_load_at_startup:指定MySQL服务在启动时,InnoDB缓冲池通过加载之前的缓存页数据来自动预热。通常和innodb_buffer_pool_dump_at_shutdown参数搭配使用。
innodb_buffer_pool_load_now:立刻通过加载数据页来预热InnoDB缓冲池,无需重启数据库服务。可以用来在性能测试时,将缓存改成到一个已知的状态;或在数据库运行报表查询或维护后,将数据库改成到一个正常的状态。
MyISAM参数key_buffer_size:所有线程所共有的MyISAM表索引缓存,这块缓存被索引块使用。增大这个参数可以增加索引的读写性能,在主要使用MyISAM存储引擎的系统中,可设置这个参数为机器总内存的25%。如果将这个参数设置很大,比如设为机器总内存的50%以上,机器会开始page且变得异常缓慢。可以通过SHOW STATUS 语句查看 Key_read_requests,Key_reads,Key_write_requests, and Key_writes这些状态值。正常情况下Key_reads/Key_read_requests 比率应该小于0.01。数据库更新和删除操作频繁的时候,Key_writes/Key_write_requests 比率应该接近1。
key_cache_block_size:key缓存的块大小,默认值是1024字节。
myisam_sort_buffer_size:在REPAIR TABLE、CREATE INDEX 或 ALTER TABLE操作中,MyISAM索引排序使用的缓存大小。
myisam_max_sort_file_size:当重建MyISAM索引的时候,例如执行REPAIR TABLE、ALTER TABLE、或 LOAD DATA INFILE命令,MySQL允许使用的临时文件的最大容量。如果MyISAM索引文件超过了这个值且磁盘还有充裕的空间,增大这个参数有助于提高性能。
myisam_repair_threads:如果这个参数的值大于1,则MyISAM表在执行Repair操作的排序过程中,在创建索引的时候会启用并行,默认值为1。
InnoDB参数innodb_buffer_pool_size:InnDB存储引擎缓存表和索引数据所使用的内存大小。默认值是128MB。在以InnDB存储引擎为主的系统中,可以将这个参数设为机器物理内存的80%。同时需要注意:
设置较大物理内存时是否会引擎页的交换而导致性能下降;
InnoDB存储引擎会为缓存和控制表结构信息使用部分内存,因而实际花费的内存会比设置的值大于10%;
这个参数设置的越大,初始化内存池的时间越长。在MySQL 5.7.5版本,可以以chunk为单位增加或减少内存池的大小。chunk的大小可以通过innodb_buffer_pool_chunk_size参数设定,默认值是128MB。内存池的大小可以等于或是innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances的整数倍。
innodb_buffer_pool_instances:InnoDB缓存池被分成的区域数。对于1GB以上大的InnoDB缓存,将缓存分成多个部分可以提高MySQL服务的并发性,减少不同线程读缓存页的读写竞争。每个缓存池有它单独的空闲列表、刷新列表、LRU列表和其他连接到内存池的数据结构,它们被mutex锁保护。这个参数只有将innodb_buffer_pool_size参数设为1GB或以上时才生效。建议将每个分成的内存区域设为1GB大小。
innodb_max_dirty_pages_pct:当Innodb缓存池中脏页所占的百分比达到这个参数的值时,InnoDB会从缓存中向磁盘写入数据。默认值是75。
innodb_thread_concurrency:InnoDB存储引擎可以并发使用的最大线程数。当InnoDB使用的线程超过这参数的值时,后面的线程会进入等待状态,以先进先出的算法来处理。等待锁的线程不计入这个参数的值。这个参数的范围是0~1000。默认值是0。当这个参数为0时,代表InnoDB线程的并发数没有限制,这样会导致MySQL创建它所需要的尽可能多的线程。设置这个参数可以参考下面规则:
如果用户线程的并发数小于64,可以将这个参数设为0;
如果系统并发很严重,可以先将这个参数设为128,然后再逐渐将这个参数减小到96, 80, 64或其他数值,直到找到性能较好的一个数值。
innodb_flush_method:指定刷新数据到InnoDB数据文件和日志文件的方法,刷新方法会对I/O有影响。如果这个参数的值为空,在类Unix系统上,这个参数的默认值为fsync;在Windows系统上,这个参数的默认值为async_unbuffered。在类Unix系统上,这个参数可设置的值如下:
fsync:InnoDB使用fsync()系统函数来刷新数据和日志文件,fsync是默认参数。
O_DSYNC:InnoDB使用O_SYNC函数来打开和刷新日志文件,使用fsync()函数刷新数据文件
littlesync:这个选项用在内部性能的测试,目前MySQL尚不支持,使用这个参数又一定的风险
nosync:这个选项用在内部性能的测试,目前MySQL尚不支持,使用这个参数又一定的风险
O_DIRECT:InnoDB使用O_DIRECT(或者directio()在Solaris)函数打开数据文件,使用fsync()刷新数据文件和日志文件
O_DIRECT_NO_FSYNC:在刷新I/O时,InnoDB使用O_DIRECT方式。
在有RAID卡和写缓存的系统中,O_DIRECT有助于避免InnoDB缓存池和操作系统缓存之间的双重缓存。在InnoDB数据和日志文件放在SAN存储上面的系统,默认值或O_DSYNC方法会对以读为主的数据库起到加速作用。
innodb_data_home_dir:InnoDB系统表空间所使用的数据文件的物理路径,默认路径是MySQL数据文件路径。如果这个参数的值为空,可以在innodb_data_file_path参数里使用绝对路径
innodb_data_file_path:InnoDB数据文件的路径和大小。
innodb_file_per_table:当这个参数启用的时候,InnoDB会将新建表的数据和索引单独存放在.ibd格式的文件中,而不是存放在系统表空间中。当这张表被删除或TRUNCATE时,InnoDB表所占用的存储会被释放。这个设定会开启InnoDB的一些其他特性,比如表的压缩。当这个参数关闭的时候,InnoDB会将表和索引的数据存放到系统表空间的ibdata文件中,这会有一个问题,因为系统表空间不会缩小,这样设置会导致空间无法回放。
innodb_undo_directory:InnoDB undo日志所在表空间的物理路径。和innodb_undo_logs、innodb_undo_tablespaces参数配合,来设置undo日志的路径,默认路径是数据文件路径。
innodb_undo_logs:指定InnoDB使用的undo日志的个数。在MySQL 5.7.2版本,32个undo日志被临时表预留使用,并且这些日志存放在临时表表空间(ibtmp1)中。如果undo日志只存放在系统表空间中,想要额外分配供数据修改事务用的undo日志,innodb_undo_logs参数必须设置为32以上的整数。如果你配置了单独的undo表空间,要将innodb_undo_logs参数设为33以上来分配额外供数据修改事务使用的undo日志。每个undo日志最多可以支持1024个事务。如果这个参数没有设置,则它会设为默认值128。
innodb_undo_tablespaces:undo日志的表空间文件数量。默认,所有的undo日志都是系统表空间的一部分。因为在运行大的事务时,undo日志会增大,将undo日志设置在多个表空间中可以减少一个表空间的大小。undo表空间文件创建在innodb_undo_directory参数指定的路径下,以undoN格式命名,N是以0开头的一系列整数。undo表空间的默认大小为10M。需要在初始化InnoDB前设置innodb_undo_tablespaces这个参数。在MySQL 5.7.2版本,在128个undo日志中,有32个undo日志是为临时表所预留的,有95个undo日志供undo表空间使用。
innodb_log_files_in_group:InnoDB日志组包含的日志个数。InnoDB以循环的方式写入日志。这个参数的默认值和推荐值均是2。日志的路径由innodb_log_group_home_dir参数设定。
innodb_log_group_home_dir:InnoDB重做日志文件的物理路径,重做日志的数量由innodb_log_files_in_group参数指定。如果不指定任何InnoDB日志参数,MySQL默认会在MySQL数据文件路径下面创建两个名为ib_logfile0、ib_logfile1的两个重做日志文件,它们的大小由innodb_log_file_size参数设定。
innodb_log_file_size:日志组中每个日志文件的字节大小。所有日志文件的大小(innodb_log_file_size * innodb_log_files_in_group)不能超过512GB。
innodb_log_buffer_size:InnoDB写入磁盘日志文件所使用的缓存字节大小。如果innodb_page_size参数为32K,则默认值是8MB;如果innodb_page_size参数为64K,则默认值是16MB。如果日志的缓存设置较大,则MySQL在处理大事务时,在提交事务前无需向磁盘写入日志文件。建议设置此参数为4~8MB。
innodb_flush_log_at_trx_commit:当提交相关的I/O操作被批量重新排列时,这个参数控制提交操作的ACID一致性和高性能之间的平衡。可以改变这个参数的默认值来提升数据库的性能,但是在数据库宕机的时候会丢失少量的事务。这个参数的默认值为1,代表数据库遵照完整的ACID模型,每当事务提交时,InnoDB日志缓存中的内容均会被刷新到日志文件,并写入到磁盘。当这个参数为0时,InnDB日志缓存大概每秒刷新一次日志文件到磁盘。当事务提交时,日志缓存不会立刻写入日志文件,这样的机制不会100%保证每秒都向日志文件刷新日志,当mysqld进程宕掉的时候可能会丢失持续时间为1秒左右的事务数据。当这个参数为2时,当事务提交后,InnoDB日志缓存中的内容会写入到日志文件且日志文件,日志文件以大概每秒一次的频率刷新到磁盘。在MySQL 5.6.6版本,InnoDB日志刷新频率由innodb_flush_log_at_timeout参数决定。通常将个参数设为1。
innodb_flush_log_at_timeout:写入或刷新日志的时间间隔。这个参数是在MySQL 5.6.6版本引入的。在MySQL 5.6.6版本之前,刷新的频率是每秒刷新一次。innodb_flush_log_at_timeout参数的默认值也是1秒刷新一次。
innodb_lock_wait_timeout:InnDB事务等待行锁的时间长度。默认值是50秒。当一个事务锁定了一行,这时另外一个事务想访问并修改这一行,当等待时间达到innodb_lock_wait_timeout参数设置的值时,MySQL会报错”ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction”,同时会回滚语句(不是回滚整个事务)。如果想回滚整个事务,需要使用–innodb_rollback_on_timeout参数启动MySQL。在高交互性的应用系统或OLTP系统上,可以减小这个参数来快速显示用户的反馈或把更新放入队列稍后处理。在数据仓库中,为了更好的处理运行时间长的操作,可以增大这个参数。这个参数只应用在InnoDB行锁上,这个参数对表级锁无效。这个参数不适用于死锁,因为发生死锁时,InnoDB会立刻检测到死锁并将发生死锁的一个事务回退。
innodb_fast_shutdown:InnoDB关库模式。如果这个参数为0,InnoDB会做一个缓慢关机,在关机前会做完整的刷新操作,这个级别的关库操作会持续数分钟,当缓存中的数据量很大时,甚至会持续几个小时;如果数据库要执行版本升级或降级,需要执行这个级别的关库操作,以保证所有的数据变更都写入到数据文件。如果这个参数的值是1(默认值),为了节省关库时间,InnoDB会跳过新操作,而是在下一次开机的时候通过crash recovery方式执行刷新操作。如果这个参数的值是2,InnoDB会刷新日志并以冷方式关库,就像MySQL宕机一样,没有提交的事务会丢失,在下一次开启数据库时,crash recovery所需要的时间更长;在紧急或排错情形下,需要立刻关闭数据库时,会使用这种方式停库。
MySQL事务隔离级别
查看事物隔离级别
SELECT @@tx_isolation;
设置mysql的隔离级别:
set session transaction isolation level 设置事务隔离级别
设置read uncommitted级别:
set session transaction isolation level read uncommitted;
设置read committed级别:
set session transaction isolation level read committed;
设置repeatable read级别:
set session transaction isolation level repeatable read;
设置serializable级别:
set session transaction isolation level serializable;
事务隔离级别 脏读 不可重复读 幻读
读未提交(READ UNCOMMITTED) √ √ √
读已提交(READ COMMITTED) × √ √
可重复读(REPEATABLE READ) × × √
串行化(SERIALIZABLE) × × ×
锁
执行计划
大家好,我是只谈技术不剪发的 Tony 老师。今天给大家深入分析一下 MySQL 中的执行计划。
执行计划(execution plan,也叫查询计划或者解释计划)是 MySQL 服务器执行 SQL 语句的具体步骤。例如,通过索引还是全表扫描访问表中的数据,连接查询的实现方式和连接的顺序,分组和排序操作的实现方式等。
负责生成执行计划的组件就是优化器,优化器利用表结构、字段、索引、查询条件、数据库的统计信息和配置参数决定 SQL 语句的最佳执行方式。如果想要解决慢查询的性能问题,首先应该查看它的执行计划。
获取执行计划
MySQL 提供了 EXPLAIN 语句,用于获取 SQL 语句的执行计划。该语句的基本形式如下:
| {EXPLAIN | DESCRIBE | DESC} |
{
SELECT statement
| TABLE statement |
| DELETE statement |
| INSERT statement |
| REPLACE statement |
| UPDATE statement |
}
EXPLAIN和DESCRIBE是同义词,可以通用。实际应用中,DESCRIBE主要用于查看表的结构,EXPLAIN主要用于获取执行计划。MySQL 可以获取 SELECT、INSERT、DELETE、UPDATE、REPLACE 等语句的执行计划。从 MySQL 8.0.19 开始,支持 TABLE 语句的执行计划。
举例来说:
explain
select *
from employee;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|——–|———-|—-|————-|—|——-|—|—-|——–|—–|
| 1 | SIMPLE | employee | ALL | 25 | 100.0 |
MySQL 中的执行计划包含了 12 列信息,这些字段的含义我们在下文中进行解读。
除了使用 EXPLAIN 语句之外,很多管理和开发工具都提供了查看图形化执行计划的功能,例如 MySQL Workbench 中显示以上查询的执行计划如下:
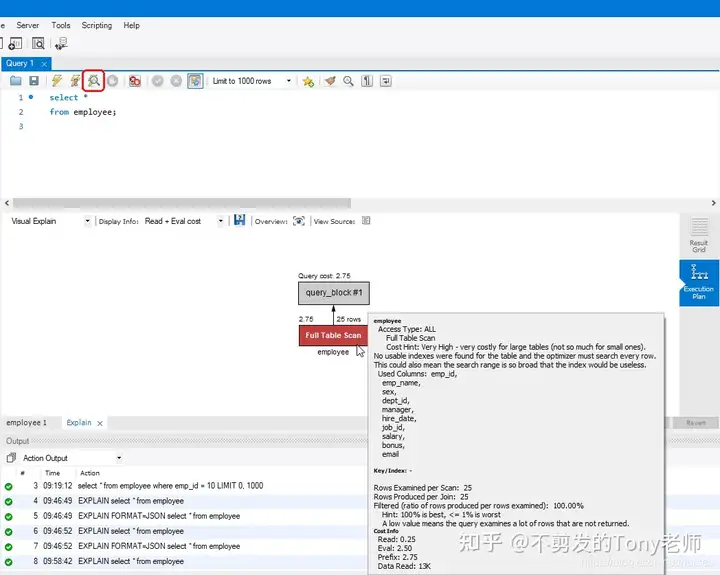
当然,这种方式最终也是执行了 EXPLAIN 语句。
解读执行计划
理解执行计划中每个字段的含义可以帮助我们知悉 MySQL 内部的操作过程,找到性能问题的所在并有针对性地进行优化。在执行计划的输出信息中,最重要的字段就是 type。
type 字段
type 被称为连接类型(join type)或者访问类型(access type),它显示了 MySQL 如何访问表中的数据。
访问类型会直接影响到查询语句的性能,性能从好到差依次为:
-
system,表中只有一行数据(系统表),这是 const 类型的特殊情况;
-
const,最多返回一条匹配的数据,在查询的最开始读取;
-
eq_ref,对于前面的每一行,从该表中读取一行数据;
-
ref,对于前面的每一行,从该表中读取匹配索引值的所有数据行;
-
fulltext,通过 FULLTEXT 索引查找数据;
-
ref_or_null,与 ref 类似,额外加上 NULL 值查找;
-
index_merge,使用索引合并优化技术,此时 key 列显示使用的所有索引;
-
unique_subquery,替代以下情况时的 eq_ref:value IN (SELECT primary_key FROM single_table WHERE some_expr);
-
index_subquery,与 unique_subquery 类似,用于子查询中的非唯一索引:value IN (SELECT key_column FROM single_table WHERE some_expr);
-
range,使用索引查找范围值;
-
index,与 ALL 类型相同,只不过扫描的是索引;
-
ALL,全表扫描,通常表示存在性能问题。
const 和 eq_ref 都意味着着通过 PRIMARY KEY 或者 UNIQUE 索引查找唯一值;它们的区别在于 const 对于整个查询只返回一条数据,eq_ref 对于前面的结果集中的每条记录只返回一条数据。例如以下查询通过主键(key = PRIMARY)进行等值查找:
explain
select *
from employee
where emp_id = 1;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|——–|———-|—–|————-|——-|——-|—–|—-|——–|—–|
| 1 | SIMPLE | employee | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.0 |
const 只返回一条数据,是一种非常快速的访问方式,所以相当于一个常量(constant)。
以下语句通过主键等值连接两个表:
explain
select *
from employee e
join department d
on (e.dept_id = d.dept_id )
where e.emp_id in(1, 2);
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|——|——————–|——-|——-|————–|—-|——–|———–|
| 1 | SIMPLE | e | range | PRIMARY,idx_emp_dept | PRIMARY | 4 | 2 | 100.0 | Using where |
| 1 | SIMPLE | d | eq_ref | PRIMARY | PRIMARY | 4 | hrdb.e.dept_id | 1 | 100.0 |
对于 employee 中返回的每一行(table = e),department 表通过主键(key = PRIMARY)返回且仅返回一条数据(type = eq_ref)。Extra 字段中的 Using where 表示将经过条件过滤后的数据传递给下个表或者客户端。
ref、ref_or_null 以及 range 表示通过范围查找所有匹配的索引项,然后根据需要再访问表中的数据。通常意味着使用了非唯一索引或者唯一索引的前面部分字段进行数据访问,例如:
explain
select *
from employee e
where e.dept_id = 1;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—-|————-|————|——-|—–|—-|——–|—–|
| 1 | SIMPLE | e | ref | idx_emp_dept | idx_emp_dept | 4 | const | 3 | 100.0 |
explain
select *
from employee e
join department d
on (e.dept_id = d.dept_id )
where d.dept_id = 1;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—–|————-|————|——-|—–|—-|——–|—–|
| 1 | SIMPLE | d | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.0 |
| 1 | SIMPLE | e | ref | idx_emp_dept | idx_emp_dept | 4 | const | 3 | 100.0 |
以上两个查询语句都是通过索引 idx_emp_dept 返回 employee 表中的数据。
ref_or_null 和 ref 的区别在于查询中包含了 IS NULL 条件。例如:
alter table employee modify column dept_id int null;
explain
select *
from employee e
where e.dept_id = 1 or dept_id is null;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|———–|————-|————|——-|—–|—-|——–|———————|
| 1 | SIMPLE | e | ref_or_null | idx_emp_dept | idx_emp_dept | 5 | const | 4 | 100.0 | Using index condition |
其中,Extra 字段显示为 Using index condition,意味着通过索引访问表中的数据之前,直接通过 WHERE 语句中出现的索引字段条件过滤数据。这是 MySQL 5.6 之后引入了一种优化,叫做索引条件下推(Index Condition Pushdown)。
为了显示 ref_or_null,我们需要将字段 dept_id 设置为可空,测试之后记得重新修改为 NOT NULL:
alter table employee modify column dept_id int not null;
range 通常出现在使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE 或者 IN() 运算符和索引字段进行比较时,例如:
explain
select *
from employee e
where e.email like ‘zhang%’;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—–|————-|————|——-|—|—-|——–|———————|
| 1 | SIMPLE | e | range | uk_emp_email | uk_emp_email | 302 | 2 | 100.0 | Using index condition |
index_merge 表示索引合并,当查询通过多个索引 range 访问方式返回数据时,MySQL 可以先对这些索引扫描结果合并成一个,然后通过这个索引获取表中的数据。例如:
explain
select *
from employee e
where dept_id = 1 or job_id = 1;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|———–|——————-|——————-|——-|—|—-|——–|———————————————|
| 1 | SIMPLE | e | index_merge | PRIMARY,idx_emp_job | PRIMARY,idx_emp_job | 4,4 | 2 | 100.0 | Using union(PRIMARY,idx_emp_job); Using where |
其中,字段 key 显示了使用的索引列表;Extra 中的 Using union(PRIMARY,idx_emp_job) 是索引合并的算法,这里采用了并集算法(查询条件使用了 or 运算符)。
unique_subquery 本质上也是 eq_ref 索引查找,用于优化以下形式的子查询:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery 本质上也是 ref 范围索引查找,用于优化以下形式的子查询:
value IN (SELECT key_column FROM single_table WHERE some_expr)
index表示扫描整个索引,以下两种情况会使用这种访问方式:
- 查询可以直接通过索引返回所需的字段信息,也就是 index-only scan。此时 Extra 字段显示为 Using index。例如:
explain
select dept_id
from employee;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| – | ———— | ——– | ———- | —– | ————– | ————– | ——– | — | —- | ——– | ———– |
| 1 | SIMPLE | employee | index | idx_emp_dept | 4 | 25 | 100.0 | Using index |
查询所需的 dept_id 字段通过扫描索引 idx_emp_dept 即可获得,所以采用了 index 访问类型。
- 通过扫描索引执行全表扫描,从而按照索引的顺序返回数据。此时 Extra 字段不会出现 Using index。
explain
select *
from employee force index (idx_emp_name)
order by emp_name;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| – | ———— | ——– | ———- | —– | ————– | ————– | ——– | — | —- | ——– | —– |
| 1 | SIMPLE | employee | index | idx_emp_name | 202 | 25 | 100.0 |
为了演示 index 访问方式,我们使用了强制索引(force index);否则,MySQL 选择使用全表扫描(ALL)。
ALL表示全表扫描,这是一种 I/O 密集型的操作,通常意味着存在性能问题。例如:
explain
select *
from employee;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|——–|———-|—-|————-|—|——-|—|—-|——–|—–|
| 1 | SIMPLE | employee | ALL | 25 | 100.0 |
因为 employee 表本身不大,而且我们查询了所有的数据,这种情况下全表扫描反而是一个很好的访问方法。但是,以下查询显然需要进行优化:
explain
select *
from employee
where salary = 10000;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|——–|———-|—-|————-|—|——-|—|—-|——–|———–|
| 1 | SIMPLE | employee | ALL | 25 | 10.0 | Using where |
显然,针对这种查询语句,我们可以通过为 salary 字段创建一个索引进行优化。
Extra 字段
执行计划输出中的 Extra 字段通常会显示更多的信息,可以帮助我们发现性能问题的所在。上文中我们已经介绍了一些 Extra 字段的信息,需要重点关注的输出内容包括:
-
Using where,表示将经过 WHERE 条件过滤后的数据传递给下个数据表或者返回客户端。如果访问类型为 ALL 或者 index,而 Extra 字段不是 Using where,意味着查询语句可能存在问题(除非就是想要获取全部数据)。
-
Using index condition,表示通过索引访问表之前,基于查询条件中的索引字段进行一次过滤,只返回必要的索引项。这也就是索引条件下推优化。
-
Using index,表示直接通过索引即可返回所需的字段信息(index-only scan),不需要访问表。对于 InnoDB,如果通过主键获取数据,不会显示 Using index,但是仍然是 index-only scan。此时,访问类型为 index,key 字段显示为 PRIMARY。
-
Using filesort,意味着需要执行额外的排序操作,通常需要占用大量的内存或者磁盘。例如:
explain
select *
from employee
where dept_id =3
order by hire_date;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| – | ———— | ——– | ———- | —- | ————– | ————– | ——– | —– | —- | ——– | ————– |
| 1 | SIMPLE | employee | ref | idx_emp_dept | idx_emp_dept | 4 | const | 2 | 100.0 | Using filesort |
索引通常可以用于优化排序操作,我们可以为索引 idx_emp_dept 增加一个 hire_date 字段来消除示例中的排序。
- Using temporary,意味着需要创建临时表保存中间结果。例如:
explain
select dept_id,job_id, sum(salary)
from employee
group by dept_id, job_id;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
| – | ———— | ——– | ———- | —- | ————– | — | ——– | — | —- | ——– | ————— |
| 1 | SIMPLE | employee | ALL | 25 | 100.0 | Using temporary |
示例中的分组操作需要使用临时表,同样可以通过增加索引进行优化。
访问谓词与过滤谓词
在 SQL 中,WHERE 条件也被称为谓词(predicate)。MySQL 数据库中的谓词存在以下三种使用方式:
-
访问谓词(access predicate),在执行计划的输出中对应于 key_len 和 ref 字段。访问谓词代表了索引叶子节点遍历的开始和结束条件。
-
索引过滤谓词(index filter predicate),在执行计划中对应于 Extra 字段的 Using index condition。索引过滤谓词在遍历索引叶子节点时用于判断是否返回该索引项,但是不会用于判断遍历的开始和结束条件,也就不会缩小索引扫描的范围。
-
表级过滤谓词(table level filter predicate),在执行计划中对应于 Extra 字段的 Using where。谓词中的非索引字段条件在表级别进行判断,意味着数据库需要访问表中的数据然后再应用该条件。
一般来说,对于相同的查询语句,访问谓词的性能好于索引过滤谓词,索引过滤谓词的性能好于表级过滤谓词。
MySQL 执行计划中不会显示每个条件对应的谓词类型,而只是笼统地显示使用了哪种谓词类型。我们创建一个示例表:
create table test (
id int not null auto_increment primary key,
col1 int,
col2 int,
col3 int);
insert into test(col1, col2, col3)
values (1,1,1), (2,4,6), (3,6,9);
create index test_idx on test (col1, col2);
analyze table test;
以下语句使用 col1 和 col2 作为查询条件:
explain
select *
from test
where col1=1 and col2=1;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—-|————-|——–|——-|———–|—-|——–|—–|
| 1 | SIMPLE | test | ref | test_idx | test_idx | 10 | const,const | 1 | 100.0 |
其中,Extra 字段为空;key = test_idx 表示使用索引进行查找,key_len = 10 就是 col1 和 col2 两个字段的长度(可空字段长度加 1);ref = const,const 表示使用了索引中的两个字段和常量进行比较,从而判断是否返回数据行。因此,该语句中的 WHERE 条件是一个访问谓词。
接下来我们仍然使用 col1 和 col2 作为查询条件,但是修改一下返回的字段:
explain
select id, col1, col2
from test
where col1=1 and col2=1;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—-|————-|——–|——-|———–|—-|——–|———–|
| 1 | SIMPLE | test | ref | test_idx | test_idx | 10 | const,const | 1 | 100.0 | Using index |
其中,Extra 字段中的 Using index 不是 Using index condition,它是一个 index-only scan,因为所有的查询结果都可以通过索引直接返回(包括 id);其他字段的信息和上面的示例相同。因此,该语句中的 WHERE 条件也是一个访问谓词。
然后使用 col1 进行范围查询:
explain
select *
from test
where col1 between 1 and 2;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—–|————-|——–|——-|—|—-|——–|———————|
| 1 | SIMPLE | test | range | test_idx | test_idx | 5 | 2 | 100.0 | Using index condition |
其中,Extra 字段中显示为 Using index condition;key = test_idx 表示使用索引进行范围查找,key_len = 5 就是 col1 字段的长度(可空字段长度加 1);ref 为空表示没有访问谓词。因此,该语句中的 WHERE 条件是一个索引过滤谓词,查询需要遍历整个索引并且通过索引判断是否访问表中的数据。
最后使用 col1 和 col3 作为查询条件:
explain
select *
from test
where col1=1 and col3=1;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—-|————-|——–|——-|—–|—-|——–|———–|
| 1 | SIMPLE | test | ref | test_idx | test_idx | 5 | const | 1 | 33.33 | Using where |
其中,Extra 字段中显示为 Using where,表示访问表中的数据然后再应用查询条件 col3=1;key = test_idx 表示使用索引进行查找,key_len = 5 就是 col1 字段的长度(可空字段长度加 1);ref = const 表示常量等值比较;filtered = 33.33 意味着经过查询条件比较之后只保留三分之一的数据。因此,该语句中的 WHERE 条件是一个表级过滤谓词,意味着数据库需要访问表中的数据然后再应用该条件。
完整字段信息
下表列出了 MySQL 执行计划中各个字段的作用:
| 列名 | 作用 |
| :————- | :———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— |
| id | 语句中 SELECT 的序号。如果是 UNION 操作的结果,显示为 NULL;此时 table 列显示为 。 |
| select_type | SELECT 的类型,包括: - SIMPLE,不涉及 UNION 或者子查询的简单查询; - PRIMARY,最外层 SELECT; - UNION,UNION 中第二个或之后的 SELECT; - DEPENDENT UNION,UNION 中第二个或之后的 SELECT,该 SELECT 依赖于外部查询; - UNION RESULT,UNION 操作的结果; - SUBQUERY,子查询中的第一个 SELECT; - DEPENDENT SUBQUERY,子查询中的第一个 SELECT,该 SELECT 依赖于外部查询; - DERIVED,派生表,即 FROM 中的子查询; - DEPENDENT DERIVED,依赖于其他表的派生表; - MATERIALIZED,物化子查询; - UNCACHEABLE SUBQUERY,无法缓存结果的子查询,对于外部表中的每一行都需要重新查询; - UNION 中第二个或之后的 SELECT,该 UNION属于 UNCACHEABLE SUBQUERY。 |
| table | 数据行的来源表,也有可能是以下值之一: - ,id 为 M 和 N 的 SELECT 并集运算的结果; - ,id 为 N 的派生表的结果; - ,id 为 N 的物化子查询的结果。 |
| partitions | 对于分区表而言,表示数据行所在的分区;普通表显示为 NULL。 |
| type | 连接类型或者访问类型,性能从好到差依次为: - system,表中只有一行数据,这是 const 类型的特殊情况; - const,最多返回一条匹配的数据,在查询的最开始读取; - eq_ref,对于前面的每一行,从该表中读取一行数据; - ref,对于前面的每一行,从该表中读取匹配索引值的所有数据行; - fulltext,通过 FULLTEXT 索引查找数据; - ref_or_null,与 ref 类似,额外加上 NULL 值查找; - index_merge,使用索引合并优化技术,此时 key 列显示使用的所有索引; - unique_subquery,替代以下情况时的 eq_ref:value IN (SELECT primary_key FROM single_table WHERE some_expr); - index_subquery,与 unique_subquery 类似,用于子查询中的非唯一索引:value IN (SELECT key_column FROM single_table WHERE some_expr); - range,使用索引查找范围值; - index,与 ALL 类型相同,只不过扫描的是索引; - ALL,全表扫描,通常表示存在性能问题。 |
| possible_keys | 可能用到的索引,实际上不一定使用。 |
| key | 实际使用的索引。 |
| key_len | 实际使用的索引的长度。 |
| ref | 用于和 key 中的索引进行比较的字段或者常量,从而判断是否返回数据行。 |
| rows | 执行查询需要检查的行数,对于 InnoDB 是一个估计值。 |
| Extra | 包含了额外的信息。例如 Using temporary 表示使用了临时表,Using filesort 表示需要额外的排序操作等。 |
格式化参数
MySQL EXPLAIN 语句支持使用 FORMAT 选项指定不同的输出格式:
| {EXPLAIN | DESCRIBE | DESC} |
| FORMAT = {TRADITIONAL | JSON | TREE} |
explainable_stmt
默认的格式为 TRADITIONAL,以表格的形式显示输出信息;JSON 选项表示以 JSON 格式显示信息;MySQL 8.0.16 之后支持 TREE 选项,以树形结构输出了比默认格式更加详细的信息,这也是唯一能够显示 hash join 的格式。
例如,以下语句输出了 JSON 格式的执行计划:
explain
format=json
select *
from employee
where emp_id = 1;
{
“query_block”: {
“select_id”: 1,
“cost_info”: {
“query_cost”: “1.00”
},
“table”: {
“table_name”: “employee”,
“access_type”: “const”,
“possible_keys”: [
“PRIMARY”
],
“key”: “PRIMARY”,
“used_key_parts”: [
“emp_id”
],
“key_length”: “4”,
“ref”: [
“const”
],
“rows_examined_per_scan”: 1,
“rows_produced_per_join”: 1,
“filtered”: “100.00”,
“cost_info”: {
“read_cost”: “0.00”,
“eval_cost”: “0.10”,
“prefix_cost”: “0.00”,
“data_read_per_join”: “568”
},
“used_columns”: [
“emp_id”,
“emp_name”,
“sex”,
“dept_id”,
“manager”,
“hire_date”,
“job_id”,
“salary”,
“bonus”,
“email”
]
}
}
}
其中,大部分的节点信息和表格形式的字段能够对应;但是也返回了一些额外的信息,尤其是各种操作的成本信息 cost_info,可以帮助我们了解不同执行计划之间的成本差异。
以下语句返回了树状结构的执行计划:
explain
format=tree
select *
from employee e1
join employee e2
on e1.salary = e2.salary;
-> Inner hash join (e2.salary = e1.salary) (cost=65.51 rows=63)
-> Table scan on e2 (cost=0.02 rows=25)
-> Hash
-> Table scan on e1 (cost=2.75 rows=25)
从结果可以看出,该执行计划使用了 Inner hash join 实现两个表的连接查询。
执行计划中的select_type:查询的类型。
SIMPLE:简单 SELECT,不需要使用 UNION 操作或子查询。 PRIMARY:如果查询包含子查询,最外层的 SELECT 被标记为 PRIMARY。 UNION:UNION 操作中第二个或后面的 SELECT 语句。 SUBQUERY:子查询中的第一个 SELECT。 DERIVED:派生表的 SELECT 子查询。
执行计划中的分区表信息
如果 SELECT 语句使用了分区表,可以通过 EXPLAIN 命令查看涉及的具体分区。执行计划输出的 partitions 字段显示了数据行所在的表分区。首先创建一个分区表:
create table trb1 (id int primary key, name varchar(50), purchased date)
partition by range(id)
(
partition p0 values less than (3),
partition p1 values less than (7),
partition p2 values less than (9),
partition p3 values less than (11)
);
insert into trb1 values
(1, ‘desk organiser’, ‘2003-10-15’),
(2, ‘CD player’, ‘1993-11-05’),
(3, ‘TV set’, ‘1996-03-10’),
(4, ‘bookcase’, ‘1982-01-10’),
(5, ‘exercise bike’, ‘2004-05-09’),
(6, ‘sofa’, ‘1987-06-05’),
(7, ‘popcorn maker’, ‘2001-11-22’),
(8, ‘aquarium’, ‘1992-08-04’),
(9, ‘study desk’, ‘1984-09-16’),
(10, ‘lava lamp’, ‘1998-12-25’);
然后查看使用 id 进行范围查询时的执行计划:
explain
select * from trb1
where id < 5;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—–|————-|——-|——-|—|—-|——–|———–|
| 1 | SIMPLE | trb1 | p0,p1 | range | PRIMARY | PRIMARY | 4 | 4 | 100.0 | Using where |
结果显示查询访问了分区 p0 和 p1。
获取额外的执行计划信息
除了直接输出的执行计划之外,EXPLAIN 命令还会产生一些额外信息,可以使用SHOW WARNINGS命令进行查看。例如:
explain
select *
from department d
where exists (select 1 from employee e where e.dept_id = d.dept_id );
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|—–|———-|—-|————-|————|——-|————–|—-|——–|————————–|
| 1 | SIMPLE | d | ALL | PRIMARY | 6 | 100.0 |
| 1 | SIMPLE | e | ref | idx_emp_dept | idx_emp_dept | 4 | hrdb.d.dept_id | 5 | 100.0 | Using index; FirstMatch(d) |
show warnings\G
-
- row *
Level: Note
Code: 1276
Message: Field or reference ‘hrdb.d.dept_id’ of SELECT #2 was resolved in SELECT #1
-
- row *
Level: Note
Code: 1003
Message: /* select#1 */ select hrdb.d.dept_id AS dept_id,hrdb.d.dept_name AS dept_name from hrdb.department d semi join (hrdb.employee e) where (hrdb.e.dept_id = hrdb.d.dept_id)
2 rows in set (0.00 sec)
SHOW WARNINGS 命令输出中的 Message 显示了优化器如何限定查询语句中的表名和列名、应用了重写和优化规则后的查询语句以及优化过程的其他信息。
目前只有 SELECT 语句相关的额外信息可以通过 SHOW WARNINGS 语句进行查看,其他语句(DELETE、INSERT、REPLACE 和UPDATE)显示的信息为空。
获取指定连接的执行计划
EXPLAIN 语句也可以用于获取指定连接中正在执行的 SQL 语句的执行计划,语法如下:
| EXPLAIN [FORMAT = {TRADITIONAL | JSON | TREE}] FOR CONNECTION connection_id; |
其中,connection_id 是连接标识符,可以通过字典表 INFORMATION_SCHEMA PROCESSLIST 或者 SHOW PROCESSLIST 命令获取。如果某个会话中存在长时间运行的慢查询语句,在另一个会话中执行该命令可以获得相关的诊断信息。
首先获取当前连接的会话标识符:
mysql> SELECT CONNECTION_ID();
+—————–+
| CONNECTION_ID() |
+—————–+
| 30 |
+—————–+
1 row in set (0.00 sec)
如果此时在当前会话中获取执行计划,将会返回错误信息:
mysql> EXPLAIN FOR CONNECTION 30;
ERROR 3012 (HY000): EXPLAIN FOR CONNECTION command is supported only for SELECT/UPDATE/INSERT/DELETE/REPLACE
因为只有 SELECT、UPDATE、INSERT、DELETE、REPLACE 语句支持执行计划,当前正在执行的是 EXPLAIN 语句。
在当前会话中执行一个大表查询:
mysql> select * from large_table;
然后在另一个会话中执行 EXPLAIN 命令:
explain for connection 30;
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
–|———–|———–|———-|—-|————-|—|——-|—|——|——–|—–|
| 1 | SIMPLE | large_table | ALL | 244296 | 100.0 |
如果指定会话没有正在运行的语句,EXPLAIN 命令将会返回空结果。
获取实际运行的执行计划
MySQL 8.0.18 增加了一个新的命令:EXPLAIN ANALYZE。该语句用于运行一个语句并且产生 EXPLAIN 结果,包括执行时间和迭代器(iterator)信息,可以获取优化器的预期执行计划和实际执行计划之间的差异。
| {EXPLAIN | DESCRIBE | DESC} ANALYZE select_statement |
例如,以下 EXPLAIN 语句返回了查询计划和成本估算:
explain
format=tree
select *
from employee e
join department d
on (e.dept_id = d.dept_id )
where e.emp_id in(1, 2);
-> Nested loop inner join (cost=1.61 rows=2)
-> Filter: (e.emp_id in (1,2)) (cost=0.91 rows=2)
-> Index range scan on e using PRIMARY (cost=0.91 rows=2)
-> Single-row index lookup on d using PRIMARY (dept_id=e.dept_id) (cost=0.30 rows=1)
那么,实际上的执行计划和成本消耗情况呢?我们可以使用 EXPLAIN ANALYZE 语句查看:
explain analyze
select *
from employee e
join department d
on (e.dept_id = d.dept_id )
where e.emp_id in(1, 2);
-> Nested loop inner join (cost=1.61 rows=2) (actual time=0.238..0.258 rows=2 loops=1)
-> Filter: (e.emp_id in (1,2)) (cost=0.91 rows=2) (actual time=0.218..0.233 rows=2 loops=1)
-> Index range scan on e using PRIMARY (cost=0.91 rows=2) (actual time=0.214..0.228 rows=2 loops=1)
-> Single-row index lookup on d using PRIMARY (dept_id=e.dept_id) (cost=0.30 rows=1) (actual time=0.009..0.009 rows=1 loops=2)
对于每个迭代器,EXPLAIN ANALYZE 输出了以下信息:
-
估计执行成本,某些迭代器不计入成本模型;
-
估计返回行数;
-
返回第一行的实际时间(ms);
-
返回所有行的实际时间(ms),如果存在多次循环,显示平均时间;
-
实际返回行数;
-
循环次数。
在输出结果中的每个节点包含了下面所有节点的汇总信息,所以最终的估计信息和实际信息如下:
-> Nested loop inner join (cost=1.61 rows=2) (actual time=0.238..0.258 rows=2 loops=1)
查询通过嵌套循环内连接实现;估计成本为 1.61,估计返回 2 行数据;实际返回第一行数据的时间为 0.238 ms,实际返回所有数据的平均时间为 0.258 ms,实际返回了 2 行数据,嵌套循环操作执行了 1 次。
循环的实现过程是首先通过主键扫描 employee 表并且应用过滤迭代器:
-> Filter: (e.emp_id in (1,2)) (cost=0.91 rows=2) (actual time=0.218..0.233 rows=2 loops=1)
-> Index range scan on e using PRIMARY (cost=0.91 rows=2) (actual time=0.214..0.228 rows=2 loops=1)
其中,应用过滤迭代器返回第一行数据的时间为 0.218 ms,包括索引扫描的 0.214 ms;返回所有数据的平均时间为 0.233 ms,包括索引扫描的 0.228 ms;绝大部分时间都消耗在了索引扫描,总共返回了 2 条数据。
然后循环上一步返回的 2 条数据,扫描 department 表的主键返回其他数据:
-> Single-row index lookup on d using PRIMARY (dept_id=e.dept_id) (cost=0.30 rows=1) (actual time=0.009..0.009 rows=1 loops=2)
其中,loops=2 表示这个迭代器需要执行 2 次;每次返回 1 行数据,所以两个实际时间都是 0.009 ms。
以上示例的预期执行计划和实际执行计划基本上没有什么差异。但有时候并不一定如此,例如:
explain analyze
select *
from employee e
join department d
on (e.dept_id = d.dept_id )
where e.salary = 10000;
-> Nested loop inner join (cost=3.63 rows=3) (actual time=0.427..0.444 rows=1 loops=1)
-> Filter: (e.salary = 10000.00) (cost=2.75 rows=3) (actual time=0.406..0.423 rows=1 loops=1)
-> Table scan on e (cost=2.75 rows=25) (actual time=0.235..0.287 rows=25 loops=1)
-> Single-row index lookup on d using PRIMARY (dept_id=e.dept_id) (cost=0.29 rows=1) (actual time=0.018..0.018 rows=1 loops=1)
我们使用 salary 字段作为过滤条件,该字段没有索引。执行计划中的最大问题在于估计返回的行数是 3,而实际返回的行数是 1;这是由于缺少字段的直方图统计信息。
我们对 employee 表进行分析,收集字段的直方图统计之后再查看执行计划:
analyze table employee update histogram on salary;
explain analyze
select *
from employee e
join department d
on (e.dept_id = d.dept_id )
where e.salary = 10000;
-> Nested loop inner join (cost=3.10 rows=1) (actual time=0.092..0.105 rows=1 loops=1)
-> Filter: (e.salary = 10000.00) (cost=2.75 rows=1) (actual time=0.082..0.093 rows=1 loops=1)
-> Table scan on e (cost=2.75 rows=25) (actual time=0.056..0.080 rows=25 loops=1)
-> Single-row index lookup on d using PRIMARY (dept_id=e.dept_id) (cost=0.35 rows=1) (actual time=0.009..0.009 rows=1 loops=1)
估计返回的行数变成了 1,和实际执行结果相同。
除了本文介绍的各种 EXPLAIN 语句之外,MySQL 还提供了优化器跟踪(optimizer trace)功能,可以获取关于优化器的更多信息,具体可以参考 MySQL Internals:Tracing the Optimizer。
优化
1、MySQL的复制原理以及流程
(1)、复制基本原理流程
- 主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中; 2. 从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进 自己的relay log中; 3. 从:sql执行线程——执行relay log中的语句;
(2)、MySQL复制的线程有几个及之间的关联
MySQL 的复制是基于如下 3 个线程的交互( 多线程复制里面应该是 4 类线程): 1. Master 上面的 binlog dump 线程,该线程负责将 master 的 binlog event 传到slave; 2. Slave 上面的 IO 线程,该线程负责接收 Master 传过来的 binlog,并写入 relay log; 3. Slave 上面的 SQL 线程,该线程负责读取 relay log 并执行; 4. 如果是多线程复制,无论是 5.6 库级别的假多线程还是 MariaDB 或者 5.7 的真正的多线程复制, SQL 线程只做 coordinator,只负责把 relay log 中的 binlog读出来然后交给 worker 线程, woker 线程负责具体 binlog event 的执行;
(3)、MySQL如何保证复制过程中数据一致性及减少数据同步延时
一致性主要有以下几个方面:
1.在 MySQL5.5 以及之前, slave 的 SQL 线程执行的 relay log 的位置只能保存在文件( relay-log.info)里面,并且该文件默认每执行 10000 次事务做一次同步到磁盘, 这意味着 slave 意外 crash 重启时, SQL 线程执行到的位置和数据库的数据是不一致的,将导致复制报错,如果不重搭复制,则有可能会 导致数据不一致。 MySQL 5.6 引入参数 relay_log_info_repository,将该参数设置为 TABLE 时, MySQL 将 SQL 线程执行到的位置存到mysql.slave_relay_log_info 表,这样更新该表的位置和 SQL 线程执行的用户事务绑定成一个事务,这样 slave 意外宕机后, slave 通过 innodb 的崩溃 恢复可以把 SQL 线程执行到的位置和用户事务恢复到一致性的状态。 2. MySQL 5.6 引入 GTID 复制,每个 GTID 对应的事务在每个实例上面最多执行一次, 这极大地提高了复制的数据一致性; 3. MySQL 5.5 引入半同步复制, 用户安装半同步复制插件并且开启参数后,设置超时时间,可保证在超时时间内如果 binlog 不传到 slave 上面,那么用户提交事务时不会返回,直到超时后切成异步复制,但是如果切成异步之前用户线程提交时在 master 上面等待的时候,事务已经提交,该事务对 master 上面的其他 session 是可见的,如果这时 master 宕机,那么到 slave 上面该事务又不可见了,该问题直到 5.7 才解决; 4. MySQL 5.7 引入无损半同步复制,引入参 rpl_semi_sync_master_wait_point,该参数默认为 after_sync,指的是在切成半同步之前,事务不提交,而是接收到 slave 的 ACK 确认之后才提交该事务,从此,复制真正可以做到无损的了。 5.可以再说一下 5.7 的无损复制情况下, master 意外宕机,重启后发现有 binlog没传到 slave 上面,这部分 binlog 怎么办???分 2 种情况讨论, 1 宕机时已经切成异步了, 2 是宕机时还没切成异步??? 这个怎么判断宕机时有没有切成异步呢??? 分别怎么处理???
延时性:
5.5 是单线程复制, 5.6 是多库复制(对于单库或者单表的并发操作是没用的), 5.7 是真正意义的多线程复制,它的原理是基于 group commit, 只要 master 上面的事务是 group commit 的,那 slave 上面也可以通过多个 worker线程去并发执行。 和 MairaDB10.0.0.5 引入多线程复制的原理基本一样。
(4)、工作遇到的复制 bug 的解决方法
5.6 的多库复制有时候自己会停止,我们写了一个脚本重新 start slave;待补充…
2、MySQL中myisam与innodb的区别,至少5点
(1)、问5点不同
1.InnoDB支持事物,而MyISAM不支持事物 2.InnoDB支持行级锁,而MyISAM支持表级锁 3.InnoDB支持MVCC, 而MyISAM不支持 4.InnoDB支持外键,而MyISAM不支持 5.InnoDB不支持全文索引,而MyISAM支持。 6.InnoDB不能通过直接拷贝表文件的方法拷贝表到另外一台机器, myisam 支持 7.InnoDB表支持多种行格式, myisam 不支持 8.InnoDB是索引组织表, myisam 是堆表
(2)、innodb引擎的4大特性
1.插入缓冲(insert buffer) 2.二次写(double write) 3.自适应哈希索引(ahi) 4.预读(read ahead)
(3)、各种不同 mysql 版本的Innodb的改进
MySQL5.6 下 Innodb 引擎的主要改进: ( 1) online DDL ( 2) memcached NoSQL 接口 ( 3) transportable tablespace( alter table discard/import tablespace) ( 4) MySQL 正常关闭时,可以 dump 出 buffer pool 的( space, page_no),重启时 reload,加快预热速度 ( 5) 索引和表的统计信息持久化到 mysql.innodb_table_stats 和mysql.innodb_index_stats,可提供稳定的执行计划 ( 6) Compressed row format 支持压缩表 MySQL 5.7 innodb 引擎主要改进 ( 1) 修改 varchar 字段长度有时可以使用 online DDL ( 2) Buffer pool 支持在线改变大小 ( 3) Buffer pool 支持导出部分比例 ( 4) 支持新建 innodb tablespace,并可以在其中创建多张表 ( 5) 磁盘临时表采用 innodb 存储,并且存储在 innodb temp tablespace 里面,以前是 myisam 存储 ( 6) 透明表空间压缩功能
(4)、2者select count(*)哪个更快,为什么
myisam更快,因为myisam内部维护了一个计数器,可以直接调取。
(5)、2 者的索引的实现方式
都是 B+树索引, Innodb 是索引组织表, myisam 是堆表, 索引组织表和堆表的区别要熟悉
3、MySQL中varchar与char的区别以及varchar(50)中的50代表的涵义
(1)、varchar与char的区别
在单字节字符集下, char( N) 在内部存储的时候总是定长, 而且没有变长字段长度列表中。 在多字节字符集下面, char(N)如果存储的字节数超过 N,那么 char( N)将和 varchar( N)没有区别。在多字节字符集下面,如果存 储的字节数少于 N,那么存储 N 个字节,后面补空格,补到 N 字节长度。 都存储变长的数据和变长字段长度列表。 varchar(N)无论是什么字节字符集,都是变长的,即都存储变长数据和变长字段长度列表。
(2)、varchar(50)中50的涵义
最多存放50个字符,varchar(50)和(200)存储hello所占空间一样,但后者在排序时会消耗更多内存,因为order by col采用fixed_length计算col长度(memory引擎也一样)。在早期 MySQL 版本中, 50 代表字节数,现在代表字符数。
(3)、int(20)中20的涵义
是指显示字符的长度 不影响内部存储,只是影响带 zerofill 定义的 int 时,前面补多少个 0,易于报表展示
(4)、mysql为什么这么设计
对大多数应用没有意义,只是规定一些工具用来显示字符的个数;int(1)和int(20)存储和计算均一样;
4、innodb的事务与日志的实现方式
(1)、有多少种日志
redo和undo
(2)、日志的存放形式
redo:在页修改的时候,先写到 redo log buffer 里面, 然后写到 redo log 的文件系统缓存里面(fwrite),然后再同步到磁盘文件( fsync)。 Undo:在 MySQL5.5 之前, undo 只能存放在 ibdata*文件里面, 5.6 之后,可以通过设置 innodb_undo_tablespaces 参数把 undo log 存放在 ibdata*之外。
(3)、事务是如何通过日志来实现的,说得越深入越好
基本流程如下: 因为事务在修改页时,要先记 undo,在记 undo 之前要记 undo 的 redo, 然后修改数据页,再记数据页修改的 redo。 Redo(里面包括 undo 的修改) 一定要比数据页先持久化到磁盘。 当事务需要回滚时,因为有 undo,可以把数据页回滚到前镜像的 状态,崩溃恢复时,如果 redo log 中事务没有对应的 commit 记录,那么需要用 undo把该事务的修改回滚到事务开始之前。 如果有 commit 记录,就用 redo 前滚到该事务完成时并提交掉。
5、MySQL binlog的几种日志录入格式以及区别
(1)、各种日志格式的涵义
1.Statement:每一条会修改数据的sql都会记录在binlog中。 优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。(相比row能节约多少性能 与日志量,这个取决于应用的SQL情况,正常同一条记录修改或者插入row格式所产生的日志量还小于Statement产生的日志量, 但是考虑到如果带条 件的update操作,以及整表删除,alter表等操作,ROW格式会产生大量日志,因此在考虑是否使用ROW格式日志时应该跟据应用的实际情况,其所 产生的日志量会增加多少,以及带来的IO性能问题。) 缺点:由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的 一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同 的结果。另外mysql 的复制, 像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数, last_insert_id(),以及user-defined functions(udf)会出现问题). 使用以下函数的语句也无法被复制: * LOAD_FILE() * UUID() * USER() * FOUND_ROWS() * SYSDATE() (除非启动时启用了 –sysdate-is-now 选项) 同时在INSERT …SELECT 会产生比 RBR 更多的行级锁 2.Row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。 优点: binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下 每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题 缺点:所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比 如一条update语句,修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter table之类的语句的时候, 由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。 3.Mixedlevel: 是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则 采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式, 也就是在Statement和Row之间选择 一种.新版本的MySQL中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
(2)、适用场景
在一条 SQL 操作了多行数据时, statement 更节省空间, row 更占用空间。但是 row模式更可靠。
(3)、结合第一个问题,每一种日志格式在复制中的优劣
Statement 可能占用空间会相对小一些,传送到 slave 的时间可能也短,但是没有 row模式的可靠。 Row 模式在操作多行数据时更占用空间, 但是可靠。
6、下MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出占用高的进程,并进行相关处理。如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql, 看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。也有可能是每个 sql 消耗资源并不多,但是突然之间, 有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
7、sql优化
(1)、explain出来的各种item的意义
id:每个被独立执行的操作的标志,表示对象被操作的顺序。一般来说, id 值大,先被执行;如果 id 值相同,则顺序从上到下。 select_type:查询中每个 select 子句的类型。 table:名字,被操作的对象名称,通常的表名(或者别名),但是也有其他格式。 partitions:匹配的分区信息。 type:join 类型。 possible_keys:列出可能会用到的索引。 key:实际用到的索引。 key_len:用到的索引键的平均长度,单位为字节。 ref:表示本行被操作的对象的参照对象,可能是一个常量用 const 表示,也可能是其他表的 key 指向的对象,比如说驱动表的连接列。 rows:估计每次需要扫描的行数。 filtered:rows*filtered/100 表示该步骤最后得到的行数(估计值)。 extra:重要的补充信息。
(2)、profile的意义以及使用场景
Profile 用来分析 sql 性能的消耗分布情况。当用 explain 无法解决慢 SQL 的时候,需要用profile 来对 sql 进行更细致的分析,找出 sql 所花的时间大部分消耗在哪个部分,确认 sql的性能瓶颈。
(3)、explain 中的索引问题
Explain 结果中,一般来说,要看到尽量用 index(type 为 const、ref 等, key 列有值),避免使用全表扫描(type 显式为 ALL)。比如说有 where 条件且选择性不错的列,需要建立索引。 被驱动表的连接列,也需要建立索引。被驱动表的连接列也可能会跟 where 条件列一起建立联合索引。当有排序或者 group by 的需求时,也可以考虑建立索引来达到直接排序和汇总的需求。
8、备份计划,mysqldump以及xtranbackup的实现原理
(1)、备份计划
视库的大小来定,一般来说 100G 内的库,可以考虑使用 mysqldump 来做,因为 mysqldump更加轻巧灵活,备份时间选在业务低峰期,可以每天进行都进行全量备份(mysqldump 备份 出来的文件比较小,压缩之后更小)。100G 以上的库,可以考虑用 xtranbackup 来做,备份速度明显要比 mysqldump 要快。一般是选择一周一个全备,其余每天进行增量备份,备份时间为业务低峰期。
(2)、备份恢复时间
物理备份恢复快,逻辑备份恢复慢 这里跟机器,尤其是硬盘的速率有关系,以下列举几个仅供参考 20G的2分钟(mysqldump) 80G的30分钟(mysqldump) 111G的30分钟(mysqldump) 288G的3小时(xtra) 3T的4小时(xtra) 逻辑导入时间一般是备份时间的5倍以上
(3)、备份恢复失败如何处理
首先在恢复之前就应该做足准备工作,避免恢复的时候出错。比如说备份之后的有效性检查、权限检查、空间检查等。如果万一报错,再根据报错的提示来进行相应的调整。
(4)、mysqldump和xtrabackup实现原理
mysqldump
mysqldump 属于逻辑备份。加入–single-transaction 选项可以进行一致性备份。后台进程会先设置 session 的事务隔离级别为 RR(SET SESSION TRANSACTION ISOLATION LEVELREPEATABLE READ), 之后显式开启一个事务(START TRANSACTION /*!40100 WITH CONSISTENTSNAPSHOT */),这样就保证了该事务里读到的数据都是事务事务时候的快照。之后再把表的数据读取出来。 如果加上–master-data=1 的话,在刚开始的时候还会加一个数据库的读锁 (FLUSH TABLES WITH READ LOCK),等开启事务后,再记录下数据库此时 binlog 的位置(showmaster status),马上解锁,再读取表的数据。等所有的数据都已经导完,就可以结束事务
Xtrabackup:
xtrabackup 属于物理备份,直接拷贝表空间文件,同时不断扫描产生的 redo 日志并保存下来。最后完成 innodb 的备份后,会做一个 flush engine logs 的操作(老版本在有 bug,在5.6 上不做此操作会丢数据),确保所有的 redo log 都已经落盘(涉及到事务的两阶段提交 概念,因为 xtrabackup 并不拷贝 binlog,所以必须保证所有的 redo log 都落盘,否则可能会丢最后一组提交事务的数据)。这个时间点就是 innodb 完成备份的时间点,数据文件虽然不是一致性的,但是有这段时间的 redo 就可以让数据文件达到一致性(恢复的时候做的事 情)。然后还需要 flush tables with read lock,把 myisam 等其他引擎的表给备份出来,备份完后解锁。 这样就做到了完美的热备。
9、mysqldump中备份出来的sql,如果我想sql文件中,一行只有一个insert….value()的话,怎么办?如果备份需要带上master的复制点信息怎么办?
--skip-extended-insert [root\@helei-zhuanshu ~]# mysqldump -uroot -p helei –skip-extended-insert Enter password: KEY `idx_c1` (`c1`), KEY `idx_c2` (`c2`) ) ENGINE=InnoDB AUTO_INCREMENT=51 DEFAULT CHARSET=latin1; /*!40101 SET character_set_client = @saved_cs_client */; – – Dumping data for table `helei` – LOCK TABLES `helei` WRITE; /*!40000 ALTER TABLE `helei` DISABLE KEYS */; INSERT INTO `helei` VALUES (1,32,37,38,’2016-10-18 06:19:24’,’susususususususususususu’); INSERT INTO `helei` VALUES (2,37,46,21,’2016-10-18 06:19:24’,’susususususu’); INSERT INTO `helei` VALUES (3,21,5,14,’2016-10-18 06:19:24’,’susu’);
10、500台db,在最快时间之内重启
可以使用批量 ssh 工具 pssh 来对需要重启的机器执行重启命令。 也可以使用 salt(前提是客户端有安装 salt)或者 ansible( ansible 只需要 ssh 免登通了就行)等多线程工具同时操作多台服务器
11、innodb的读写参数优化
(1)、读取参数
global buffer 以及 local buffer; Global buffer: Innodb_buffer_pool_size innodb_log_buffer_size innodb_additional_mem_pool_size local buffer(下面的都是 server 层的 session 变量,不是 innodb 的): Read_buffer_size Join_buffer_size Sort_buffer_size Key_buffer_size Binlog_cache_size
(2)、写入参数
innodb_flush_log_at_trx_commit innodb_buffer_pool_size insert_buffer_size innodb_double_write innodb_write_io_thread innodb_flush_method
(3)、与IO相关的参数
innodb_write_io_threads = 8 innodb_read_io_threads = 8 innodb_thread_concurrency = 0 Sync_binlog Innodb_flush_log_at_trx_commit Innodb_lru_scan_depth Innodb_io_capacity Innodb_io_capacity_max innodb_log_buffer_size innodb_max_dirty_pages_pct
(4)、缓存参数以及缓存的适用场景
query cache/query_cache_type 并不是所有表都适合使用query cache。造成query cache失效的原因主要是相应的table发生了变更 第一个:读操作多的话看看比例,简单来说,如果是用户清单表,或者说是数据比例比较固定,比如说商品列表,是可以打开的,前提是这些库比较集中,数据库中的实务比较小。 第二个:我们“行骗”的时候,比如说我们竞标的时候压测,把query cache打开,还是能收到qps激增的效果,当然前提示前端的连接池什么的都配置一样。大部分情况下如果写入的居多,访问量并不多,那么就不要打开,例如社交网站的,10%的人产生内容,其余的90%都在消费,打开还是效果很好的,但是你如果是qq消息,或者聊天,那就很要命。 第三个:小网站或者没有高并发的无所谓,高并发下,会看到 很多 qcache 锁 等待,所以一般高并发下,不建议打开query cache
12、你是如何监控你们的数据库的?你们的慢日志都是怎么查询的?
监控的工具有很多,例如zabbix,lepus,我这里用的是lepus
13、你是否做过主从一致性校验,如果有,怎么做的,如果没有,你打算怎么做?
主从一致性校验有多种工具 例如checksum、mysqldiff、pt-table-checksum等
14、表中有大字段X(例如:text类型),且字段X不会经常更新,以读为为主,请问您是选择拆成子表,还是继续放一起?写出您这样选择的理由
答:拆带来的问题:连接消耗 + 存储拆分空间;不拆可能带来的问题:查询性能; 如果能容忍拆分带来的空间问题,拆的话最好和经常要查询的表的主键在物理结构上放置在一起(分区) 顺序IO,减少连接消耗,最后这是一个文本列再加上一个全文索引来尽量抵消连接消耗 如果能容忍不拆分带来的查询性能损失的话:上面的方案在某个极致条件下肯定会出现问题,那么不拆就是最好的选择
15、MySQL中InnoDB引擎的行锁是通过加在什么上完成(或称实现)的?为什么是这样子的?
答:InnoDB是基于索引来完成行锁 例: select * from tab_with_index where id = 1 for update; for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列, 如果 id 不是索引键那么InnoDB将完成表锁,,并发将无从谈起
16、如何从mysqldump产生的全库备份中只恢复某一个库、某一张表?
全库备份 [root\@HE1 ~]# mysqldump -uroot -p –single-transaction -A –master-data=2 >dump.sql 只还原erp库的内容 [root\@HE1 ~]# mysql -uroot -pMANAGER erp –one-database <dump.sql 可以看出这里主要用到的参数是–one-database简写-o的参数,极大方便了我们的恢复灵活性 那么如何从全库备份中抽取某张表呢,全库恢复,再恢复某张表小库还可以,大库就很麻烦了,那我们可以利用正则表达式来进行快速抽取,具体实现方法如下: 从全库备份中抽取出t表的表结构 [root\@HE1 ~]# sed -e’/./{H;$!d;}’ -e ‘x;/CREATE TABLE `t`/!d;q’ dump.sql DROP TABLE IF EXISTS`t`; /*!40101 SET\@saved_cs_client =@@character_set_client */; /*!40101 SETcharacter_set_client = utf8 */; CREATE TABLE `t` ( `id` int(10) NOT NULL AUTO_INCREMENT, `age` tinyint(4) NOT NULL DEFAULT ‘0’, `name` varchar(30) NOT NULL DEFAULT ‘’, PRIMARY KEY (`id`) ) ENGINE=InnoDBAUTO_INCREMENT=4 DEFAULT CHARSET=utf8; /*!40101 SETcharacter_set_client = @saved_cs_client */; 从全库备份中抽取出t表的内容 [root\@HE1 ~]# grep’INSERT INTO `t`’ dump.sql INSERT INTO `t`VALUES (0,0,’’),(1,0,’aa’),(2,0,’bbb’),(3,25,’helei’);
18、请简洁地描述下 MySQL 中 InnoDB 支持的四种事务隔离级别名称,以及逐级之间的区别?
(1)、事物的4种隔离级别
读未提交(read uncommitted) 读已提交(read committed) 可重复读(repeatable read) 串行(serializable)
(2)、不同级别的现象
Read Uncommitted:可以读取其他 session 未提交的脏数据。 Read Committed:允许不可重复读取,但不允许脏读取。提交后,其他会话可以看到提交的数据。 Repeatable Read: 禁止不可重复读取和脏读取、以及幻读(innodb 独有)。 Serializable: 事务只能一个接着一个地执行,但不能并发执行。事务隔离级别最高。 不同的隔离级别有不同的现象,并有不同的锁定/并发机制,隔离级别越高,数据库的并发性就越差。
面试中其他的问题:
1、2 年 MySQL DBA 经验
其中许多有水分,一看到简历自我介绍,说公司项目的时候,会写上 linux 系统维护,mssql server 项目,或者 oracle data gard 项目,一般如果有这些的话,工作在 3 年到 4年的话,他的 2 年 MySQL DBA 管理经验,是有很大的水分的。刚开始我跟领导说,这些 不用去面试了,肯定 mysql dba 经验不足,领导说先面面看看,于是我就面了,结果很多人卡在基础知识这一环节之上,比如: ( 1)有的卡在复制原理之上 ( 2)有的卡在 binlog 的日志格式的种类和分别 ( 3)有的卡在 innodb 事务与日志的实现上。 ( 4)有的卡在 innodb 与 myisam 的索引实现方式的理解上面。 ……… 个人觉得如果有过真正的 2 年 mysql 专职 dba 经验,那么肯定会在 mysql 的基本原理上有所研究,因为很多问题都不得不让你去仔细研究各种细节,而自 己研究过的细节肯定会记忆深刻,别人问起一定会说的头头是道,起码一些最基本的关键参数比如 Seconds_Behind_Master 为 60 这个值 60 的准确涵义,面试了 10+的 mysql dba,没有一个说的准确,有的说不知道忘记了,有的说是差了 60 秒,有的说是与主上执行时间延后了 60 秒。
2 、对于简历中写有熟悉 mysql 高可用方案
我一般先问他现在管理的数据库架构是什么,如果他只说出了主从,而没有说任何 ha的方案,那么我就可以判断出他没有实际的 ha 经验。不过这时候也不能就是 断定他不懂mysql 高可用,也许是没有实际机会去使用,那么我就要问 mmm 以及 mha 以及mm+keepalived 等的原理 实现方式以及它们之间的优 势和不足了,一般这种情况下,能说出这个的基本没有。mmm 那东西好像不靠谱,据说不稳定,但是有人在用的,我只在虚拟机上面用过,和mysql-router 比较像,都是指定可写的机器和只读机器。 MHA 的话一句话说不完,可以翻翻学委的笔记
3 、对于简历中写有批量 MySQL 数据库服务器的管理经验
这个如果他说有的话,我会先问他们现在实际线上的 mysql 数据库数量有多少,分多少个节点组,最后问这些节点组上面的 slow log 是如何组合在一起来统计分析的。如果这些他都答对了,那么我还有一问,就是现在手上有 600 台数据库,新来的机器, Mysql 都 安装好了,那么你如 何在最快的时间里面把这 600 台 mysql 数据库的 mysqld 服务启动起来。这个重点在于最快的时间,而能准确回答出清晰思路的只有 2 个人。slow log 分析:可以通过一个管理服务器定时去各台 MySQL 服务器上面 mv 并且 cp slowlog, 然后分析入库,页面展示。最快的时间里面启动 600 台服务器: 肯定是多线程。 可以用 pssh, ansible 等多线程批量管理服务器的工具
4 、对于有丰富的 SQL 优化的经验
首先问 mysql 中 sql 优化的思路,如果能准备说出来, ok,那么我就开始问 explain的各种参数了,重点是 select_type, type, possible_key, ref,rows,extra 等参数的各种 值的含义,如果他都回答正确了,那么我再问 file sort 的含义以及什么时候会出现这个分析结果,如果这里他也回答对了,那么我就准备问 profile 分析了,如果这里他也答对了,那么我就会再问一个问 题, 那是曾经 tx 问我的让我郁闷不已的问题,一个 6 亿的表 a,一个 3 亿的表 b,通过外间 tid 关联,你如何最快的查询出满足条件的第 50000 到第 50200中的这 200 条数据记录。 Explain 在上面的题目中有了,这里就不说了。如何最快的查询出满足条件的第 50000 到第 50200 中的这 200 条数据记录?这个我想不出来! 关于 explain 的各种参数,请参考: http://blog.csdn.net/mchdba/article/details/9190771
5、对于有丰富的数据库设计经验
这个对于数据库设计我真的没有太多的经验,我也就只能问问最基础的, mysql 中varchar(60) 60 是啥含义, int(30)中 30 是啥含义? 如果他都回答对了,那么我就问 mysql中为什么要这么设计呢? 如果他还回答对了,我就继续问 int(20)存储的数字的上限和下限是多少?这个问题难道了全部的 mysql dba 的应聘者,不得不佩服提出这个问题的金总的睿智啊,因为这个问题回答正确了, 那么他确实认认真真地研究了 mysql 的设计中关于字段类型的细节。至 于丰富的设计数据库的经验,不用着急,这不我上面还有更加厉害的 dba吗,他会搞明白的,那就跟我无关了。 varchar(60)的 60 表示最多可以存储 60 个字符。int(30)的 30 表示客户端显示这个字段的宽度。 为何这么设计?说不清楚,请大家补充 。 int(20)的上限为 2147483647(signed)或者4294967295(unsigned)。
6 、关于 mysql 参数优化的经验
首先问他它们线上 mysql 数据库是怎么安装的,如果说是 rpm 安装的,那么我就直接问调优参数了,如果是源码安装的,那么我就要问编译中的一些参数了,比如 my.cnf 以及存储引擎以及字符类型等等。然后从以下几个方面问起: ( 1) mysql 有哪些 global 内存参数,有哪些 local 内存参数。 Global: innodb_buffer_pool_size/innodb_additional_mem_pool_size/innodb_log_buffer_size/key_buffer_size/query_cache_size/table_open_cache/table_definition_cache/thread_cache_size Local: read_buffer_size/read_rnd_buffer_size/sort_buffer_size/join_buffer_size/binlog_cache_size/tmp_table_size/thread_stack/bulk_insert_buffer_size ( 2) mysql 的写入参数需要调整哪些?重要的几个写参数的几个值得含义以及适用场景, 比如 innodb_flush_log_at_trx_commit 等。 (求补充) sync_binlog 设置为 1,保证 binlog 的安全性。 innodb_flush_log_at_trx_commit: 0:事务提交时不将 redo log buffer 写入磁盘(仅每秒进行 master thread 刷新,安全 性最差,性能最好) 1:事务提交时将 redo log buffer 写入磁盘(安全性最好,性能最差, 推荐生产使用) 2:事务提交时仅将 redo log buffer 写入操作系统缓存(安全性和性能都居中,当 mysql宕机但是操作系统不宕机则不丢数据,如果操作系统宕机,最多丢一秒数据) innodb_io_capacity/innodb_io_capacity_max:看磁盘的性能来定。如果是 HDD 可以设置为 200-几百不等。如果是 SSD,推荐为 4000 左右。 innodb_io_capacity_max 更大一些。 innodb_flush_method 设置为 O_DIRECT。 ( 3) 读取的话,那几个全局的 pool 的值的设置,以及几个 local 的 buffer 的设置。 Global: innodb_buffer_pool_size:设置为可用内存的 50%-60%左右,如果不够,再慢慢上调。 innodb_additional_mem_pool_size:采用默认值 8M 即可。 innodb_log_buffer_size:默认值 8M 即可。 key_buffer_size:myisam 表需要的 buffer size,选择基本都用 innodb,所以采用默认的 8M 即可。 Local: join_buffer_size: 当 sql 有 BNL 和 BKA 的时候,需要用的 buffer_size(plain index scans, range index scans 的时候可能也会用到)。默认为 256k,建议设置为 16M-32M。 read_rnd_buffer_size:当使用 mrr 时,用到的 buffer。默认为 256k,建议设置为16-32M。 read_buffer_size:当顺序扫描一个 myisam 表,需要用到这个 buffer。或者用来决定memory table 的大小。或者所有的 engine 类型做如下操作:order by 的时候用 temporaryfile、SELECT INTO … OUTFILE ‘filename’ 、For caching results of nested queries。默认为 128K,建议为 16M。 sort_buffer_size: sql 语句用来进行 sort 操作(order by,group by)的 buffer。如果 buffer 不够,则需要建立 temporary file。如果在 show global status 中发现有大量的 Sort_merge_passes 值,则需要考虑调大 sort_buffer_size。默认为 256k,建议设置为 16-32M。 binlog_cache_size: 表示每个 session 中存放 transaction 的 binlog 的 cache size。默认 32K。一般使用默认值即可。如果有大事务,可以考虑调大。 thread_stack: 每个进程都需要有,默认为 256K,使用默认值即可。 ( 4) 还有就是著名的 query cache 了,以及 query cache 的适用场景了,这里有一个陷阱, 就是高并发的情况下,比如双十一的时候, query cache 开还是不开,开了怎么保证高并发,不开又有何别的考虑?建议关闭,上了性能反而更差。
7、关于熟悉 mysql 的锁机制
gap 锁, next-key 锁,以及 innodb 的行锁是怎么实现的,以及 myisam 的锁是怎么实现的等 Innodb 的锁的策略为 next-key 锁,即 record lock+gap lock。是通过在 index 上加 lock 实现的,如果 index 为 unique index,则降级为 record lock,如果是普通 index,则为 next-key lock,如果没有 index,则直接锁住全表。 myisam 直接使用全表扫描。
8、 关于熟悉 mysql 集群的
我就问了 ndbd 的节点的启动先后顺序,再问配置参数中的内存配置几个重要的参数,再问 sql 节点中执行一个 join 表的 select 语句的实现流程是怎么走的? ok,能回答的也只有一个。 关于 mysql 集群入门资料,请参考: http://write.blog.csdn.net/postlist/1583151/all
9、 关于有丰富的备份经验的
就问 mysqldump 中备份出来的 sql,如果我想 sql 文件中,一行只有一个 insert …. value()的话,怎么办?如果备份需要带上 master 的复制点信息怎么办?或者 xtrabackup 中如何 做到实时在线备份的?以及 xtrabackup 是如何做到带上 master 的复制点的信息的? 当前 xtrabackup 做增量备份的时候有何缺陷?能全部回答出来的没有一个,不过没有关系,只要回答出 mysqldump 或者xtrabackup 其中一个的也可以。 1). –skip-extended-insert 2). –master-date=1 3). 因为 xtrabackup 是多线程,一个线程不停地在拷贝新产生的 redo 文件,另外的线程去备份数据库,当所有表空间备份完成的时候,它会执行 flush table with read lock 操作 锁住所有表,然后执行 show master status; 接着执行 flush engine logs; 最后解锁表。执行 show master status; 时就能获取到 mster 的复制点信息,执行 flush engine logs 强制把redo 文件刷新到磁盘。 4). xtrabackup 增量备份的缺陷不了解,在线上用 xtrabackup 备份没有发现什么缺陷
10 、关于有丰富的线上恢复经验的
就问你现在线上数据量有多大,如果是 100G,你用 mysqldump 出来要多久,然后 mysql进去又要多久,如果互联网不允许延时的话,你又怎么做到 恢复单张表的时候保证 nagios不报警。如果有人说 mysqldump 出来 1 个小时就 ok 了,那么我就要问问他 db 服务器是 啥配置了,如果他说 mysql 进去 50 分钟搞定了,那么我也要问问他 db 机器啥配置了,如果是普通的吊丝 pc server,那么真实性,大家懂得。然后如果你用 xtrabackup 备份要多久,恢复要多久,大家都知道 copy-back 这一步要很久,那么你有没有办法对这一块优化。
一、现有表结构如下图
TABLENAME:afinfo
| Id | name | age | birth | sex | memo |
| :- | :— | :– | :——— | :– | :–: | :- | :- |
| 1 | 徐洪国 | 37 | 1979-03-23 | 男 | 高中 |
| 2 | 王芳 | 26 | 1988-02-06 | 女 | 本科 |
| 3 | 李达康 | 24 | 1990-04-02 | 男 | 硕士 |
| 4 | 侯亮平 | 30 | 1984-09-12 | 女 | 博士 |
| 5 | 徐夫子 | 27 | 1987-12-30 | 男 | 大专 |
| 6 | …… | …… | …… | …… | …… |
1)请编写sql语句对年龄进行升序排列
mysql> select * from afinfo -> order by birth;
2)请编写sql语句查询对“徐”姓开头的人员名单
mysql> select * from afinfo -> where name like ‘徐%’;
3)请编写sql语句修改“李达康”的年龄为“45”
mysql> update afinfo -> set age=45 -> where name=’李达康’;
4)请编写sql删除王芳这表数据记录。
mysql> delete from afinfo -> where name=’王芳’;
二、现有以下学生表和考试信息表
学生信息表(student)
| 姓名name | 学号code |
| :—– | :—– |
| 张三 | 001 |
| 李四 | 002 |
| 马五 | 003 |
| 甲六 | 004 |
考试信息表(exam)
| 学号code | 学科subject | 成绩score |
| :—– | :——– | :—— |
| 001 | 数学 | 80 |
| 002 | 数学 | 75 |
| 001 | 语文 | 90 |
| 002 | 语文 | 80 |
| 001 | 英语 | 90 |
| 002 | 英语 | 85 |
| 003 | 英语 | 80 |
| 004 | 英语 | 70 |
1)查询出所有学生信息,SQL怎么编写?
mysql> select * from student;
2)新学生小明,学号为005,需要将信息写入学生信息表,SQL语句怎么编写?
mysql> insert into student values(‘小明’,’005’);
3)李四语文成绩被登记错误,成绩实际为85分,更新到考试信息表中,SQL语句怎么编写?
mysql> update exam,student -> set exam.score=85 -> where student.code=exam.code -> and student.name=’李四’ -> and exam.subject=’语文’;
4)查询出各科成绩的平均成绩,显示字段为:学科、平均分,SQL怎么编写?
mysql> select subject 学科,avg(score) 平均分 -> from exam -> group by subject;
5)查询出所有学生各科成绩,显示字段为:姓名、学号、学科、成绩,并以学号与学科排序,没有成绩的学生也需要列出,SQL怎么编写?
mysql> select s.name 姓名,s.code 学号,e.subject 学科,e.score 成绩 -> from student s -> left join exam e -> on s.code=e.code -> order by 学号,学科;
6)查询出单科成绩最高的,显示字段为:姓名、学号、学科、成绩,SQL怎么编写?
mysql> select s.name 姓名,s.code 学号,e.subject 学科,e.score 成绩 -> from student s -> join exam e -> on s.code=e.code -> where (e.subject,e.score) in -> ( -> select subject,max(score) -> from exam -> group by subject -> );
7)列出每位学生的各科成绩,要求输出格式:姓名、学号、语文成绩、数学成绩、英语成绩,SQL怎么编写?
mysql> select s.name 姓名,s.code 学号, -> sum(if(e.subject=’语文’,e.score,0)) 语文成绩, -> sum(if(e.subject=’数学’,e.score,0)) 数学成绩, -> sum(if(e.subject=’英语’,e.score,0)) 英语成绩 -> from student s -> left join exam e -> on s.code=e.code -> group by s.name,s.code;
三、根据要求写出SQL语句
表结构:
student(s_no,s_name,s_age,sex) 学生表
teacher(t_no,t_name) 教师表
course(c_no,c_name,t_no) 课程表
sc(s_no,c_no,score) 成绩表
基础表数据(个人铺的):根据题目需要自行再铺入数据
| mysql> select * from student; +——+——–+——-+——+ | s_no | s_name | s_age | sex | +——+——–+——-+——+ | 1001 | 张三 | 23 | 男 | 1002 | 李四 | 19 | 女 | 1003 | 马五 | 20 | 男 | 1004 | 甲六 | 17 | 女 | 1005 | 乙七 | 22 | 男 | +——+——–+——-+——+ 5 rows in set (0.00 sec) mysql> select * from teacher; +——+——–+ | t_no | t_name | +——+——–+ | 2001 | 叶平 | 2002 | 赵安 | 2003 | 孙顺 | 2004 | 刘六 | +——+——–+ 4 rows in set (0.00 sec) mysql> select * from course; +——+————–+——+ | c_no | c_name | t_no | +——+————–+——+ | 001 | 企业管理 | 2001 | 002 | 马克思 | 2002 | 003 | UML | 2003 | 004 | 数据库 | 2004 | +——+————–+——+ 4 rows in set (0.05 sec) mysql> select * from sc; +——+——+——-+ | s_no | c_no | score | +——+——+——-+ | 1001 | 001 | 93 | 1001 | 002 | 86 | 1001 | 004 | 92 | 1002 | 003 | 100 | 1003 | 001 | 93 | 1003 | 004 | 99 | 1004 | 002 | 75 | 1004 | 003 | 59 | 1002 | 002 | 50 | 1005 | 003 | 60 | 1005 | 002 | 60 | +——+——+——-+ 11 rows in set (0.00 sec) |
1、查询“001”课程比“002”课程成绩高的所有学生的学号。
mysql> select a.s_no -> from -> (select s_no,score from sc where c_no=’001’) a, -> (select s_no,score from sc where c_no=’002’) b -> where a.score>b.score -> and a.s_no=b.s_no;
2、查询平均成绩大于60分的同学的学号和平均成绩。
mysql> select s_no,avg(score) -> from sc -> group by s_no -> having avg(score)>60;
3、查询所有同学的学号、姓名、选课数、总成绩。
mysql> select student.s_no,student.s_name,count(sc.c_no),sum(sc.score) -> from student -> left join sc -> on student.s_no=sc.s_no -> group by student.s_no,student.s_name;
4、查询姓李的老师的个数。
mysql> select count(*) -> from teacher -> where t_name like ‘李%’;
5、查询没学过“叶平”老师课的同学的学号、姓名
mysql> select student.s_no,student.s_name -> from student -> where student.s_no not in -> ( -> select distinct(sc.s_no) -> from sc -> join course -> on course.c_no=sc.c_no -> join teacher -> on teacher.t_no=course.t_no -> where t_name=’叶平’ -> );
6、查询学过“001”并且也学过编号“002”课程的同学的学号、姓名。
mysql> select student.s_no,student.s_name -> from student -> join sc -> on sc.s_no=student.s_no -> where c_no=’001’ -> and exists -> (select * from sc where sc.s_no=student.s_no and c_no=’002’);
7、查询学过“叶平”老师所教的所有课的同学的学号、姓名。
mysql> select student.s_no,student.s_name -> from student -> join sc -> on sc.s_no=student.s_no -> join course -> on course.c_no=sc.c_no -> join teacher -> on teacher.t_no=course.t_no -> where teacher.t_name=’叶平’;
8、查询课程编号“002”的成绩比课程编号“001”课程低的所有同学的学号、姓名。
mysql> select student.s_no,student.s_name -> from student -> join (select s_no,score from sc where c_no=’001’) a -> on a.s_no=student.s_no -> join (select s_no,score from sc where c_no=’002’) b -> on b.s_no=student.s_no -> where a.s_no=b.s_no -> and a.score>b.score;
9、查询所有课程成绩小于60分的同学的学号、姓名。
mysql> select student.s_no,student.s_name -> from student -> join sc -> on sc.s_no=student.s_no -> where sc.score<60;
10、查询没有学全所有课的同学的学号、姓名。
mysql> select student.s_no 学号,student.s_name 姓名 -> from student -> left join sc -> on sc.s_no=student.s_no -> group by student.s_no,student.s_name -> having count(*) < ( -> select count(*) from course);
11、查询至少有一门课与学号为“1001”的同学所学相同的同学的学号和姓名。
mysql> select student.s_no,student.s_name -> from student -> join sc -> on sc.s_no=student.s_no -> where sc.c_no in -> ( -> select c_no -> from sc -> where s_no=’1001’ -> ) -> and student.s_no != ‘1001’;
12、查询至少学过学号为“1001”同学所有一门课的其他同学学号和姓名。
mysql> select distinct sc.s_no,s_name -> from student,sc -> where student.s_no=sc.s_no -> and c_no in -> (select c_no from sc where s_no=1001) -> and student.s_no != ‘1001’;
13、把“sc”表中“叶平”老师叫的课的成绩都更改为此课程的平均成绩。
mysql> set @ye_avg_score= -> ( -> select avg(score) -> from -> ( -> select sc.score -> from sc -> join course -> on course.c_no=sc.c_no -> join teacher -> on teacher.t_no=course.t_no -> where teacher.t_name=’叶平’ -> ) azi -> ); mysql> update sc -> set score=@ye_avg_score -> where c_no in -> ( -> select c_no -> from course -> join teacher -> on teacher.t_no=course.t_no -> where teacher.t_name=’叶平’ -> );
14、查询和“1002”号同学学习的课程完全相同的其他同学学号和姓名。
mysql> select s_no,s_name -> from student -> where s_no in ( -> select distinct s_no from sc where c_no in -> (select c_no from sc where s_no=’1002’) -> group by s_no -> having count(*)=(select count(*) from sc where s_no=’1002’) -> and s_no<>’1002’ -> );
15、删除学习“叶平”老师课的sc表记录。
mysql> set @ye_c_no=(select c_no from course,teacher where course.t_no=teacher.t_no and t_name=’叶平’); mysql> delete from sc -> where c_no=@ye_c_no;
16、向sc表中插入一些记录,这些记录要求符合一下条件:没有上过编号“003”课程的同学学号
mysql> select distinct s_no from sc -> where c_no not in (select c_no from sc where c_no=’003’) -> and s_no not in (select s_no from sc where c_no=’003’);
17、查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分。
mysql> select c_no 课程ID,max(score) 最高分,min(score) 最低分 -> from sc -> group by c_no;
18、按照平均成绩从高到低显示所有学生的“数据库”、“企业管理”、“马克思”三门的课程成绩,按如下形式显示:学生ID,数据库,企业管理,马克思,有效课程数,有效平均分。
mysql> select sc.s_no 学号, -> max(case c_name when ‘数据库’ then score end) 数据库, -> max(case c_name when ‘企业管理’ then score end) 企业管理, -> max(case c_name when ‘马克思’ then score end) 马克思, -> count(sc.s_no) 有效课程数, -> avg(ifnull(score,0)) 有效平均分 -> from sc,course -> where sc.c_no=course.c_no -> group by sc.s_no -> order by 6 desc;
19、查询不同老师所教不同课程平均分从高到低显示。
mysql> select c_no,avg(score) -> from sc -> group by c_no -> order by 2 desc;
20、查询如下课程成绩第3名到第6名的学生成绩单:企业管理(001)、马克思(002),UML(003),数据库(004)
mysql> (select student.s_no,s_name,c_no,score from student,sc where student.s_no=sc.s_no and c_no=001 order by score desc limit 2,4) -> union -> (select student.s_no,s_name,c_no,score from student,sc where student.s_no=sc.s_no and c_no=002 order by score desc limit 2,4) -> union -> (select student.s_no,s_name,c_no,score from student,sc where student.s_no=sc.s_no and c_no=003 order by score desc limit 2,4) -> union -> (select student.s_no,s_name,c_no,score from student,sc where student.s_no=sc.s_no and c_no=004 order by score desc limit 2,4);
21、统计各科成绩,各分数段人数:课程ID,课程名称,【100-85】,【85-70】,【70-60】,【<60】
mysql> select course.c_no 课程ID,c_name 课程名称, -> count(case when score>85 and score<=100 then score end) ‘[85-100]’, -> count(case when score>70 and score<=85 then score end) ‘[70-85]’, -> count(case when score>=60 and score<=70 then score end) ‘[60-70]’, -> count(case when score<60 then score end) ‘[<60]’ -> from course,sc -> where course.c_no=sc.c_no -> group by course.c_no,c_name;
22、查询每门课程被选修的学生数
mysql> select c_no 课程ID,count(s_no) 学生人数 -> from sc -> group by c_no;
23、查询出只选修了一门课程的全部学生的学号和姓名
mysql> select student.s_no 学号,student.s_name 姓名,count(c_no) 选课数 -> from student -> join sc -> on sc.s_no=student.s_no -> group by student.s_no,student.s_name -> having count(c_no)=1;
24、查询同名同性学生名单,并统计同名人数。
mysql> select s_name 姓名,count(*) -> from student -> group by s_name -> having count(*)>1;
25、查询1994年出生的学生名单(注:student表中sage列的类型是datatime)
mysql> select * from student -> where year(curdate())-s_age=’1994’;
26、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列。
mysql> select c_no 课程ID,avg(score) -> from sc -> group by c_no -> order by avg(score) asc,c_no desc;
27、查询平均成绩都大于85的所有学生的学号,姓名和平均成绩
mysql> select student.s_no 学号,s_name 姓名,avg(score) 平均成绩 -> from student,sc -> where student.s_no=sc.s_no -> group by student.s_no,s_name -> having avg(score)>85;
28、查询课程名称为“数据库”且分数低于60的学生姓名和分数
mysql> select s_name 学生姓名,score 分数 -> from student,sc,course -> where student.s_no=sc.s_no and sc.c_no=course.c_no -> and c_name=’数据库’ -> and score<60;
29、查询所有学生的选课情况
mysql> select student.s_no 学号,student.s_name 姓名,group_concat(c_no) 所选课程ID -> from student,sc -> where student.s_no=sc.s_no -> group by student.s_no,student.s_name;
30、查询任何一门课程成绩在90分以上的姓名、课程名称和分数。
mysql> select s_name 姓名,c_name 课程名称,score 分数 -> from student,sc,course -> where student.s_no=sc.s_no and sc.c_no=course.c_no -> and score > 90 -> order by s_name;
31、查询不及格的课程,并按课程号从大到小排序。
mysql> select s_no 学生ID,c_no 不及格课程ID -> from sc -> where score<60 -> order by c_no desc;
32、求选修了课程的学生人数。
mysql> select count(*) 已选课程人数 -> from -> ( -> select distinct(sc.s_no) from student -> left join sc -> on sc.s_no=student.s_no -> where c_no is not null -> ) as ayixuan;
33、查询选修了“冯老师”所授课程的学生中,成绩最高的学生姓名及其成绩。
mysql> select s_name 学生姓名,score 成绩 -> from student,sc,course,teacher -> where student.s_no=sc.s_no and sc.c_no=course.c_no and course.t_no=teacher.t_no -> and t_name=’冯老师’ -> order by score -> limit 1;
34、查询各个课程及相应的选修人数。
mysql> select course.c_no 课程ID,course.c_name 课程名,count(s_no) 选修人数 -> from course -> join sc -> on course.c_no=sc.c_no -> group by course.c_no,course.c_name;
35、查询不同课程成绩相同的学生的学号、课程号、学生成绩。
mysql> select a.s_no 学号,group_concat(a.c_no) 课程号,a.score 学生成绩 -> from sc a,sc b -> where a.score=b.score and a.c_no<>b.c_no -> group by a.s_no,a.score;
36、查询每门课程最好的前两名。
mysql> select a.s_no,a.c_no,a.score -> from sc a -> where -> (select count(distinct score) from sc b where b.c_no=a.c_no and b.score>=a.score)<=2 -> order by a.c_no,a.score desc;
37、检索至少选修两门课程的学生学号。
mysql> select s_no 学生学号 -> from sc -> group by s_no -> having count(*)>=2;
38、查询全部学生都选修的课程的课程号和课程名。
mysql> select course.c_no 课程号,c_name 课程名 -> from course -> join sc on course.c_no=sc.c_no -> join ( -> select c_no,count(s_no) from sc group by c_no -> having count(s_no)=(select count(*) from student)) as a -> on course.c_no=a.c_no;
39、查询没有学过“叶平”老师讲授的任一门课程的学号姓名。
mysql> select student.s_no 学号,student.s_name 姓名 -> from student -> join sc -> on sc.s_no=student.s_no -> where sc.s_no not in -> ( -> select s_no -> from course,teacher,sc -> where course.t_no=teacher.t_no and sc.c_no=course.c_no -> and teacher.t_name=’叶平’ -> );
40、查询两门以上不及格课程的同学的学号及其平均成绩。
mysql> select s_no 学号,avg(score) 平均成绩 -> from sc -> where s_no in ( -> select s_no from sc -> where score<60 -> group by s_no -> having count(*)>2) -> group by s_no;
四、根据表1和表2的信息写出SQL
表1:books书表b
| 主码 | 列标题 | 列名 | 数据类型 | 宽度 | 小数位数 | 是否空值 |
| :- | :—- | :——– | :—— | :- | :— | :— |
| P | 书号 | TNO | char | 15 | no |
| 书名 | TNAME | varchar | 50 | no |
| 作者姓名 | TAUTHOR | varchar | 8 | no |
| 出版社编号 | CNO | char | 5 | yes |
| 书类 | TCATEGORY | varchar | 20 | yes |
| 价格 | TPRICE | numeric | 8 | 2 | yes |
表2:book_concern出版社表C
| 主码 | 列标题 | 列名 | 数据类型 | 宽度 | 小数位数 | 是否空值 |
| :- | :—- | :—– | :—— | :- | :— | :— |
| p | 出版社编号 | CNO | char | 5 | NO |
| 出版社名称 | CNAME | varchar | 20 | NO |
| 出版社电话 | CPHONE | varchar | 15 | YES |
| 出版社城市 | CCITY | varchar | 20 | YES |
1、查询出版过“计算机”类图书的出版社编号(若一个出版社出版过多部“计算机”类图书,则在查询结果中该出版社编号只显示一次)
mysql> select distinct cno 出版社编号 -> from books -> where tcategory=’计算机’;
2、查询南开大学出版社的“经济”类或“数学”类图书的信息。
mysql> select * -> from books,book_concern -> where books.cno=book_concern.cno -> and cname=’南开大学出版社’ -> and tcategory in (‘数学’,’经济’);
3、查询编号为“20001”的出版社出版图书的平均价格。
mysql> select cno 出版社编号,avg(tprice) 图书均价 -> from books -> where cno=’20001’;
4、查询至少出版过20套图书的出版社,在查询结果中按出版社编号的升序顺序显示满足条件的出版社编号、出版社名称和每个出版社出版的图书套数。
mysql> select b.cno 出版社编号,cname 出版社名称,count(*) 图书套数 -> from books b,book_concern c -> where b.cno=c.cno -> group by b.cno,cname -> having count(*)>20 -> order by b.cno;
5、查询比编号为“20001”的出版社出版图书套数多的出版社编号。
mysql> select cno 出版社编号 -> from books -> group by cno -> having count(*)>(select count(*) from books where cno=’20001’);
五、一道关于group by的经典面试题:
有一张shop表如下,有三个字段article、author、price,选出每个author的price最高的记录(要包含所有字段)。
| mysql> select * from shop; +———+——–+——-+ | article | author | price | +———+——–+——-+ | 0001 | B | 9.95 | 0002 | A | 10.99 | 0003 | C | 1.69 | 0004 | B | 19.95 | 0005 | A | 6.96 | +———+——–+——-+ 5 rows in set (0.02 sec) |
1、使用相关子查询
mysql> select article,author,price -> from shop s1 -> where price = ( -> select max(s2.price) -> from shop s2 -> where s1.author=s2.author);
2、使用非相关子查询
mysql> select article,s1.author,s1.price -> from shop s1 -> join ( -> select author,max(price) price -> from shop -> group by author) s2 -> on s1.author=s2.author and s1.price=s2.price;
3、使用left join语句(毕竟子查询在有些时候,效率会很低)
mysql> select s1.article,s1.author,s1.price -> from shop s1 -> left join shop s2 -> on s1.author=s2.author and s1.price<s2.price -> where s2.article is null;
原理分析:当s1.price是当前author的最大值时,就没有s2.price比它还要大,所以此时s2的rows的值都会是null。
六、用一条SQL语句查询出每门课都大于80分的学生
| name | kecheng | fenshu |
| :— | :—— | :—– |
| 张三 | 语文 | 81 |
| 张三 | 数学 | 75 |
| 李四 | 语文 | 76 |
| 李四 | 数学 | 90 |
| 王五 | 语文 | 81 |
| 王五 | 数学 | 100 |
| 王五 | 英语 | 90 |
mysql> select a.name 姓名 -> from -> (select name,count(*) anum from NO_6 where fenshu>80 group by name) a, -> (select name,count(*) bnum from NO_6 group by name) b -> where a.name=b.name -> and a.anum=b.bnum;
七、怎么把这样一个表
| Year | month | amount |
| :— | :—- | :—– |
| 1991 | 1 | 1.1 |
| 1991 | 2 | 1.2 |
| 1991 | 3 | 1.3 |
| 1991 | 4 | 1.4 |
| 1992 | 1 | 2.1 |
| 1992 | 2 | 2.2 |
| 1992 | 3 | 2.3 |
| 1992 | 4 | 2.4 |
查成这样一个结果
| year | M1 | M2 | M3 | M4 |
| :— | :– | :– | :– | :– |
| 1991 | 1.1 | 1.2 | 1.3 | 1.4 |
| 1992 | 2.1 | 2.2 | 2.3 | 2.4 |
mysql> select year, -> sum(if(month=1,amount,0)) M1, -> sum(if(month=2,amount,0)) M2, -> sum(if(month=3,amount,0)) M3, -> sum(if(month=4,amount,0)) M4 -> from NO_7 -> group by year;
八、已知表A =login_ftp记录着登录FTP服务器的计算机IP、时间等字段信息
请写出SQL查询表A中存在ID重复三次以上的记录。
mysql> select IP from login_ftp -> group by IP -> having count(*)>3;
九、创建存储过程,要求具有游标(遍历表)示例
CREATE PROCEDURE curdemo() BEGIN DECLARE done INT DEFAULT FALSE; DECLARE a CHAR(16); DECLARE b, c INT; DECLARE cur1 CURSOR FOR SELECT id,data FROM test.t1; DECLARE cur2 CURSOR FOR SELECT i FROM test.t2; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE; OPEN cur1; OPEN cur2; read_loop: LOOP FETCH cur1 INTO a, b; FETCH cur2 INTO c; IF done THEN LEAVE read_loop; END IF; IF b < c THEN INSERT INTO test.t3 VALUES (a,b); ELSE INSERT INTO test.t3 VALUES (a,c); END IF; END LOOP; CLOSE cur1; CLOSE cur2; END;
Postgresql
PGPool
执行计划
PostgreSQL为每个收到查询产生一个查询计划。 选择正确的计划来匹配查询结构和数据的属性对于好的性能来说绝对是最关键的,因此系统包含了一个复杂的规划器来尝试选择好的计划。 你可以使用EXPLAIN命令察看规划器为任何查询生成的查询计划。
执行计划命令
EXPLAIN [ ( option [, …] ) ] statement\
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
这里 option可以是:\
ANALYZE [ boolean ]\
VERBOSE [ boolean ]\
COSTS [ boolean ]\
BUFFERS [ boolean ]\
TIMING [ boolean ]\
SUMMARY [ boolean ]\
| FORMAT { TEXT | XML | JSON | YAML } |
ANALYZE,执行命令并且显示实际的运行时间和其他统计信息。这个参数默认被设置为FALSE。\
VERBOSE,显示关于计划的额外信息。特别是:计划树中每个结点的输出列列表、模式限定的表和函数名、总是把表达式中的变量标上它们的范围表别名,以及总是打印统计信息被显示的每个触发器的名称。这个参数默认被设置为FALSE。\
COSTS,包括每一个计划结点的估计启动和总代价,以及估计的行数和每行的宽度。这个参数默认被设置为TRUE。\
BUFFERS,包括缓冲区使用的信息。特别是:共享块命中、读取、标记为脏和写入的次数、本地块命中、读取、标记为脏和写入的次数、以及临时块读取和写入的次数。只有当ANALYZE也被启用时,这个参数才能使用。它的默认被设置为FALSE。\
TIMING,在输出中包括实际启动时间以及在每个结点中花掉的时间。只有当ANALYZE也被启用时,这个参数才能使用。它的默认被设置为TRUE。\
SUMMARY,在查询计划之后包含摘要信息(例如,总计的时间信息)。当使用ANALYZE 时默认包含摘要信息,但默认情况下不包含摘要信息,但可以使用此选项启用摘要信息。 使用EXPLAIN EXECUTE中的计划时间包括从缓存中获取计划所需的时间 以及重新计划所需的时间(如有必要)。\
FORMAT,指定输出格式,可以是 TEXT、XML、JSON 或者 YAML。非文本输出包含和文本输出格式相同的信息,但是更容易被程序解析。这个参数默认被设置为TEXT。\
statement,你想查看其执行计划的任何SELECT、INSERT、UPDATE、DELETE、VALUES、EXECUTE、DECLARE、CREATE TABLE AS或者CREATE MATERIALIZED VIEW AS语句。
常用组合
- 一般查询
--在不需要真正执行sql时,需把analyze去掉
explain analyze select … ;
- 查询缓存及详细信息
--在不需要真正执行sql时,需把analyze去掉
explain (analyze,verbose,buffers) select … ;
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
执行计划解读
db_test=# explain (analyze,verbose,buffers) select * from db_test.t_test;\
QUERY PLAN\
-—————————————————————————————————————-\
Seq Scan on db_test.t_test(cost=0.00..22.32 rows=1032 width=56) (actual time=0.060..1.167 rows=1032 loops=1)\
Output: c_bh, n_dm, c_ah\
Buffers: shared read=12\
Planning Time: 0.283 ms\
Execution Time: 1.730 ms
解读
cost=0.00..22.32,0.00代表启动成本,22.32代表返回所有数据的成本。\
rows=1032:表示返回多少行。\
width=56,表示每行平均宽度。\
actual time=0.060..1.167,实际花费的时间。\
loops=1,循环的次数\
Output,输出的字段名\
Buffers,缓冲命中数\
shared read,代表数据来自disk(磁盘)而并非cache(缓存),当再次执行sql,会发现变成shared hit,说明数据已经在cache中\
Planning Time,生成执行计划的时间\
Execution Time,执行执行计划的时间
####
PostgreSQL中数据扫描方式很多,常见有如下几种
1、seq scan
顺序扫描
db_test=# explain (analyze,verbose,buffers) select * from db_test.t_ms_aj;\
QUERY PLAN\
-—————————————————————————————————————-\
Seq Scan on db_test.t_ms_aj (cost=0.00..22.32 rows=1032 width=56) (actual time=0.060..1.167 rows=1032 loops=1)\
Output: c_bh, n_dm, c_ah\
Buffers: shared hit=12\
Planning Time: 0.283 ms\
Execution Time: 1.730 ms
2、Index Only Scan
按索引顺序扫描,通过VM减少回表,绝大数情况下不需要回表。
db_test=# explain (analyze,verbose,buffers) select c_bh from db_test.t_ms_aj where c_bh=’db22f5a4f828d0f4eaa0b70679a4d637’;\
QUERY PLAN\
-———————————————————————————————————————————–\
Index Only Scan using t_ms_aj_pkey on db_test.t_ms_aj (cost=0.28..8.29 rows=1 width=33) (actual time=0.079..0.081 rows=1 loops=1)\
Output: c_bh\
Index Cond: (t_ms_aj.c_bh = ‘db22f5a4f828d0f4eaa0b70679a4d637’::bpchar)\
Heap Fetches: 1\
Buffers: shared hit=3\
Planning Time: 0.139 ms\
Execution Time: 0.166 ms
3、Index Scan
按索引顺序扫描,并回表。
db_test=# explain (analyze,buffers) select * from db_test.t_ms_aj where c_bh=’db22f5a4f828d0f4eaa0b70679a4d637’;\
QUERY PLAN\
-———————————————————————————————————————-\
Index Scan using t_ms_aj_pkey on t_ms_aj (cost=0.28..8.29 rows=1 width=56) (actual time=0.890..0.894 rows=1 loops=1)\
Index Cond: (c_bh = ‘db22f5a4f828d0f4eaa0b70679a4d637’::bpchar)\
Buffers: shared hit=3\
Planning Time: 0.376 ms\
Execution Time: 1.136 ms
4、Bitmap Index Scan+Bitmap Heap Scan
按索引取得的BLOCKID排序,然后根据BLOCKID顺序回表扫描,然后再根据条件过滤掉不符合条件的记录。这种扫描方法,主要解决了离散数据(索引字段的逻辑顺序与记录的实际存储顺序非常离散的情况),需要大量离散回表扫描的情况
db_test=# explain (analyze,verbose,buffers) select * from db_test.t_ms_aj_bak where n_dm=12;\
QUERY PLAN\
-———————————————————————————————————————————-\
Bitmap Heap Scan on db_test.t_ms_aj_bak (cost=100.85..1303.26 rows=5233 width=56) (actual time=1.477..107.896 rows=5204 loops=1)\
Output: c_bh, n_dm, c_ah\
Recheck Cond: (t_ms_aj_bak.n_dm = 12)\
Heap Blocks: exact=1125\
Buffers: shared hit=1126 read=15\
-> Bitmap Index Scan on i_ms_aj_bak_n_dm (cost=0.00..99.54 rows=5233 width=0) (actual time=1.260..1.260 rows=5204 loops=1)\
Index Cond: (t_ms_aj_bak.n_dm = 12)\
Buffers: shared hit=1 read=15\
Planning Time: 0.114 ms\
Execution Time: 109.361 ms
5、Hash join
哈希JOIN
db_test=# explain (analyze,verbose,buffers) select aj.c_bh from db_test.t_ms_aj aj join db_test.t_ms_dsr dsr on dsr.c_bh_aj=aj.c_bh;\
QUERY PLAN\
-———————————————————————————————————————————–\
Hash Join (cost=35.22..5378.59 rows=2307 width=33) (actual time=3.121..1254.234 rows=2074 loops=1)\
Output: aj.c_bh\
Inner Unique: true\
Hash Cond: (dsr.c_bh_aj = aj.c_bh)\
Buffers: shared hit=2828\
-> Seq Scan on db_test.t_ms_dsr dsr (cost=0.00..4817.86 rows=200186 width=33) (actual time=0.013..598.660 rows=200186 loops=1)\
Output: dsr.c_bh, dsr.c_bh_aj, dsr.c_name\
Buffers: shared hit=2816\
-> Hash (cost=22.32..22.32 rows=1032 width=33) (actual time=3.089..3.089 rows=1032 loops=1)\
Output: aj.c_bh\
Buckets: 2048 Batches: 1 Memory Usage: 82kB\
Buffers: shared hit=12\
-> Seq Scan on db_test.t_ms_aj aj (cost=0.00..22.32 rows=1032 width=33) (actual time=0.010..1.860 rows=1032 loops=1)\
Output: aj.c_bh\
Buffers: shared hit=12\
Planning Time: 0.396 ms\
Execution Time: 1257.348 ms
6、Nested Loop
嵌套循环。其中一个表扫描一次,另一个表则循环多次。
db_test=# explain analyze select aj.c_bh from db_test.t_ms_aj aj join db_test.t_ms_dsr dsr on dsr.c_bh_aj=aj.c_bh where aj.n_dm=20;\
QUERY PLAN\
-—————————————————————————————————————————-\
Nested Loop (cost=8.87..263.50 rows=45 width=33) (actual time=0.058..0.405 rows=37 loops=1)\
-> Bitmap Heap Scan on t_ms_aj aj (cost=4.43..17.09 rows=20 width=33) (actual time=0.028..0.067 rows=20 loops=1)\
Recheck Cond: (n_dm = 20)\
Heap Blocks: exact=10\
-> Bitmap Index Scan on i_ms_aj_n_dm (cost=0.00..4.43 rows=20 width=0) (actual time=0.018..0.019 rows=20 loops=1)\
Index Cond: (n_dm = 20)\
-> Bitmap Heap Scan on t_ms_dsr dsr (cost=4.44..12.30 rows=2 width=33) (actual time=0.014..0.015 rows=2 loops=20)\
Recheck Cond: (c_bh_aj = aj.c_bh)\
Heap Blocks: exact=20\
-> Bitmap Index Scan on i_ms_dsr_c_bh (cost=0.00..4.43 rows=2 width=0) (actual time=0.011..0.011 rows=2 loops=20)\
Index Cond: (c_bh_aj = aj.c_bh)\
Planning Time: 0.409 ms\
Execution Time: 0.555 ms
7、Merge Join
需要两个JOIN的表的KEY都是先排好顺序的,如果有索引没有排序过程。Merge Join两个表都只扫描一次。
db_test=# explain analyze select aj.c_bh from db_test.t_ms_aj aj join db_test.t_ms_dsr dsr on dsr.c_bh=aj.c_ah;\
QUERY PLAN\
-————————————————————————————————————————————————\
Gather (cost=14985.80..15689.01 rows=1032 width=33) (actual time=944.856..951.963 rows=0 loops=1)\
Workers Planned: 1\
Workers Launched: 1\
-> Merge Join (cost=13985.80..14585.81 rows=607 width=33) (actual time=851.573..851.573 rows=0 loops=2)\
Merge Cond: (dsr.c_bh = (aj.c_ah)::bpchar)\
-> Sort (cost=13911.82..14206.21 rows=117756 width=33) (actual time=747.508..792.472 rows=100093 loops=2)\
Sort Key: dsr.c_bh\
Sort Method: quicksort Memory: 11282kB\
Worker 0: Sort Method: quicksort Memory: 10503kB\
-> Parallel Seq Scan on t_ms_dsr dsr (cost=0.00..3993.56 rows=117756 width=33) (actual time=0.035..115.401 rows=100093 loops=2)\
-> Sort (cost=73.98..76.56 rows=1032 width=52) (actual time=2.963..3.154 rows=338 loops=2)\
Sort Key: aj.c_ah USING <\
Sort Method: quicksort Memory: 194kB\
Worker 0: Sort Method: quicksort Memory: 194kB\
-> Seq Scan on t_ms_aj aj (cost=0.00..22.32 rows=1032 width=52) (actual time=0.082..0.545 rows=1032 loops=2)\
Planning Time: 0.481 ms\
Execution Time: 952.152 ms
五、示例
1、我们先看sql,根据现场反馈修改其他c_dbbh后,sql执行较快,唯独这一个c_dbbh需要一分钟才会出结果
SELECT COUNT(1)\
FROM db_test.t_zh_axx aj\
LEFT JOIN (SELECT n_ccsl,c_ajbh,c_zblx,c_laay FROM db_test.t_zh_zjxx A\
WHERE\
c_bh = (SELECT c_bh FROM db_test.t_zh_zjxx b WHERE b.c_ajbh = A.c_ajbh AND b.c_zblx = ‘0050002’ ORDER BY dt_cjsj DESC NULLS LAST LIMIT 1)\
) zb ON zb.c_ajbh = aj.c_ajbh\
WHERE\
c_dbbh = ‘0191H4325678D8172F58EE383720D0A9’\
AND zb.c_zblx = ‘0050002’\
AND aj.c_zy = ‘1628’\
--涉及表的数据量\
--db_test.t_zh_axx 1200万+\
--db_test.t_zh_zjxx 1900万+
2、先看执行计划为什么慢,在进行sql优化。
Aggregate (cost=3214.11..3214.12 rows=1 width=8) (actual time=61097.734..61097.734 rows=1 loops=1)\
-> Nested Loop (cost=743.92..3214.11 rows=1 width=0) (actual time=8.702..61097.110 rows=1461 loops=1)\
-> Bitmap Heap Scan on t_zh_axx aj (cost=743.36..763.39 rows=5 width=17) (actual time=8.585..11.327 rows=1461 loops=1)\
Recheck Cond:((c_dbbh = ‘0191H4325678D8172F58EE383720D0A9’::bpchar) AND ((c_zy)::text = ‘1801’::text))\
Heap Blocks:exact=720\
-> BitmapAnd (cost=743.36..743.36 rows=5 width=0)(actual time=8.479..8.479 rows=0 loops=1)\
-> Bitmap Index Scan on i_t_zh_axx_c_dbbh_c_cbfy (cost=0.00..70.63 rows=1343 width=0)(actual time=0.766..0.766 rows=0 loops=1)\
Index Cond:(c_dbbh = ‘0191H4325678D8172F58EE383720D0A9’::bpchar)\
-> Bitmap Index Scan on i_t_zh_axx_zblx_c_zy (cost=0.00..672.47 rows=36272 width=0)(actual time=7.644..7.644 rows=0 loops=1)\
Index Cond:((c_zy)::text = ‘1628’::text)\
-> Index Scan using i_t_zh_zjxx_c_ajbh on t_zh_zjxx a (cost=0.56..190.13 rows=1 width=16) (actual time=20.069..41.822 rows=1 loops=1461)\
Index Cond: ((c_ajbh)::text = (aj.c_ajbh)::text)\
Filter: (((c_zblx)::text = ‘0020002’::text) AND (c_bh = (SubPlan 1)))\
Rows Removed by Filter: 167\
SubPlan 1\
-> Limit (cost=44.55..44.56 rows=1 width=41) (actual time=0.247..0.248 rows=1 loops=245603)\
-> Sort (cost=44.55..44.56 rows=1 width=41) (actual time=0.247..0.247 rows=1 loops=245603)\
Sort Key: b.dt_cjsj DESC NULLS LAST\
Sort Method: top-N heapsort Memory: 25kB\
-> Index Scan using i_t_zh_zjxx_c_ajbh on t_zh_zjxx b (cost=0.56..54.82 rows=1 width=41) (actual time=0.017..0.071 rows=38 loops=245603)\
Index Cond: ((c_ajbh)::text = (a.c_ajbh)::text)\
Filter: ((c_zblx)::text = ‘0020002’::text)\
Rows Removed by Filter: 114\
Planning Time: 1.267 ms\
Execution Time: 61097.876 ms
分析
仔细观察执行计划后发现,占用时间最多的在第2行Nested Loop(actual time=8.702…61097.110),嵌套循环占用了一分钟,然后在16 -> 20行看到(loops=245603),循环了24.5万次。\
上篇文章可以了解到嵌套循环:其中一个表扫描一次,另一个表则循环多次。这里基本可以确定问题了,找开发确认发现是确实是数据问题,原因是重复上报导致。
3、改写sql
--用exists改写\
explain analyze\
select count(*) from db_test.t_zh_axx aj\
where exists (select 1 from db_test.t_zh_zjxx zbajxx where zbajxx.c_ajbh=aj.c_ajbh and c_zblx = ‘0020002’)\
and aj.c_dbbh = ‘8B7D8C93864E0D0C3E3259C49ED65471’\
AND aj.c_zy = ‘1801’
--执行计划都走索引\
--值得关注的是join的方式是Nested Loop Semi Join,多了个Semi。Semi Join支持支持hash, merge, nestloop几种JOIN方法\
--semi Join的操作在EXISTS中有一个返回TRUE的操作即可,所以在有索引的情况下很大概率下并不需要全表扫描\
QUERY PLAN\
-——————————————————————————————————————————————————————-\
Aggregate (cost=5560.83..5560.84 rows=1 width=8) (actual time=38.158..38.158 rows=1 loops=1)\
-> Nested Loop Semi Join, (cost=1.12..5560.82 rows=6 width=0) (actual time=0.072..37.912 rows=1356 loops=1)\
-> Index Scan using t_zh_axx_c_dbbh_idx on t_zh_axx aj (cost=0.56..5210.98 rows=6 width=17) (actual time=0.042..1.315 rows=1461 loops=1)\
Index Cond: (c_dbbh = ‘8B7D8C93864E0D0C3E3259C49ED65471’::bpchar)\
Filter: ((c_zy)::text = ‘1801’::text)\
-> Index Scan using i_t_zh_zjxx_c_ajbh on t_zh_zjxx zbajxx (cost=0.56..58.50 rows=1 width=16) (actual time=0.024..0.024 rows=1 loops=1461)\
Index Cond: ((c_ajbh)::text = (aj.c_ajbh)::text)\
Filter: ((c_zblx)::text = ‘0020002’::text)\
Planning Time: 0.852 ms\
Execution Time: 38.255 ms
NoSQL
键值数据库
Redis
BerkeleyDB
Memcached
Project Voldemort
Riak
LevelDB
文档数据库
MongoDB
CouchDB
RavenDB
Terrastore
OrientDB
列族数据库
HBase
Amazon SimpleDB
Cassdndra
Hypertable
BigTable(google)
图数据库
FlockDB
HyperGraphDB
Infinite Graph
Neo4J
OrientDB
LiteD
LiteDB是一个小型的.NET平台开源的NoSQL类型的轻量级文件数据库。特点是小和快,dll文件只有200K大小,而且支持LINQ和命令行操作,数据库是一个单一文件,类似Sqlite。官方网站:http://www.litedb.org/
特点
1.NoSQL文件存储。这是和传统关系型数据库的主要区别;支持实体类的字段更新;
2.类似MongoDB的简单API;
3.完全使用C#代码,在.NET 4.0环境下编写,核心dll小巧,只有168K;
4.支持ACID事务处理;
5.可以进行写入失败的恢复;
6.存储到文件或者数据流中(类似MongoDB的GridFS);
7.类似Sqlite的单一文件存储;
8.支持文件索引,可以进行快速搜索;可以直接存储文件;
9.支持Linq查询;【这也许是C#编写最直接的好处】;
10.支持命令行操作数据库,官方提供了一个Shell command line;
11.完全开源和免费,包括商业使用;
Serverless NoSQL 文档存储
类似于 MongoDB 的简单 API
100% C# 代码,支持.NET 3.5 / .NET 4.0 / NETStandard 1.3 / NETStandard 2.0,单 DLL (小于 300kb)
支持线程和进程安全
支持文档/操作级别的 ACID
支持写失败后的数据还原 (日志模式)
可使用 DES (AES) 加密算法进行数据文件加密
可使用特性或 fluent 映射 API 将你的 POCO类映射为 BsonDocument
可存储文件与流数据 (类似 MongoDB 的 GridFS)
单数据文件存储 (类似 SQLite)
支持基于文档字段索引的快速搜索 (每个集合支持多达16个索引)
支持 LINQ 查询
Shell 命令行 - 试试这个在线版本
相当快 - 这里是与 SQLite 的对比结果
开源,对所有人免费 - 包括商业应用
LiteDB使用基本案例
创建实体类
public class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string[] Phones { get; set; }
public bool IsActive { get; set; }
}
使用Demo
使用过程首先要添加dll应用,以及引入命名空间:
using LiteDB;
下面是测试代码,会在当前目录下创建一个sample.db的数据库文件:
//打开或者创建新的数据库
using (var db = new LiteDatabase(“sample.db”))
{
//获取 customers 集合,如果没有会创建,相当于表
var col = db.GetCollection
//创建 customers 实例
var customer = new Customer
{
Name = “John Doe”,
Phones = new string[] { “8000-0000”, “9000-0000” },
IsActive = true
};
// 将新的对象插入到数据表中,Id是自增,自动生成的
col.Insert(customer);
// 更新实例
customer.Name = “Joana Doe”;
//保存到数据库
col.Update(customer);
// 使用对象的属性,这个方法生成索引,来进行检索
col.EnsureIndex(x => x.Name);
//使用LINQ语法来检索
var results = col.Find(x => x.Name.StartsWith(“Jo”));
}
上述过程很清楚,根据注释理解几乎不用费神。
使用场景
1.桌面或者本地小型的应用程序
2.小型web应用程序
3.单个数据库账户或者单个用户数据的存储
4.少量用户的并发写操作的应用程序
LiteDB的技术细节
LiteDB的工作原理
LiteDB是虽然单个文件类型的数据库,但是数据库有很多信息,例如索引,集合,文件等。为了管理这些信息,LiteDB实现了数据库页的概念。
页 是一个拥有4096 字节的 存储相同信息的地址块。也是操作磁盘文件(读写)的最小单元。LiteDB有6种页类型。其作用也不一样,分布是:Header Page,Collection Page,Index Page, Data Page,Extend Page,Empty Page。
Data Page的作用是存储核心的数据,是以序列化后的BSON格式来存储。
值得注意的是,如果存储的数据太大,超过page大小,数据块就会使用一个指针指向Extend Page。
在上面的代码中,我们初始化数据库是这样的:
var db = new LiteDatabase(“MyData.db”);
这种情况比较好用,可以打开或者创建新的数据库,同样也可以使用连接名称来获取,例如:
var db = new LiteDatabase(“userdb”);
这样会直接从connectionStrings找到这个名称的连接。包括了文件名称,使用模式,以及版本信息。一般情况下直接使用第一种即可。LiteDB的数据库连接完整形式是:filename=C:\Path\mydb.db; journal=false; version=5
LiteDB的查询
LiteDB的查询必须在相关的查询字段上使用索引,如果没有索引,会默认去创建索引。上面例子中就是创建字段的索引,并查询。LiteDB中查询有2种方法:
1.使用静态的帮助类Query;
2.使用Linq方式,就是类似Demo的方法;
LiteDB使用Query的查询方式有以下一些方法,详细讲解几个重要的,其他几个大家理解一下,也应该不难,如果有不准确的地方,还请指正:
Query.All 返回所有的数据,可以使用指定的索引字段进行排序
Query.EQ 查找返回和指定字段值相等的数据
Query.LT/LTE 查找< 或 <= 某个值的数据
Query.GT/GTE 查找> 或 >= 某个值的数据
Query.Between 查找在指定区间范围内的数据
Query.In - 和SQL的in类似吧,查找和列表中值相等的数据
Query.Not - 和EQ相反,是不等于某个值的数据
Query.StartsWith 查找以某个字符串开头的数据
Query.Contains 查找保护某个字符串的数据,这个查询只扫描索引
Query.And 2个查询的交集
Query.Or 2个查询结果的并集
var results = collection.Find(Query.EQ(“Name”, “John Doe”));
var results = collection.Find(Query.GTE(“Age”, 25));
var results = collection.Find(Query.And(
Query.EQ(“FirstName”, “John”), Query.EQ(“LastName”, “Doe”)
));
var results = collection.Find(Query.StartsWith(“Name”, “Jo”));
注意LiteDB不支持这种表达式:CreationDate == DueDate。
下面介绍使用Linq的查询的几个主要方法:
FindAll: 查找表或者集合中所有的结果记录
FindOne:返回第一个或者默认的结果
FindById: 通过索引返回单个结果
Find: 使用查询表达式或者linq表达式查询返回结果
collection.EnsureIndex(x => x.Name);
var result = collection
.Find(Query.EQ(“Name”, “John Doe”))
.Where(x => x.CreationDate >= x.DueDate.AddDays(-5))
.OrderBy(x => x.Age)
.Select(x => new
{
FullName = x.FirstName + “ “ + x.LastName,
DueDays = x.DueDate - x.CreationDate
});
当然还有一些方法如:Count() , Exists(),Min() , Max()等方法。。比较好理解。看看linq表达式的查询案例:
var collection = db.GetCollection
var results = collection.Find(x => x.Name == “John Doe”);
var results = collection.Find(x => x.Age > 30);
var results = collection.Find(x => x.Name.StartsWith(“John”) && x.Age > 30);
LiteDB的查询示例
namespace DEVGIS.OutTest.Views
{
/// <summary>
/// SelectDevices.xaml 的交互逻辑
/// </summary>
public partial class TestLiteDB
{
public TestLiteDB() : base(“”)
{
InitializeComponent();
this.Loaded += TestLiteDB_Loaded;
}
private void TestLiteDB_Loaded(object sender, RoutedEventArgs e)
{
InitDB();
}
public void InitDB()
{
using (var db = new LiteDatabase(“sample.db”))
{
//获取 customers 集合,如果没有会创建,相当于表
var col = db.GetCollection
//创建 customers 实例
var customer = new Customer
{
Name = “John Doe”,
Phones = new string[] { “8000-0000”, “9000-0000” },
IsActive = true
};
// 将新的对象插入到数据表中,Id是自增,自动生成的
col.Insert(customer);
// 更新实例
customer.Name = “Joana Doe”;
//保存到数据库
col.Update(customer);
// 使用对象的属性,这个方法生成索引,来进行检索
col.EnsureIndex(x => x.Name);
//使用LINQ语法来检索
var results = col.Find(x => x.Name.StartsWith(“Jo”));
tbContent.Text = JsonConvert.SerializeObject(results);
}
}
}
}